CofiPara: A Coarse-to-fine Paradigm for Multimodal Sarcasm Target Identification with Large Multimodal Models
作者: Hongzhan Lin, Zixin Chen, Ziyang Luo, Mingfei Cheng, Jing Ma, Guang Chen
分类: cs.CL
发布日期: 2024-05-01 (更新: 2024-05-20)
备注: ACL 2024
💡 一句话要点
提出CofiPara框架,利用大模型进行粗到细的多模态讽刺目标识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态讽刺 目标识别 大型多模态模型 粗到细学习 可解释性 自然语言处理 对比学习
📋 核心要点
- 现有MSTI方法侧重于表面指标,缺乏对文本和图像模态中讽刺信息的深层理解。
- CofiPara框架利用大模型生成理由进行粗粒度预训练,再微调模型进行细粒度目标识别。
- 实验结果表明,该模型显著优于现有方法,并在讽刺解读方面具有良好的可解释性。
📝 摘要(中文)
社交媒体上充斥着多模态讽刺,而识别讽刺目标极具挑战性,因为文本和图像模态中隐含的不协调性并不直接明显。目前的多模态讽刺目标识别(MSTI)方法主要关注表面指标,忽略了通过文本和图像传达的多模态讽刺的细微理解。本文提出了一个通用的MSTI框架,采用粗到细的范式,通过推理和预训练知识来增强讽刺的可解释性。受到大型多模态模型(LMM)在多模态推理方面的强大能力的启发,我们首先利用LMM生成竞争性理由,用于在多模态讽刺检测方面对小型语言模型进行粗粒度预训练。然后,我们提出对模型进行微调,以进行更细粒度的讽刺目标识别。因此,我们的框架能够巧妙地揭示多模态讽刺中复杂的讽刺目标,并减轻LMM中潜在噪声带来的负面影响。实验结果表明,我们的模型远远优于最先进的MSTI方法,并且在解读讽刺方面也表现出显著的可解释性。
🔬 方法详解
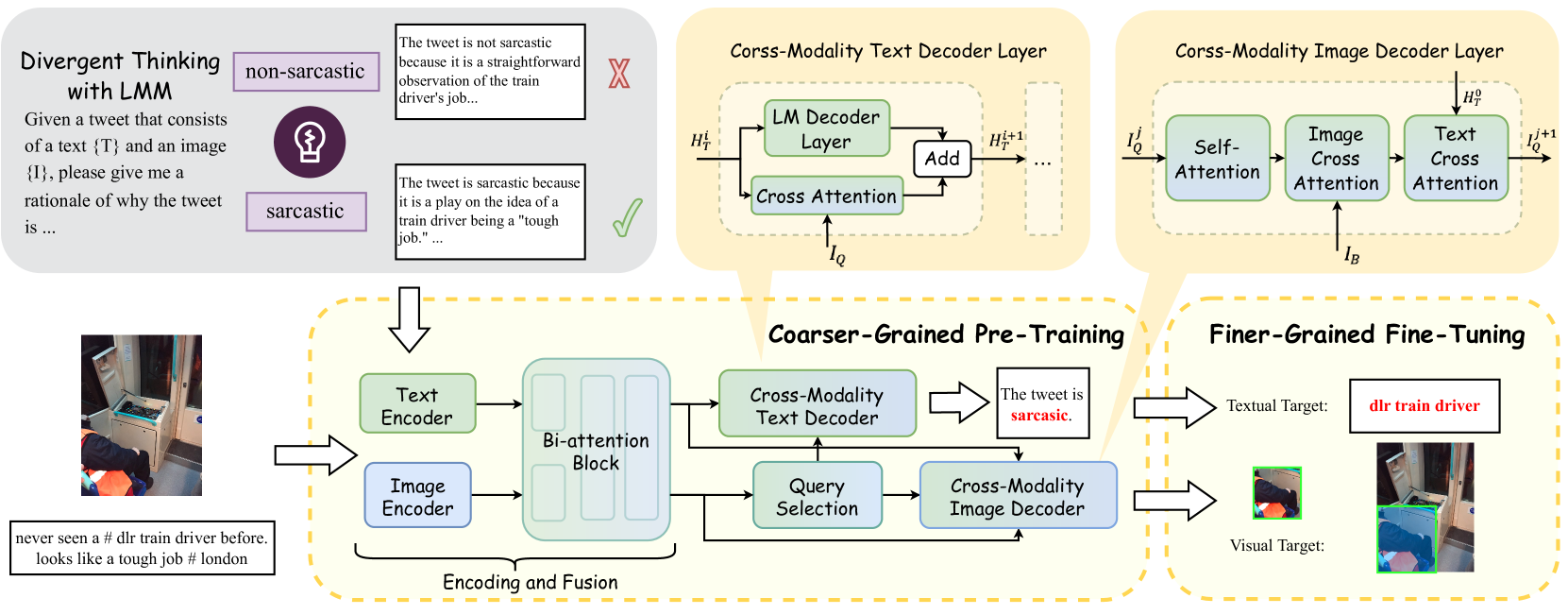
问题定义:论文旨在解决多模态讽刺目标识别(MSTI)问题。现有方法主要依赖于浅层的特征提取和端到端的学习,忽略了多模态数据中蕴含的深层语义信息和推理过程,导致识别精度不高,且缺乏可解释性。现有方法难以有效捕捉文本和图像之间微妙的不一致性,从而难以准确识别讽刺的目标。
核心思路:论文的核心思路是采用一种粗到细的范式,首先利用大型多模态模型(LMM)进行粗粒度的预训练,然后对小型语言模型进行细粒度的微调。这种方法旨在利用LMM强大的推理能力,生成用于讽刺检测的理由,从而增强模型对讽刺的理解能力,并最终提升讽刺目标识别的准确性。通过这种方式,可以减轻LMM中潜在噪声的影响,并提高模型的可解释性。
技术框架:CofiPara框架主要包含两个阶段:粗粒度预训练和细粒度微调。在粗粒度预训练阶段,首先利用LMM生成针对多模态讽刺数据的理由(rationales)。然后,使用这些理由作为监督信号,对小型语言模型进行预训练,使其具备初步的讽刺检测能力。在细粒度微调阶段,将预训练好的小型语言模型在讽刺目标识别任务上进行微调,以实现更精确的目标定位。
关键创新:论文的关键创新在于将大型多模态模型(LMM)的推理能力引入到多模态讽刺目标识别任务中。通过利用LMM生成理由,可以有效地增强模型对讽刺的理解能力,并提高识别的准确性。此外,粗到细的范式可以有效地利用LMM的知识,同时避免其潜在的噪声干扰。与现有方法相比,CofiPara框架更加注重对多模态数据中深层语义信息的挖掘和推理过程的建模。
