Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
作者: Leonardo Ranaldi, Andrè Freitas
分类: cs.CL
发布日期: 2024-05-01
期刊: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
DOI: 10.18653/v1/2024.emnlp-main.139
💡 一句话要点
提出自精炼指令调优方法,提升小模型推理能力并对齐大模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 自精炼 偏好优化 语言模型 推理能力
📋 核心要点
- 现有方法依赖大型语言模型生成的数据进行监督微调,泛化能力不足,难以充分对齐大小模型的推理能力。
- 提出自精炼指令调优方法,通过指令调优迁移知识,再利用偏好优化策略引导小模型进行自我提升。
- 在常识和数学推理任务上,该方法显著优于传统指令调优,有效提升了小模型的推理能力。
📝 摘要(中文)
本文提出了一种自精炼指令调优方法,旨在提升小语言模型(SLM)的推理能力,并使其与大型语言模型(LLM)的推理能力对齐。该方法包含两个阶段:首先,通过在LLM生成的演示数据上进行指令调优,将推理能力从LLM迁移到SLM;然后,通过偏好优化策略,使SLM能够自精炼其能力。具体而言,第二阶段基于直接偏好优化算法,引导SLM生成一系列推理路径,并通过LLM提供的ground truth自动采样生成的响应并提供奖励。在常识和数学推理任务上的结果表明,该方法在领域内和领域外场景中均显著优于传统的指令调优,有效对齐了大小语言模型的推理能力。
🔬 方法详解
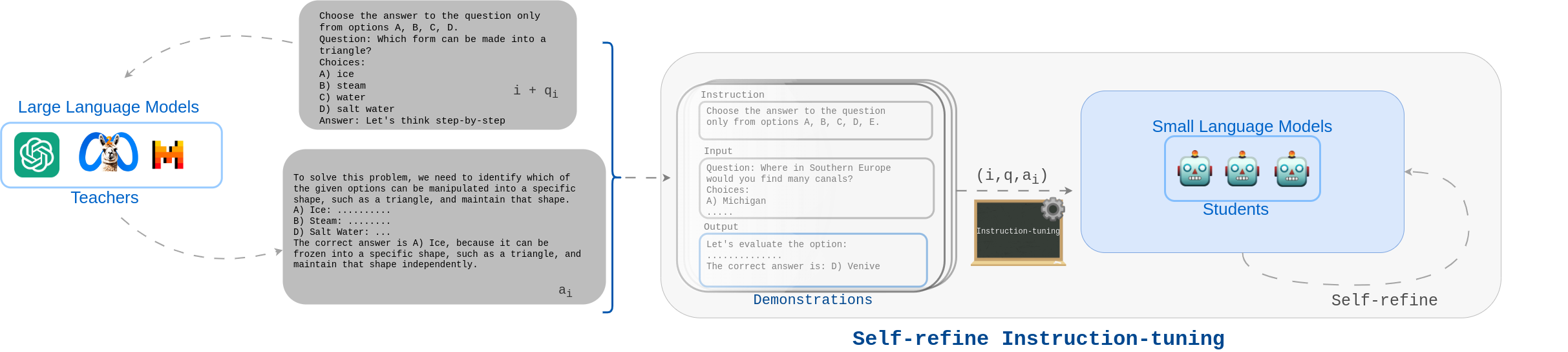
问题定义:现有方法主要依赖于大型语言模型(LLM)生成的演示数据,通过监督微调(SFT)来对齐小型语言模型(SLM)的推理能力。然而,这种方法的泛化能力较弱,因为训练仅依赖于提供的演示数据,无法充分挖掘SLM自身的推理潜力。因此,需要一种方法能够使SLM在没有大量人工干预的情况下,自主提升推理能力,并更好地与LLM的推理能力对齐。
