NumLLM: Numeric-Sensitive Large Language Model for Chinese Finance
作者: Huan-Yi Su, Ke Wu, Yu-Hao Huang, Wu-Jun Li
分类: cs.CE, cs.CL, q-fin.GN
发布日期: 2024-05-01
💡 一句话要点
提出NumLLM,提升中文金融大模型对数值变量的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 金融大模型 数值理解 低秩适应 金融问答 中文金融 LoRA 语料库构建
📋 核心要点
- 现有金融大模型在处理包含数值变量的金融文本时表现不佳,无法准确理解和回答相关问题。
- NumLLM通过构建金融语料库并训练两个LoRA模块,分别提升金融领域适应性和数值理解能力。
- 实验表明,NumLLM在金融问答基准测试中,显著提升了基础模型的性能,优于其他基线模型。
📝 摘要(中文)
本文提出了一种名为数值敏感大语言模型(NumLLM)的新型LLM,专门用于中文金融领域。现有FinLLM在理解包含数值变量的金融文本时表现不佳。本文首先从金融教科书中构建了一个金融语料库,这对于提高LLM在微调期间的数值能力至关重要。然后,通过在我们构建的金融语料库上进行微调,训练两个独立的低秩适应(LoRA)模块。一个模块用于将通用LLM适应到金融领域,另一个模块用于增强NumLLM理解包含数值变量的金融文本的能力。最后,我们将两个LoRA模块合并到基础模型中,以获得用于推理的NumLLM。在金融问答基准上的实验表明,NumLLM可以提高基础模型的性能,并且在数值和非数值问题上,与所有基线相比,可以实现最佳的整体性能。
🔬 方法详解
问题定义:现有金融大语言模型(FinLLM)在处理涉及数值变量的金融文本时,表现出令人不满意的性能。它们难以准确理解和推理包含数字的金融问题,导致问答效果不佳。因此,需要一种能够有效处理数值信息的金融大语言模型。
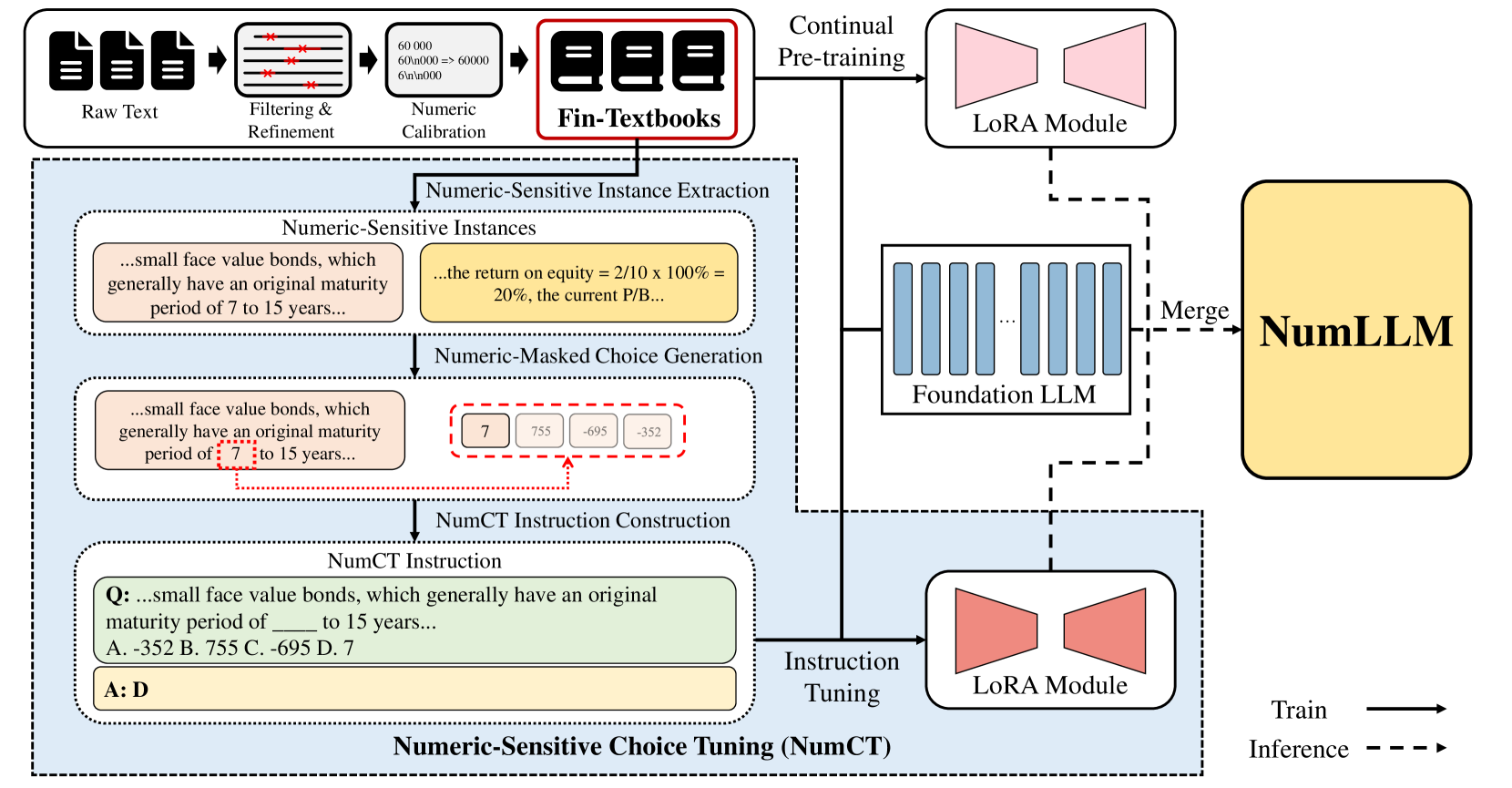
核心思路:NumLLM的核心思路是通过构建专门的金融语料库,并采用低秩适应(LoRA)技术,分别对通用LLM进行金融领域知识的适配和数值理解能力的增强。通过两个LoRA模块的训练和融合,使模型既具备金融领域的专业知识,又能够准确处理数值信息。
技术框架:NumLLM的整体框架包括以下几个主要阶段:1) 构建金融语料库:从金融教科书中收集数据,构建包含丰富数值信息的金融语料库。2) 训练LoRA模块:训练两个LoRA模块,一个用于将通用LLM适应到金融领域,另一个用于增强模型理解包含数值变量的金融文本的能力。3) 模型融合:将两个LoRA模块合并到基础模型中,得到NumLLM。4) 推理:使用NumLLM进行金融问答。
关键创新:NumLLM的关键创新在于针对数值理解能力不足的问题,提出了专门的训练策略。通过构建金融语料库和训练独立的LoRA模块,实现了对金融领域知识和数值理解能力的解耦和增强。与直接在通用LLM上进行微调的方法相比,NumLLM能够更有效地提升模型在数值金融问题上的表现。
关键设计:在LoRA模块的训练过程中,采用了低秩分解技术,减少了需要训练的参数量,提高了训练效率。针对数值理解能力的增强,可能采用了特定的损失函数或数据增强方法,以提高模型对数值信息的敏感度。具体的参数设置和网络结构细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,NumLLM在金融问答基准测试中,相较于其他基线模型,取得了最佳的整体性能。尤其是在处理包含数值变量的问题时,NumLLM的性能提升更为显著,验证了其在数值理解方面的优势。具体性能数据和提升幅度需要在论文中查找。
🎯 应用场景
NumLLM可应用于智能金融问答系统、金融文本分析、风险评估、投资决策支持等领域。通过提升模型对数值信息的理解能力,可以更准确地解读金融报告、预测市场趋势,为金融从业者和投资者提供更可靠的决策依据,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Recently, many works have proposed various financial large language models (FinLLMs) by pre-training from scratch or fine-tuning open-sourced LLMs on financial corpora. However, existing FinLLMs exhibit unsatisfactory performance in understanding financial text when numeric variables are involved in questions. In this paper, we propose a novel LLM, called numeric-sensitive large language model (NumLLM), for Chinese finance. We first construct a financial corpus from financial textbooks which is essential for improving numeric capability of LLMs during fine-tuning. After that, we train two individual low-rank adaptation (LoRA) modules by fine-tuning on our constructed financial corpus. One module is for adapting general-purpose LLMs to financial domain, and the other module is for enhancing the ability of NumLLM to understand financial text with numeric variables. Lastly, we merge the two LoRA modules into the foundation model to obtain NumLLM for inference. Experiments on financial question-answering benchmark show that NumLLM can boost the performance of the foundation model and can achieve the best overall performance compared to all baselines, on both numeric and non-numeric questions.