When Quantization Affects Confidence of Large Language Models?
作者: Irina Proskurina, Luc Brun, Guillaume Metzler, Julien Velcin
分类: cs.CL, cs.AI
发布日期: 2024-05-01
备注: Accepted to NAACL 2024 Findings
💡 一句话要点
研究量化对大语言模型置信度的影响,揭示低置信度样本更易受损
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 置信度 模型压缩 GPTQ
📋 核心要点
- 现有大语言模型压缩方法(如量化)虽然提升了效率,但可能损害模型性能和加剧偏差。
- 该研究通过分析量化后模型对真实标签的置信度变化,评估量化对模型置信度的影响。
- 实验表明,4比特量化会降低模型对真实标签的置信度,且低置信度样本受量化影响更大。
📝 摘要(中文)
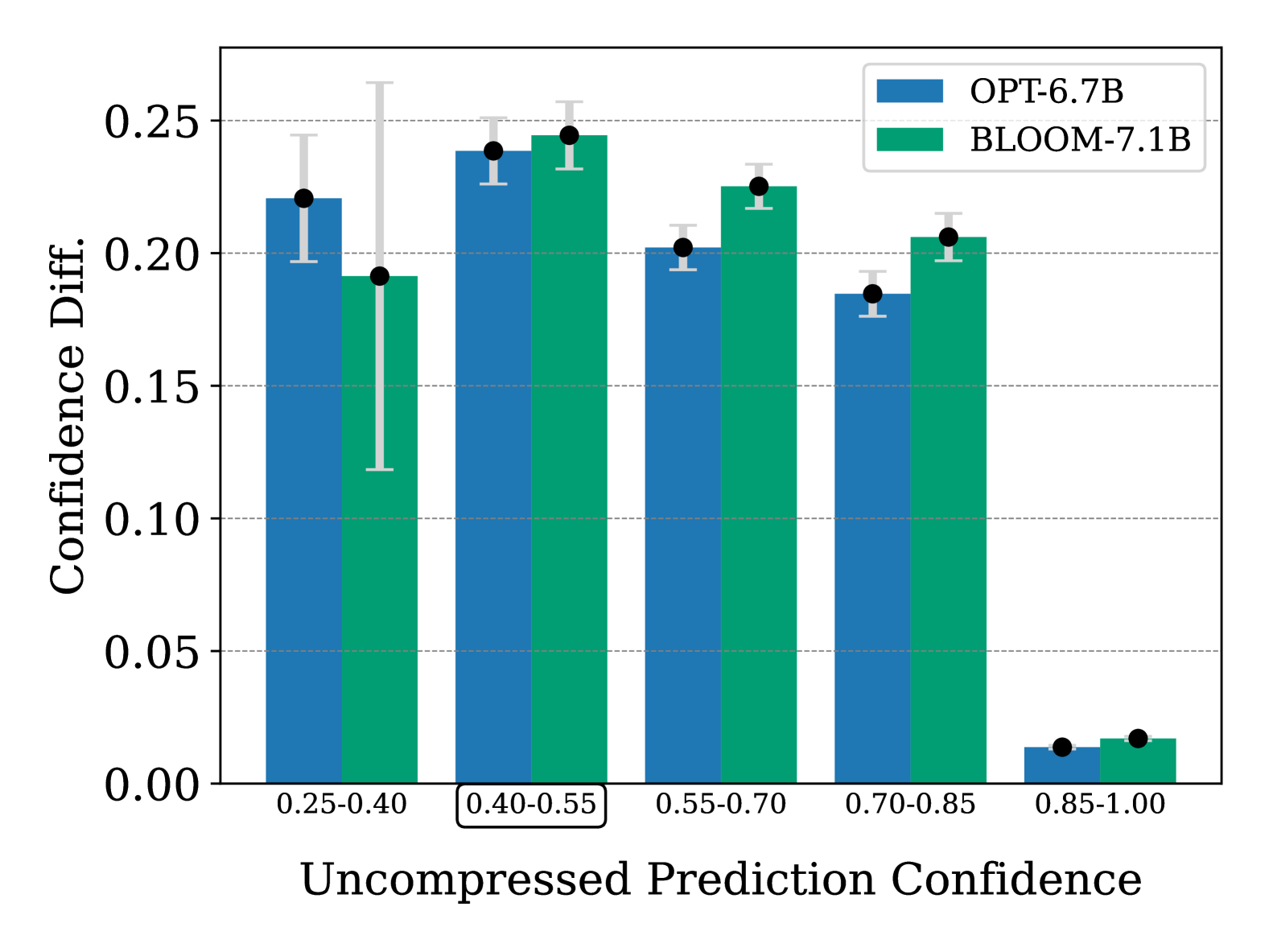
本研究探讨了后训练量化或低比特权重表示等压缩技术对大语言模型(LLM)置信度和校准的影响。尽管量化权重提高了存储效率并加快了推理速度,但现有研究表明,量化可能会损害LLM的性能并加剧其偏差。本研究考察了量化模型的置信度和校准,并将语言模型类型和规模等因素视为量化损失的促成因素。首先,我们发现使用GPTQ进行4比特量化会导致真实标签的置信度下降,且不同语言模型的影响各不相同。其次,我们观察到不同规模的模型对置信度的影响存在波动。最后,我们基于置信度水平提出了量化损失的解释,表明量化对完整模型最初表现出较低置信度水平的样本的影响尤为严重。
🔬 方法详解
问题定义:论文旨在研究大语言模型(LLM)量化后,其置信度是否会受到影响,以及这种影响与哪些因素相关。现有方法在关注量化带来的性能和偏差问题时,较少关注量化对模型置信度的影响,而置信度是模型可靠性的重要指标。
核心思路:论文的核心思路是分析量化前后模型对同一输入样本的预测置信度变化。通过比较量化前后模型对真实标签的置信度差异,来评估量化对模型置信度的影响。同时,考虑不同模型类型、模型规模以及样本本身的置信度水平等因素,分析这些因素与量化损失之间的关系。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择不同类型和规模的大语言模型;2) 使用GPTQ方法将模型量化到4比特;3) 使用测试数据集,分别计算量化前后模型对每个样本的预测置信度(真实标签对应的概率);4) 分析量化前后置信度的差异,并考察模型类型、规模和原始置信度水平等因素对置信度损失的影响。
关键创新:论文的关键创新在于揭示了量化对大语言模型置信度的影响,并发现量化对原始置信度较低的样本影响更大。这一发现为理解量化损失的本质提供了新的视角,并为设计更鲁棒的量化方法提供了指导。
