AdaMoLE: Fine-Tuning Large Language Models with Adaptive Mixture of Low-Rank Adaptation Experts
作者: Zefang Liu, Jiahua Luo
分类: cs.CL
发布日期: 2024-05-01 (更新: 2024-08-10)
💡 一句话要点
AdaMoLE:自适应混合低秩适配专家微调大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 低秩适配 混合专家 自适应选择
📋 核心要点
- 现有微调方法采用静态专家激活策略,无法有效应对不同任务的复杂性。
- AdaMoLE通过自适应阈值网络动态调整专家激活阈值,并结合门控函数选择最优专家。
- 实验表明,AdaMoLE在多种任务上超越基线模型,提升了模型性能且无需增加专家数量。
📝 摘要(中文)
本文提出了一种名为AdaMoLE的新方法,用于通过自适应混合低秩适配(LoRA)专家来微调大型语言模型(LLM)。AdaMoLE超越了使用静态top-k策略激活专家的传统方法,而是使用专门的阈值网络动态调整激活阈值,从而自适应地响应不同任务的不同复杂性。通过用多个LoRA专家替换层中的单个LoRA,并集成具有阈值机制的门控函数,AdaMoLE能够根据输入上下文有效地选择和激活最合适的专家。在各种常识推理和自然语言处理任务中的广泛评估表明,AdaMoLE超过了基线性能。这一增强突出了AdaMoLE自适应选择LoRA专家的优势,在不增加专家数量的情况下提高了模型效率。实验验证不仅证实了AdaMoLE是增强LLM的强大方法,而且为自适应专家选择机制的未来研究提出了有价值的方向,有可能扩大优化各种语言处理任务中模型性能的范围。
🔬 方法详解
问题定义:现有的大型语言模型微调方法,特别是基于混合专家模型的方法,通常采用静态的top-k策略来选择激活哪些专家。这种静态选择策略无法根据不同任务的复杂程度进行自适应调整,导致模型在处理某些任务时可能无法充分利用所有专家的能力,或者在处理简单任务时过度激活专家,造成资源浪费。因此,如何设计一种能够自适应选择专家的机制,以提高模型在不同任务上的性能,是本文要解决的核心问题。
