Controllable Text Generation in the Instruction-Tuning Era
作者: Dhananjay Ashok, Barnabas Poczos
分类: cs.CL, cs.AI
发布日期: 2024-05-02
💡 一句话要点
提出ConGenBench基准测试,评估指令调优语言模型在可控文本生成中的性能,并提出自动生成约束数据集的算法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可控文本生成 指令调优 提示学习 基准测试 自动数据生成
📋 核心要点
- 现有可控文本生成研究主要集中于控制基础语言模型,而忽略了指令调优和提示学习的新范式。
- 论文提出利用大型语言模型的上下文学习能力,自动生成约束数据集,从而摆脱对人工标注数据的依赖。
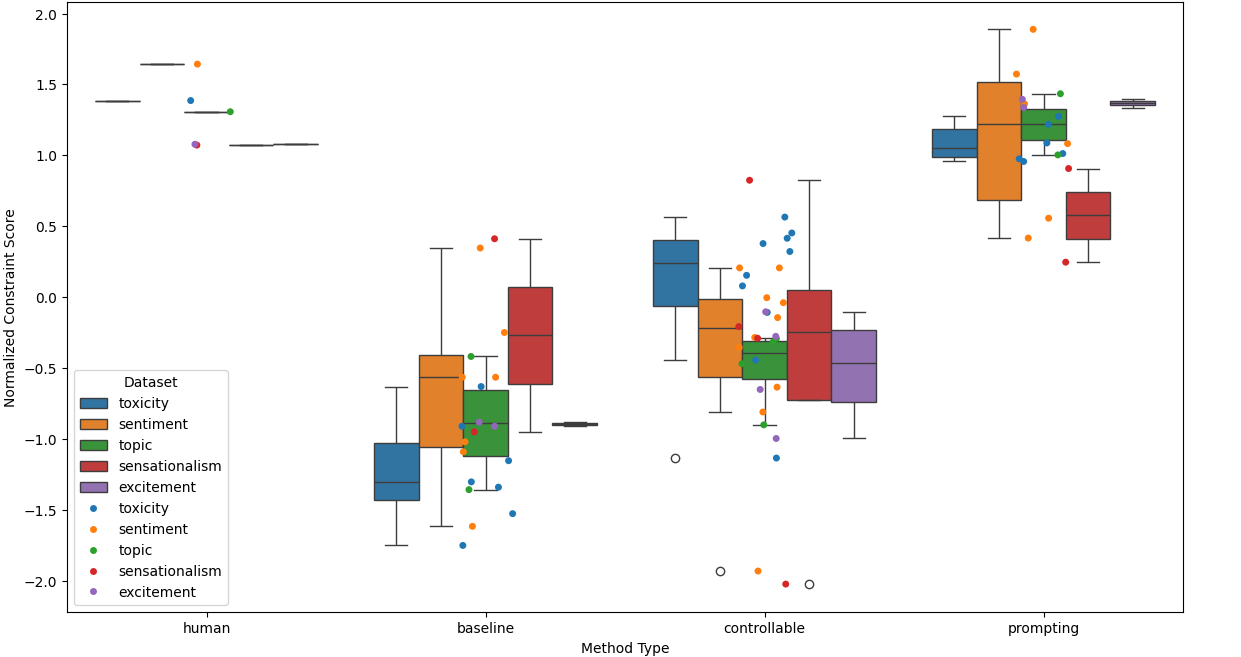
- 实验表明,基于提示的方法在指令调优模型上表现优异,但在结构化任务上仍有提升空间。
📝 摘要(中文)
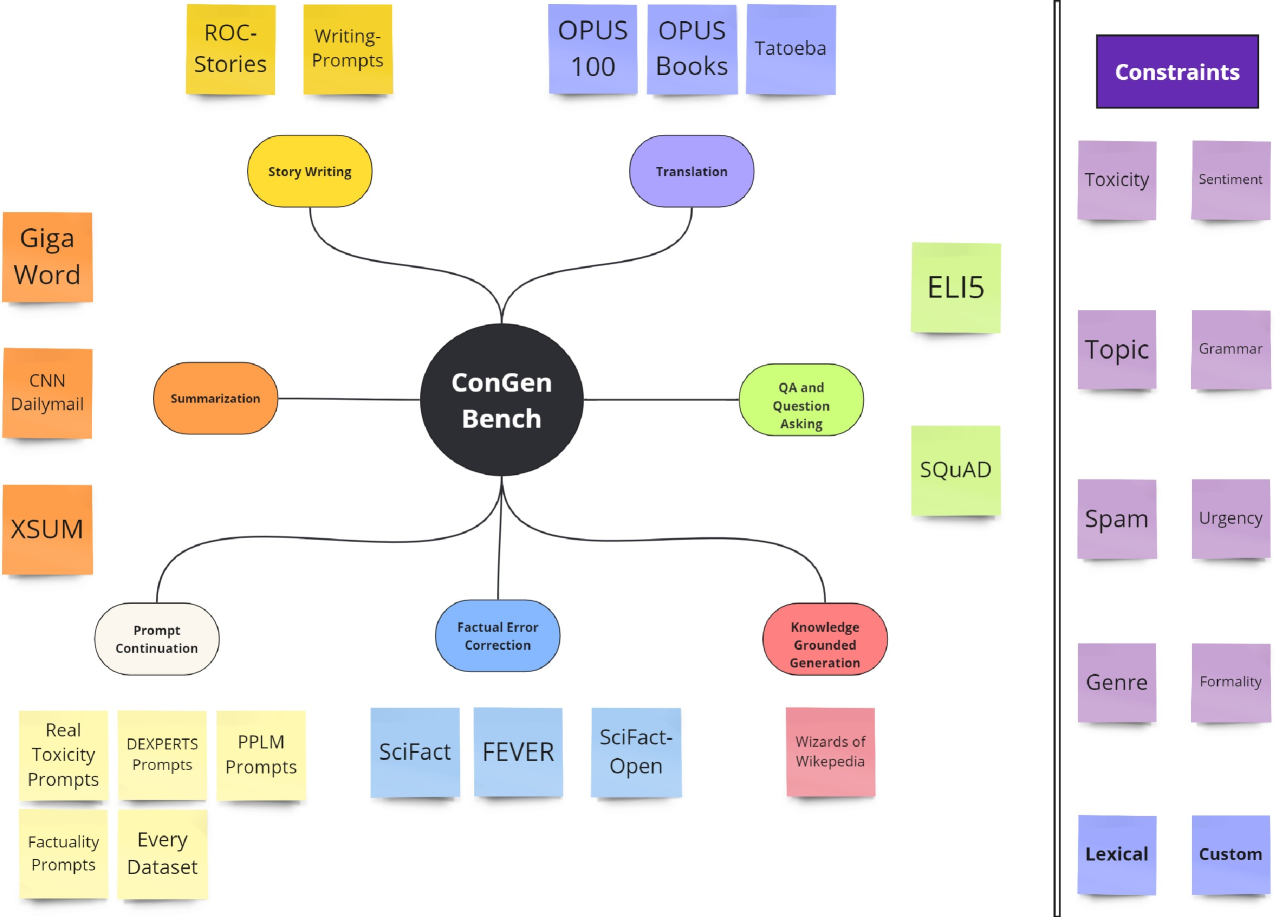
本文研究了指令调优和提示学习范式下可控文本生成的问题。作者构建并发布了ConGenBench,一个包含17个不同可控生成任务的基准测试集,并使用其中的一个子集来评估9种不同的基线方法在指令调优语言模型上的性能。研究发现,基于提示的方法在大多数数据集和任务上优于传统的可控文本生成方法,这表明需要专门针对指令调优语言模型进行可控文本生成的研究。基于提示的方法在大多数风格任务上与人类表现相当,但在结构任务上表现较差,这突出了研究更多样化的约束和更具挑战性的风格任务的必要性。为了促进此类研究,作者提供了一种算法,该算法仅使用任务数据集和一个具有上下文学习能力的大型语言模型来自动生成约束数据集,从而消除了对预先策划的约束数据集的依赖,并极大地扩展了未来可以研究的约束范围。
🔬 方法详解
问题定义:现有可控文本生成方法主要针对基础语言模型,忽略了指令调优语言模型。同时,构建可控文本生成的约束数据集通常需要大量人工标注,成本高昂且难以扩展到新的约束类型。
核心思路:利用指令调优语言模型强大的上下文学习能力,通过少量示例提示,引导模型生成满足特定约束的文本。同时,设计算法自动生成约束数据集,从而降低数据依赖性。
技术框架:论文主要包含两个部分:1) 构建ConGenBench基准测试集,用于评估不同方法在可控文本生成任务上的性能。2) 提出自动生成约束数据集的算法。该算法利用大型语言模型,给定任务数据集和少量示例,生成包含约束信息的训练数据。
关键创新:核心创新在于利用大型语言模型的上下文学习能力,自动生成约束数据集,从而避免了对人工标注数据的依赖。这使得研究者可以更方便地探索各种约束条件下的可控文本生成。
关键设计:自动生成约束数据集的算法的关键在于设计合适的提示语,引导大型语言模型生成高质量的约束数据。具体来说,需要提供任务描述、少量示例以及约束类型等信息,并调整生成参数以控制生成数据的质量和多样性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于提示的方法在指令调优语言模型上表现优于传统的可控文本生成方法。在ConGenBench基准测试集上,基于提示的方法在大多数风格任务上与人类表现相当,但在结构任务上仍有提升空间。自动生成约束数据集的方法能够有效降低数据标注成本,并扩展可研究的约束类型。
🎯 应用场景
该研究成果可应用于各种需要精确控制文本属性的场景,例如:自动生成符合特定风格的文章、生成满足特定语法规则的代码、生成带有特定情感色彩的评论等。自动生成约束数据集的方法可以降低可控文本生成研究的门槛,促进该领域的发展。
📄 摘要(原文)
While most research on controllable text generation has focused on steering base Language Models, the emerging instruction-tuning and prompting paradigm offers an alternate approach to controllability. We compile and release ConGenBench, a testbed of 17 different controllable generation tasks, using a subset of it to benchmark the performance of 9 different baselines and methods on Instruction-tuned Language Models. To our surprise, we find that prompting-based approaches outperform controllable text generation methods on most datasets and tasks, highlighting a need for research on controllable text generation with Instruction-tuned Language Models in specific. Prompt-based approaches match human performance on most stylistic tasks while lagging on structural tasks, foregrounding a need to study more varied constraints and more challenging stylistic tasks. To facilitate such research, we provide an algorithm that uses only a task dataset and a Large Language Model with in-context capabilities to automatically generate a constraint dataset. This method eliminates the fields dependence on pre-curated constraint datasets, hence vastly expanding the range of constraints that can be studied in the future.