D2PO: Discriminator-Guided DPO with Response Evaluation Models
作者: Prasann Singhal, Nathan Lambert, Scott Niekum, Tanya Goyal, Greg Durrett
分类: cs.CL
发布日期: 2024-05-02 (更新: 2024-08-07)
备注: 20 pages, 12 figures, Accepted to COLM 2024
💡 一句话要点
提出D2PO:一种判别器引导的DPO方法,利用响应评估模型提升在线偏好学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 在线学习 判别器 响应评估模型 银标签数据 语言模型对齐 强化学习
📋 核心要点
- 现有语言模型对齐方法,如DPO,在利用判别器评估响应方面仍有提升空间,尤其是在线学习场景。
- D2PO核心思想是利用收集到的黄金偏好数据训练判别器,生成银标签数据,从而扩充训练数据,提升策略学习效率。
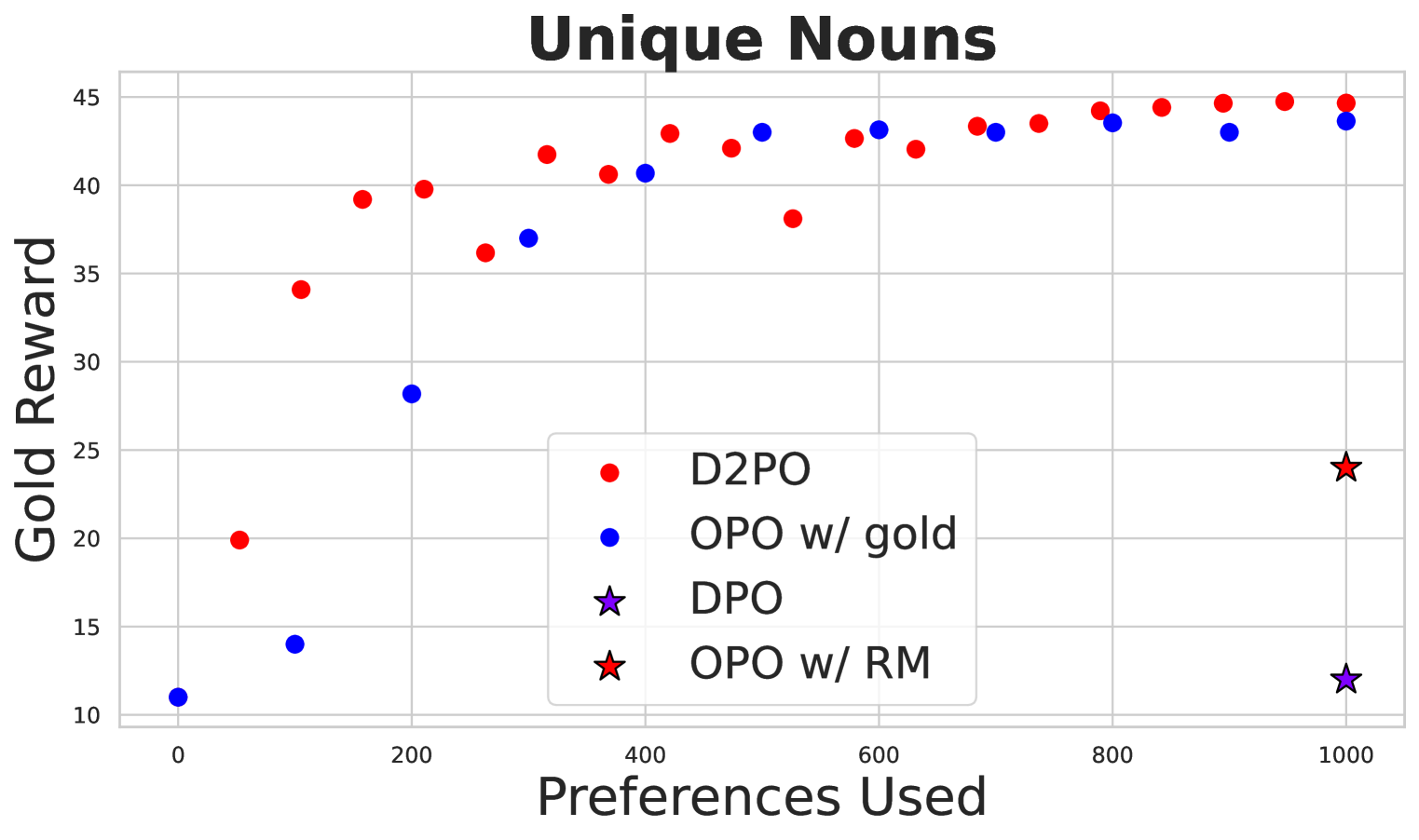
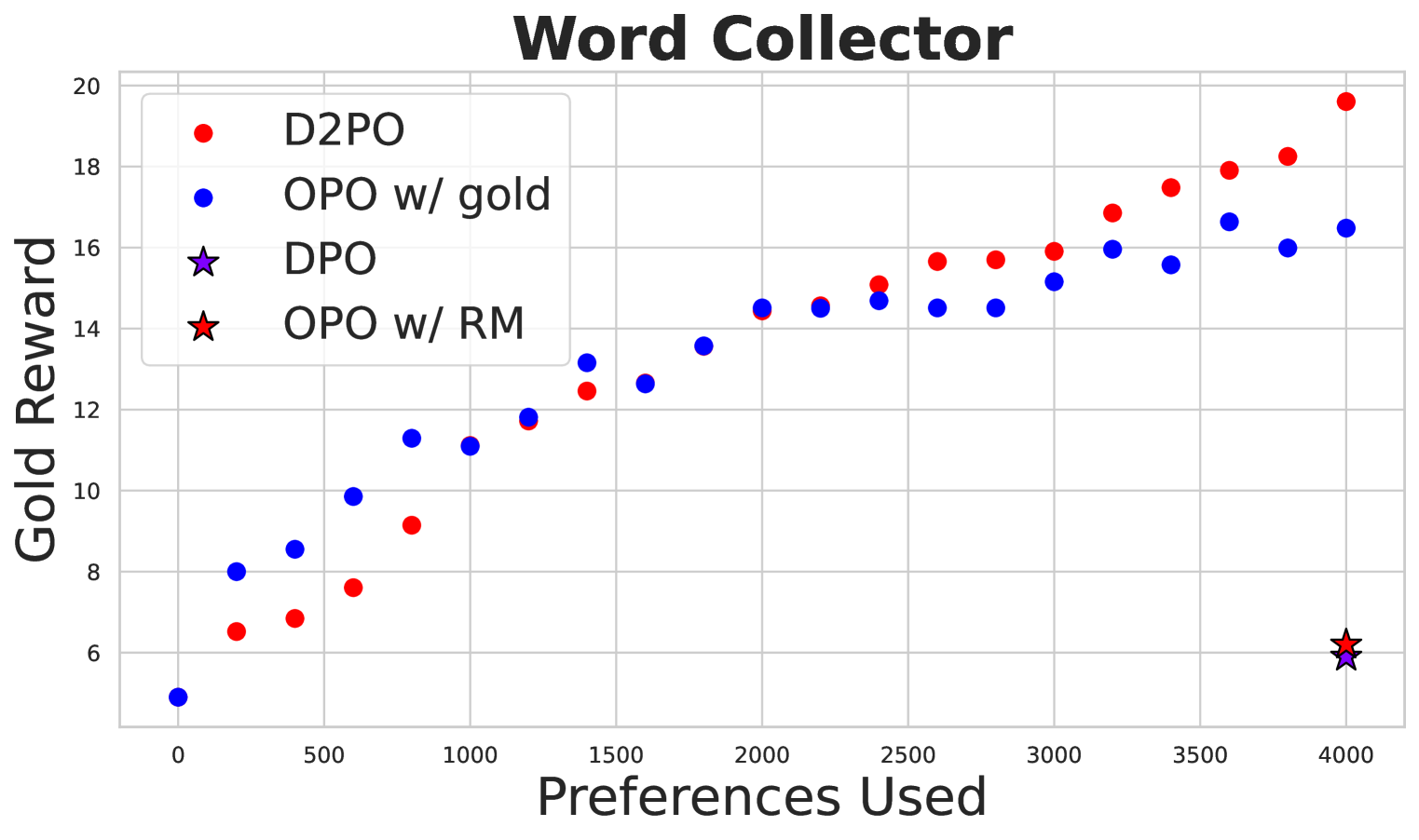
- 实验表明,D2PO在数据利用率和输出质量上优于DPO,尤其在使用DPO训练策略模型时,效果更为显著。
📝 摘要(中文)
本文提出了一种判别器引导的DPO方法,即D2PO,用于在线偏好学习场景。该方法在学习过程中收集黄金偏好数据,并利用这些数据训练策略模型和一个判别式响应评估模型。该评估模型能够为策略训练生成更多的银标签合成数据。通过在多个任务(包括真实的聊天场景)上的实验,结果表明,与使用相同数据预算的DPO相比,D2PO能够产生更高质量的输出,并显著提高偏好数据的利用效率。此外,研究还表明,当使用DPO训练策略时,银标签数据最为有效,并且维持一个与策略模型分离的判别器能够带来更好的性能。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法虽然训练过程简单且效果良好,但在利用判别器(如奖励模型)评估响应方面仍有提升空间。尤其是在在线学习场景下,如何更有效地利用收集到的偏好数据是一个挑战。现有方法可能无法充分利用数据中的信息,导致训练效率低下。
