Efficient Data Generation for Source-grounded Information-seeking Dialogs: A Use Case for Meeting Transcripts
作者: Lotem Golany, Filippo Galgani, Maya Mamo, Nimrod Parasol, Omer Vandsburger, Nadav Bar, Ido Dagan
分类: cs.CL, cs.AI
发布日期: 2024-05-02 (更新: 2024-10-15)
💡 一句话要点
提出基于LLM半自动数据生成方法,用于会议记录上的源接地信息检索对话任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息检索对话 数据生成 大型语言模型 会议记录 源接地 半自动标注 自然语言处理
📋 核心要点
- 现有方法在长文档和噪声数据上进行源接地信息检索对话时,自动归因仍然是一个挑战。
- 提出一种半自动数据生成方法,利用LLM生成对话内容,人工验证并标注归因范围,降低标注成本。
- 构建了MISeD数据集,实验表明,基于MISeD微调的模型在响应生成和归因质量上均优于现有模型。
📝 摘要(中文)
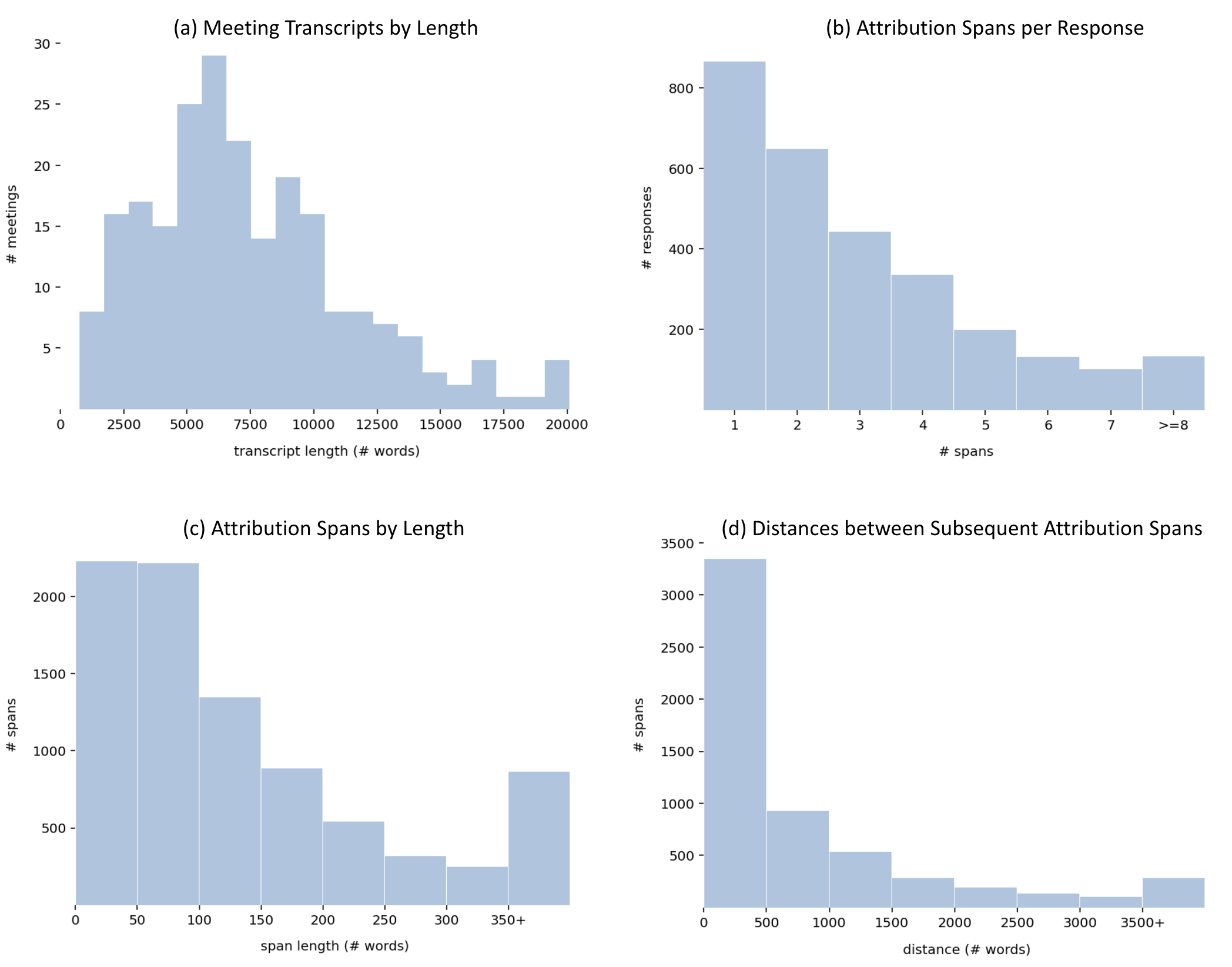
本文研究了基于大型语言模型(LLM)的数据自动生成在源接地信息检索对话这一具有挑战性场景中的可行性和有效性,该场景需要对长文档进行响应归因。我们的源文本包含冗长且嘈杂的会议记录,增加了任务的复杂性。由于自动归因仍然很困难,我们提出了一种半自动方法:使用LLM生成对话查询和响应,然后由人工验证和识别归因范围。