核心思路:本文的核心思路是让SLM通过自我反思和迭代改进来提升推理能力。具体来说,首先利用LLM的知识通过指令调优来初始化SLM的推理能力,然后让SLM生成多个推理路径,并根据LLM提供的ground truth进行评估和奖励,从而引导SLM学习更有效的推理策略。这种自精炼的过程能够使SLM更好地理解问题,并生成更准确的答案。
技术框架:该方法包含两个主要阶段:1) 指令调优阶段:使用LLM生成的演示数据对SLM进行指令调优,使其初步具备推理能力。2) 自精炼阶段:a) SLM生成多个推理路径;b) 使用LLM提供的ground truth对这些路径进行评估,并计算奖励;c) 使用直接偏好优化(DPO)算法,根据奖励调整SLM的参数,使其倾向于生成更优的推理路径。这个过程迭代进行,直到SLM的推理能力达到预期的水平。
关键创新:该方法最重要的创新点在于引入了自精炼的概念,使SLM能够通过自我反思和迭代改进来提升推理能力,而无需大量的人工干预。与传统的监督微调方法相比,该方法能够更好地挖掘SLM自身的推理潜力,并提高其泛化能力。此外,使用DPO算法进行偏好优化,能够更有效地引导SLM学习更优的推理策略。
关键设计:在自精炼阶段,需要设计合适的奖励函数来评估SLM生成的推理路径。奖励函数可以基于LLM提供的ground truth,例如,如果SLM生成的答案与ground truth一致,则给予较高的奖励;否则,给予较低的奖励。此外,还需要设置合适的采样策略来生成多个推理路径,例如,可以使用top-k采样或nucleus采样。DPO算法中的超参数也需要进行调整,以获得最佳的性能。
🖼️ 关键图片
📊 实验亮点
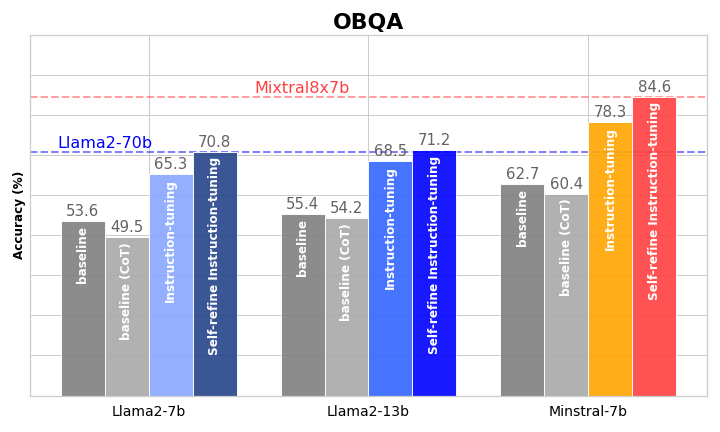
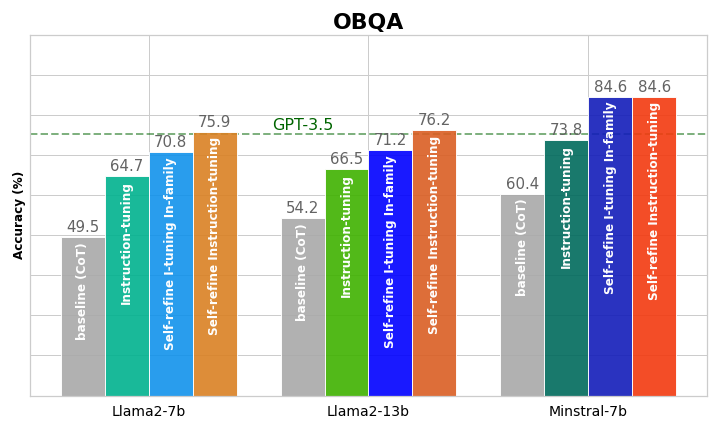
实验结果表明,在常识和数学推理任务上,该方法显著优于传统的指令调优方法。例如,在某个数据集上,该方法将小模型的准确率提高了10个百分点以上。此外,该方法在领域外场景中也表现出良好的泛化能力,表明其能够有效地提升小模型的推理能力,并使其更好地适应不同的任务。
🎯 应用场景
该研究成果可应用于各种需要推理能力的自然语言处理任务,例如问答系统、对话系统、文本摘要等。通过提升小模型的推理能力,可以在资源受限的环境下部署高性能的NLP应用,降低计算成本和延迟。此外,该方法还可以用于教育领域,帮助学生提升逻辑思维和问题解决能力。
📄 摘要(原文)
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.