核心思路:D2PO的核心思路是利用收集到的少量黄金偏好数据,训练一个判别式响应评估模型(Discriminator)。该模型能够对未标注的数据进行评估,生成银标签数据,从而扩充训练数据集。通过结合黄金数据和银标签数据,可以更有效地训练策略模型,提高模型的性能和数据利用率。
技术框架:D2PO的整体框架包含以下几个主要步骤:1) 收集少量黄金偏好数据;2) 使用黄金数据训练策略模型和一个独立的判别器;3) 使用训练好的判别器对未标注的数据进行评估,生成银标签数据;4) 将黄金数据和银标签数据结合起来,使用DPO算法训练策略模型。该框架的关键在于判别器的训练和银标签数据的生成,这使得D2PO能够利用更多的数据进行训练。
关键创新:D2PO最重要的创新点在于引入了判别器来生成银标签数据,从而扩充了训练数据集。与传统的DPO方法相比,D2PO能够更有效地利用数据,提高训练效率和模型性能。此外,D2PO还强调了维持一个与策略模型分离的判别器的重要性,这有助于提高判别器的准确性和泛化能力。
关键设计:D2PO的关键设计包括:1) 判别器的网络结构和训练方式;2) 银标签数据的生成策略;3) 黄金数据和银标签数据的比例;4) DPO算法的具体实现。论文可能采用了特定的损失函数来训练判别器,并设计了合适的阈值来筛选高质量的银标签数据。具体的网络结构、损失函数和超参数设置需要在论文中查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,D2PO在多个任务上优于传统的DPO方法。在相同的偏好数据预算下,D2PO能够产生更高质量的输出。此外,研究还发现,当使用DPO训练策略时,银标签数据最为有效,并且维持一个与策略模型分离的判别器能够带来更好的性能。这些结果验证了D2PO的有效性和优越性。
🎯 应用场景
D2PO方法可应用于各种需要在线偏好学习的场景,例如对话系统、推荐系统和内容生成。通过利用判别器生成银标签数据,可以降低对大量人工标注数据的依赖,提高模型的训练效率和性能。该方法在资源有限的情况下尤其具有价值,可以帮助开发者快速构建高质量的AI系统。
📄 摘要(原文)
Varied approaches for aligning language models have been proposed, including supervised fine-tuning, RLHF, and direct optimization methods such as DPO. Although DPO has rapidly gained popularity due to its straightforward training process and competitive results, there is an open question of whether there remain practical advantages of using a discriminator, like a reward model, to evaluate responses. We propose D2PO, discriminator-guided DPO, an approach for the online setting where preferences are being collected throughout learning. As we collect gold preferences, we use these not only to train our policy, but to train a discriminative response evaluation model to silver-label even more synthetic data for policy training. We explore this approach across a set of diverse tasks, including a realistic chat setting, we find that our approach leads to higher-quality outputs compared to DPO with the same data budget, and greater efficiency in terms of preference data requirements. Furthermore, we show conditions under which silver labeling is most helpful: it is most effective when training the policy with DPO, outperforming traditional PPO, and benefits from maintaining a separate discriminator from the policy model.