Large Language Models are Inconsistent and Biased Evaluators
作者: Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
分类: cs.CL, cs.AI
发布日期: 2024-05-02
备注: 9 pages, 7 figures
💡 一句话要点
揭示大语言模型评估器的不一致性和偏见,并提出缓解方案
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 评估器 偏见 不一致性 自然语言处理 文本摘要 模型评估
📋 核心要点
- 现有工作主要关注优化LLM评估器与人类评分的相关性,忽略了其内在的偏见和一致性问题。
- 本文通过实验揭示了LLM评估器存在的熟悉度偏差、评分分布倾斜、锚定效应以及不一致性等问题。
- 论文提出了缓解这些限制的配置方法,并在RoSE数据集上验证了其有效性,超越了现有最佳LLM评估器。
📝 摘要(中文)
大型语言模型(LLM)的零样本能力使其能够为各种任务提供高度灵活、无需参考的指标,从而使LLM评估器成为自然语言处理(NLP)中的常用工具。然而,这些LLM评估器的鲁棒性仍然相对缺乏研究;现有工作主要追求LLM评分与人类专家评分之间的最佳相关性。在本文中,我们使用SummEval数据集进行了一系列分析,证实LLM是有偏见的评估器,因为它们:(1)表现出熟悉度偏差——偏好困惑度较低的文本,(2)显示出倾斜和有偏见的评分分布,以及(3)在多属性判断中经历锚定效应。我们还发现LLM是不一致的评估器,表现出较低的“样本间”一致性,并且对提示差异敏感,而这些差异对人类理解文本质量而言并不重要。此外,我们分享了配置LLM评估器以减轻这些限制的方法。在RoSE数据集上的实验结果表明,相比最先进的LLM评估器,性能有所提高。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)作为评估器时表现出的不一致性和偏见问题。现有方法主要关注LLM评分与人类评分的相关性,忽略了LLM评估器本身可能存在的系统性偏差,这可能导致对模型性能的错误评估。
核心思路:论文的核心思路是通过实验分析揭示LLM评估器存在的具体偏见类型(如熟悉度偏差、评分分布倾斜、锚定效应)和不一致性,然后探索缓解这些问题的方法,从而提高LLM评估器的可靠性和公正性。
技术框架:论文主要采用实验分析的方法。首先,使用SummEval数据集评估LLM评估器的偏见和不一致性。然后,针对发现的问题,提出相应的配置策略来缓解这些限制。最后,在RoSE数据集上验证改进后的LLM评估器的性能。整体流程包括问题识别、问题分析、策略设计和实验验证四个阶段。
关键创新:论文的关键创新在于系统性地研究了LLM评估器的偏见和不一致性问题,并提出了相应的缓解策略。与现有工作主要关注评分相关性不同,本文更关注LLM评估器本身的特性,这有助于更全面地理解和改进LLM评估器。
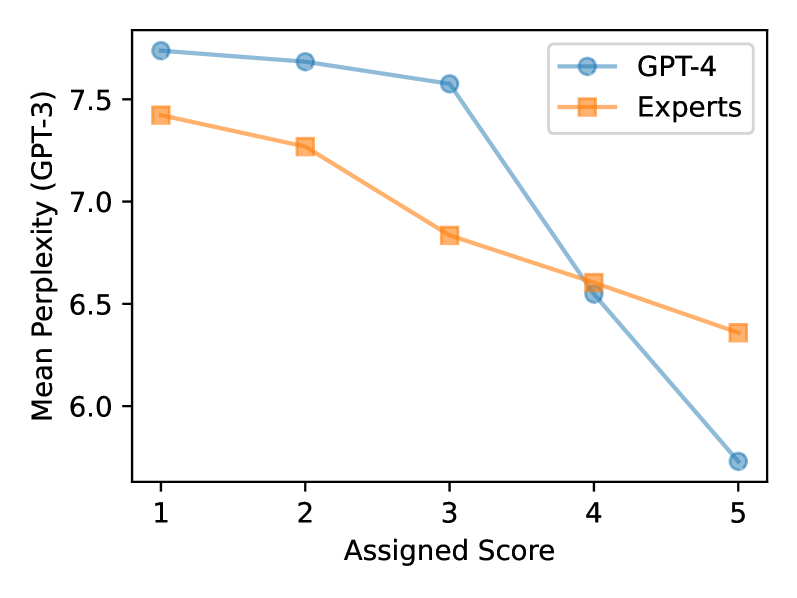
关键设计:论文的关键设计包括:(1) 使用困惑度(perplexity)来衡量文本的熟悉度,并分析LLM评估器对不同困惑度文本的偏好;(2) 分析LLM评估器的评分分布,检测是否存在倾斜或偏差;(3) 通过控制提示顺序来研究锚定效应对LLM评估的影响;(4) 探索不同的提示策略和参数设置,以缓解LLM评估器的偏见和不一致性。具体的参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明,LLM评估器存在显著的偏见和不一致性。通过提出的缓解策略,LLM评估器在RoSE数据集上的性能得到了提升,超越了现有最先进的LLM评估器。具体的性能提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于自然语言处理领域的模型评估,特别是文本摘要、机器翻译等任务。通过消除LLM评估器的偏见和提高其一致性,可以更准确地评估模型性能,从而促进模型开发和改进。此外,该研究也为LLM在其他领域的应用提供了参考,有助于提高LLM应用的可靠性和公正性。
📄 摘要(原文)
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low "inter-sample" agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.