Addressing Topic Granularity and Hallucination in Large Language Models for Topic Modelling
作者: Yida Mu, Peizhen Bai, Kalina Bontcheva, Xingyi Song
分类: cs.CL
发布日期: 2024-05-01
💡 一句话要点
提出基于DPO微调的LLM主题建模方法,解决主题粒度和幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主题建模 大型语言模型 直接偏好优化 主题粒度 幻觉抑制 零样本学习 文本分析
📋 核心要点
- 现有基于LLM的主题建模方法难以控制主题粒度,易产生大量重复主题,且缺乏解决幻觉问题的有效手段。
- 论文提出利用直接偏好优化(DPO)微调开源LLM,通过重建管道修改原始主题,无需人工标注即可实现高效训练。
- 实验结果表明,该方法显著提升了LLM生成主题的连贯性、相关性和精确性,并有效减少了幻觉主题的产生。
📝 摘要(中文)
大型语言模型(LLMs)凭借其强大的零样本主题提取能力,为概率主题建模和封闭集主题分类方法提供了一种替代方案。作为零样本主题提取器,LLM应理解人类指令,基于给定的文档生成相关且非幻觉的主题。然而,基于LLM的主题建模方法在生成主题时,常常难以遵守人类指令中指定的主题粒度,导致出现许多近乎重复的主题。此外,解决LLM生成的幻觉主题的方法尚未得到研究。本文重点关注解决基于LLM的主题建模中的主题粒度和幻觉问题。为此,我们引入了一种新颖的方法,该方法利用直接偏好优化(DPO)来微调开源LLM,例如Mistral-7B。我们的方法不依赖于传统的人工标注来对首选答案进行排序,而是采用重建管道来修改LLM生成的原始主题,从而实现快速高效的训练和推理框架。对比实验表明,我们的微调方法不仅显著提高了LLM生成更连贯、相关和精确主题的能力,而且减少了幻觉主题的数量。
🔬 方法详解
问题定义:论文旨在解决基于大型语言模型(LLM)进行主题建模时存在的两个主要问题:一是主题粒度控制不足,导致生成大量重复或相似的主题;二是LLM生成幻觉主题,即生成与输入文档不相关或不一致的主题。现有方法缺乏有效机制来约束主题的粒度,并且没有专门针对LLM主题建模中幻觉问题的解决方案。
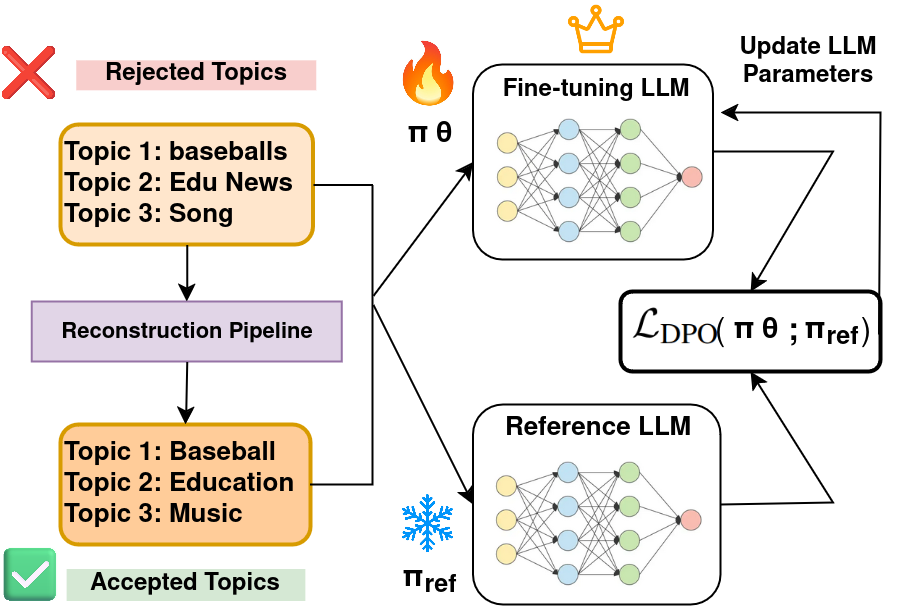
核心思路:论文的核心思路是利用直接偏好优化(DPO)来微调LLM,使其更好地遵循人类指令,生成更符合要求的主题。DPO是一种无需人工标注的偏好学习方法,通过重建管道自动生成偏好数据,从而指导LLM的学习。这种方法避免了传统人工标注的成本和主观性,提高了训练效率。
技术框架:整体框架包含以下几个主要阶段:1. 原始主题生成:使用LLM生成初始主题。2. 主题重建:通过重建管道修改原始主题,生成更符合要求的候选主题。3. 偏好学习:利用DPO算法,基于重建后的主题数据,微调LLM。4. 主题提取:使用微调后的LLM提取最终主题。
关键创新:论文的关键创新在于:1. 提出了一种基于DPO的LLM主题建模微调方法,无需人工标注即可有效控制主题粒度和减少幻觉。2. 设计了一种重建管道,用于自动生成偏好数据,从而指导DPO的训练。3. 将DPO应用于LLM主题建模领域,为解决主题粒度和幻觉问题提供了一种新的思路。
关键设计:重建管道的具体设计细节未知,但可以推测其可能包含以下步骤:1. 主题聚类:将原始主题进行聚类,识别重复或相似的主题。2. 主题融合/拆分:根据聚类结果,将相似的主题进行融合,或将过于宽泛的主题进行拆分,以调整主题粒度。3. 主题过滤:根据预定义的规则或指标,过滤掉与输入文档不相关或不一致的主题,以减少幻觉。DPO的损失函数和超参数设置未知,但通常会根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在主题建模任务中取得了显著的性能提升。具体而言,该方法不仅能够生成更连贯、相关和精确的主题,而且能够有效减少幻觉主题的产生。相较于基线方法,该方法在主题质量和幻觉抑制方面均取得了显著的改进,但具体的性能数据和提升幅度未知。
🎯 应用场景
该研究成果可应用于多个领域,如新闻分析、社交媒体监控、市场调研、科技情报分析等。通过更精确和可控的主题建模,可以帮助用户更好地理解海量文本数据,发现潜在的趋势和模式,为决策提供支持。未来,该方法有望进一步扩展到其他自然语言处理任务中,如文本摘要、信息检索等。
📄 摘要(原文)
Large language models (LLMs) with their strong zero-shot topic extraction capabilities offer an alternative to probabilistic topic modelling and closed-set topic classification approaches. As zero-shot topic extractors, LLMs are expected to understand human instructions to generate relevant and non-hallucinated topics based on the given documents. However, LLM-based topic modelling approaches often face difficulties in generating topics with adherence to granularity as specified in human instructions, often resulting in many near-duplicate topics. Furthermore, methods for addressing hallucinated topics generated by LLMs have not yet been investigated. In this paper, we focus on addressing the issues of topic granularity and hallucinations for better LLM-based topic modelling. To this end, we introduce a novel approach that leverages Direct Preference Optimisation (DPO) to fine-tune open-source LLMs, such as Mistral-7B. Our approach does not rely on traditional human annotation to rank preferred answers but employs a reconstruction pipeline to modify raw topics generated by LLMs, thus enabling a fast and efficient training and inference framework. Comparative experiments show that our fine-tuning approach not only significantly improves the LLM's capability to produce more coherent, relevant, and precise topics, but also reduces the number of hallucinated topics.