关键设计:论文的关键设计包括:1) 使用GPTQ作为量化方法,因为它是一种常用的后训练量化方法;2) 选择不同类型(例如,decoder-only模型)和规模的大语言模型,以考察模型类型和规模对量化影响的差异;3) 使用真实标签对应的概率作为置信度指标,简单直接;4) 通过统计分析量化前后置信度的差异,并考察不同因素的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用GPTQ将大语言模型量化到4比特会导致模型对真实标签的置信度下降。不同语言模型和不同规模的模型受到的影响程度不同。更重要的是,研究发现量化对原始置信度较低的样本影响更大,这表明量化可能会加剧模型对不确定性样本的错误判断。
🎯 应用场景
该研究成果可应用于大语言模型的压缩和部署,帮助开发者在保证模型效率的同时,关注量化对模型置信度的影响,从而提高模型的可靠性和安全性。此外,该研究也为设计更鲁棒的量化算法提供了理论基础,例如,可以针对低置信度样本进行特殊处理,以减轻量化带来的负面影响。
📄 摘要(原文)
Recent studies introduced effective compression techniques for Large Language Models (LLMs) via post-training quantization or low-bit weight representation. Although quantized weights offer storage efficiency and allow for faster inference, existing works have indicated that quantization might compromise performance and exacerbate biases in LLMs. This study investigates the confidence and calibration of quantized models, considering factors such as language model type and scale as contributors to quantization loss. Firstly, we reveal that quantization with GPTQ to 4-bit results in a decrease in confidence regarding true labels, with varying impacts observed among different language models. Secondly, we observe fluctuations in the impact on confidence across different scales. Finally, we propose an explanation for quantization loss based on confidence levels, indicating that quantization disproportionately affects samples where the full model exhibited low confidence levels in the first place.