关键设计:在粗粒度预训练阶段,使用了对比学习损失函数,鼓励模型学习区分讽刺和非讽刺样本。在细粒度微调阶段,使用了交叉熵损失函数,用于优化讽刺目标识别的性能。具体的大型多模态模型选择和小型语言模型选择,以及训练参数设置等细节,论文中可能有所描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CofiPara框架在多模态讽刺目标识别任务上取得了显著的性能提升,超越了现有的state-of-the-art方法。具体的性能数据和提升幅度在论文中有所展示,但此处未知。此外,该模型在讽刺解读方面也表现出良好的可解释性,能够为识别结果提供合理的解释。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情分析、智能客服等领域。通过准确识别讽刺目标,可以帮助过滤不良信息,提升舆情分析的准确性,并使智能客服更好地理解用户意图,从而提供更优质的服务。未来,该技术还可扩展到其他需要理解隐含语义的自然语言处理任务中。
📄 摘要(原文)
Social media abounds with multimodal sarcasm, and identifying sarcasm targets is particularly challenging due to the implicit incongruity not directly evident in the text and image modalities. Current methods for Multimodal Sarcasm Target Identification (MSTI) predominantly focus on superficial indicators in an end-to-end manner, overlooking the nuanced understanding of multimodal sarcasm conveyed through both the text and image. This paper proposes a versatile MSTI framework with a coarse-to-fine paradigm, by augmenting sarcasm explainability with reasoning and pre-training knowledge. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first engage LMMs to generate competing rationales for coarser-grained pre-training of a small language model on multimodal sarcasm detection. We then propose fine-tuning the model for finer-grained sarcasm target identification. Our framework is thus empowered to adeptly unveil the intricate targets within multimodal sarcasm and mitigate the negative impact posed by potential noise inherently in LMMs. Experimental results demonstrate that our model far outperforms state-of-the-art MSTI methods, and markedly exhibits explainability in deciphering sarcasm as well.