使用这种方法,我们创建了MISeD——会议信息检索对话数据集——一个专注于会议记录的信息检索对话数据集。使用MISeD进行微调的模型表现出优于现有模型的性能,即使是那些规模更大的模型。在MISeD上进行微调,在响应生成质量上与在完全手动数据上进行微调相当,同时提高了归因质量,并减少了时间和精力。
🔬 方法详解
问题定义:论文旨在解决在长且嘈杂的会议记录上构建源接地信息检索对话数据集的问题。现有方法在处理长文档时,自动归因的准确率较低,人工标注成本高昂,难以构建大规模数据集。
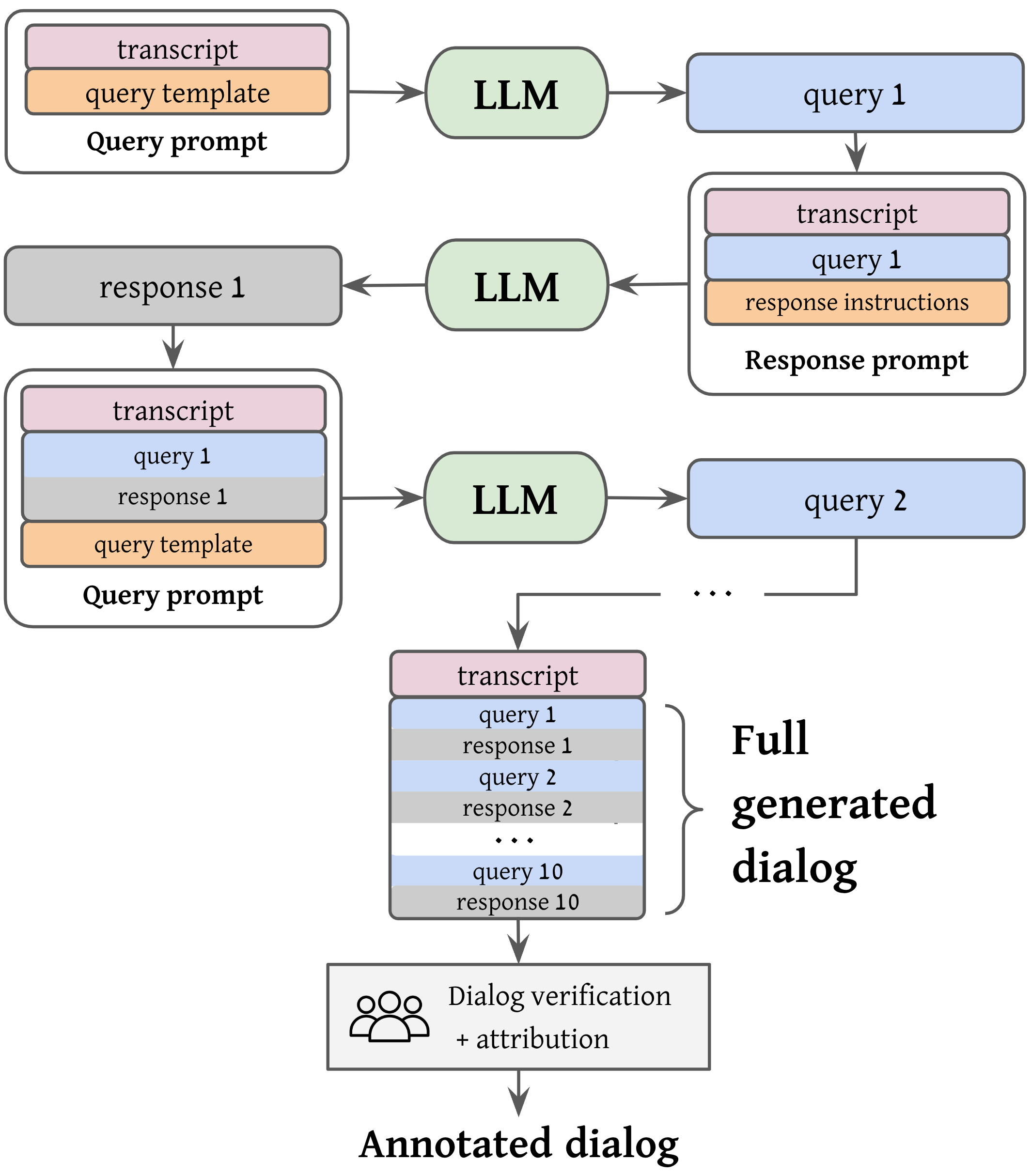
核心思路:论文的核心思路是利用LLM强大的生成能力,自动生成对话的查询和回复,然后通过人工验证和标注的方式,修正LLM生成结果中的错误,并标注回复的归因范围。这种半自动的方式可以显著降低人工标注的成本,同时保证数据集的质量。
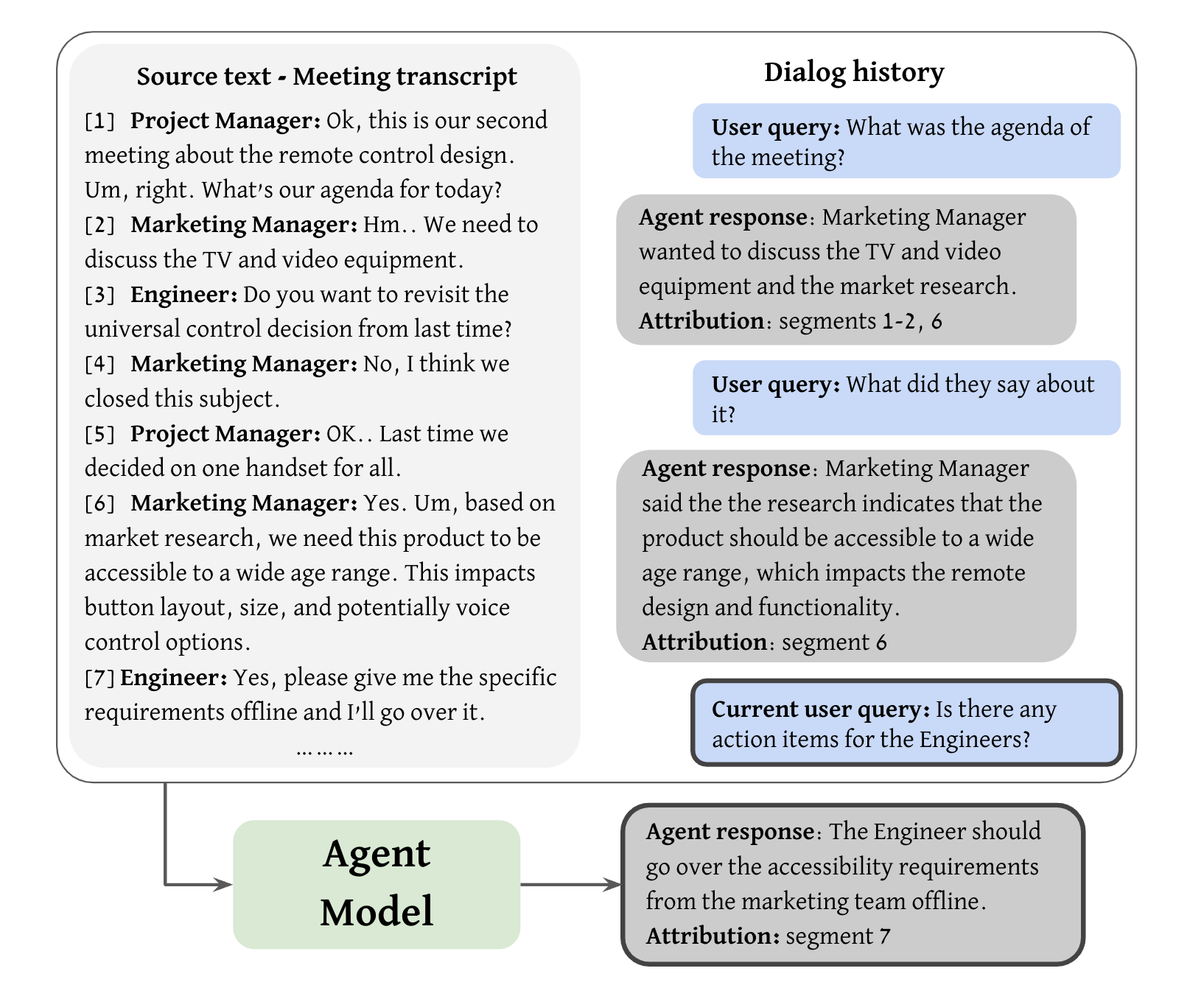
技术框架:整体流程包括以下几个阶段:1) 使用LLM生成对话查询和回复;2) 人工审核和修正LLM生成的内容,确保对话的流畅性和准确性;3) 人工标注回复的归因范围,即在源文档中找到支持回复的文本片段;4) 将生成的数据集用于微调对话模型,提升模型在源接地信息检索对话任务上的性能。
关键创新:该方法最大的创新在于提出了半自动的数据生成流程,结合了LLM的生成能力和人工的审核能力,有效地解决了长文档上源接地信息检索对话数据集构建的难题。与完全人工标注相比,该方法大大降低了标注成本,与完全自动生成相比,该方法保证了数据集的质量。
关键设计:论文中没有详细描述LLM的具体选择和参数设置,以及人工审核的具体标准。但是,人工标注归因范围是关键的设计,保证了数据集的源接地特性。损失函数方面,论文没有提及专门设计的损失函数,推测是使用了标准的对话生成和归因任务的损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用MISeD数据集微调的模型,在响应生成质量上与在完全手动数据上进行微调的模型相当,同时提高了归因质量,并减少了时间和精力。这表明半自动数据生成方法是有效的,可以用于构建高质量的源接地信息检索对话数据集。
🎯 应用场景
该研究成果可应用于智能会议助手、文档问答系统、客户服务等领域。通过构建高质量的源接地信息检索对话数据集,可以提升相关应用在处理长文档和噪声数据时的性能,提高用户体验。未来,该方法可以推广到其他类型的文档,例如法律文件、技术报告等。
📄 摘要(原文)
Automating data generation with Large Language Models (LLMs) has become increasingly popular. In this work, we investigate the feasibility and effectiveness of LLM-based data generation in the challenging setting of source-grounded information-seeking dialogs, with response attribution, over long documents. Our source texts consist of long and noisy meeting transcripts, adding to the task complexity. Since automating attribution remains difficult, we propose a semi-automatic approach: dialog queries and responses are generated with LLMs, followed by human verification and identification of attribution spans. Using this approach, we created MISeD -- Meeting Information Seeking Dialogs dataset -- a dataset of information-seeking dialogs focused on meeting transcripts. Models finetuned with MISeD demonstrate superior performance compared to off-the-shelf models, even those of larger size. Finetuning on MISeD gives comparable response generation quality to finetuning on fully manual data, while improving attribution quality and reducing time and effort.