核心思路:AdaMoLE的核心思路是引入一个自适应的阈值网络,该网络能够根据输入上下文动态调整每个专家的激活阈值。通过这种方式,模型可以根据任务的复杂程度,自适应地选择激活哪些专家。同时,AdaMoLE还结合了门控函数,进一步优化专家的选择过程,确保选择的专家能够最大程度地提升模型性能。这种自适应选择机制的设计灵感来源于人类的学习过程,即根据问题的难度选择合适的专家进行咨询。
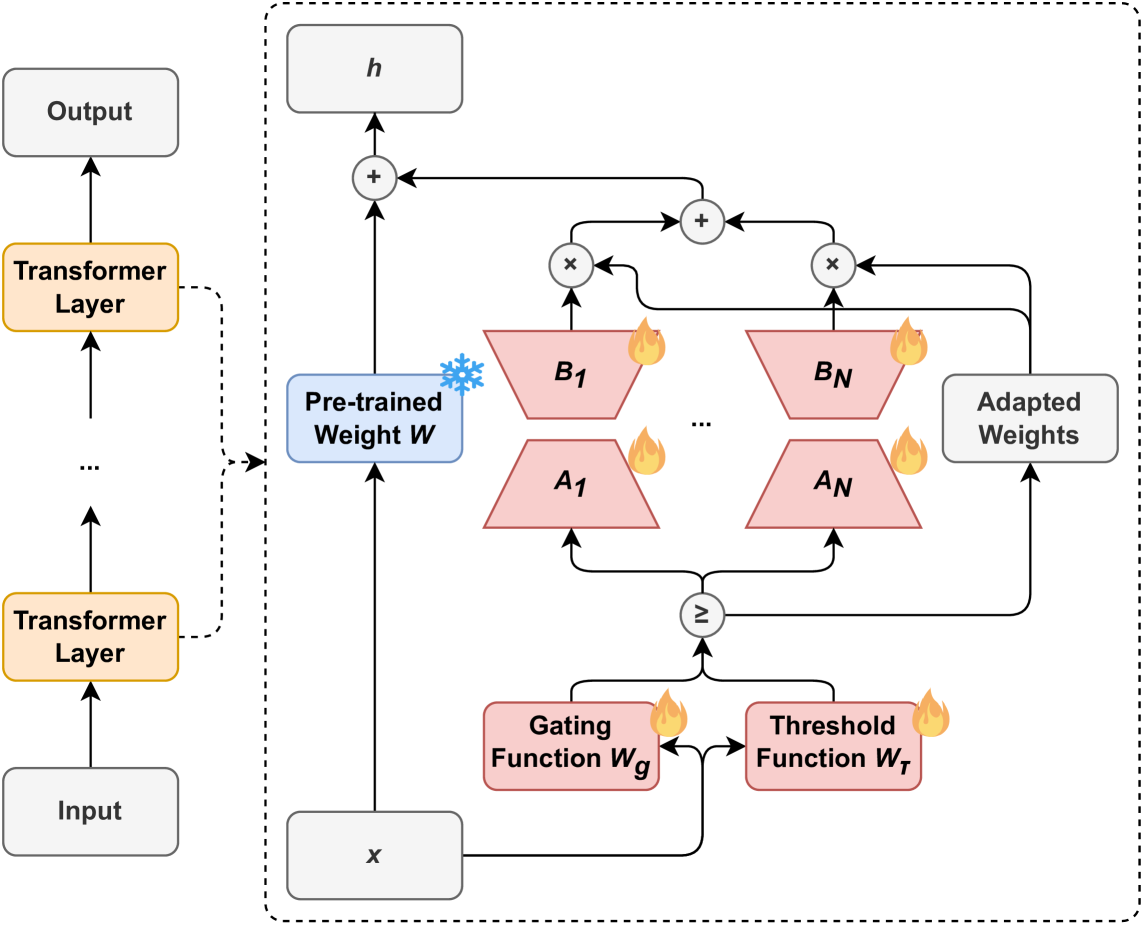
技术框架:AdaMoLE的技术框架主要包括以下几个模块:1) LoRA专家层:将模型中的部分或全部LoRA层替换为多个LoRA专家。2) 门控网络:用于计算每个专家的权重,决定每个专家对最终输出的贡献程度。3) 阈值网络:用于动态调整每个专家的激活阈值,控制专家的激活状态。4) 损失函数:用于训练整个模型,包括LoRA专家、门控网络和阈值网络。整个流程如下:首先,输入数据经过LoRA专家层,每个专家产生一个输出。然后,门控网络根据输入数据计算每个专家的权重。接着,阈值网络根据输入数据动态调整每个专家的激活阈值。最后,根据专家的权重和激活状态,将专家的输出进行加权求和,得到最终的输出。
关键创新:AdaMoLE最重要的技术创新点在于其自适应的专家选择机制。与传统的静态top-k策略不同,AdaMoLE能够根据输入上下文动态调整专家的激活阈值,从而实现更精细化的专家选择。这种自适应选择机制能够更好地适应不同任务的复杂程度,提高模型的泛化能力。此外,AdaMoLE还结合了门控函数,进一步优化专家的选择过程,确保选择的专家能够最大程度地提升模型性能。
关键设计:AdaMoLE的关键设计包括:1) 阈值网络的设计:阈值网络采用一个小型神经网络,输入是LoRA层的输入,输出是每个专家的激活阈值。2) 门控函数的设计:门控函数采用softmax函数,将每个专家的输出转换为权重。3) 损失函数的设计:损失函数包括交叉熵损失和正则化损失,其中交叉熵损失用于训练LoRA专家和门控网络,正则化损失用于防止过拟合。
🖼️ 关键图片
📊 实验亮点
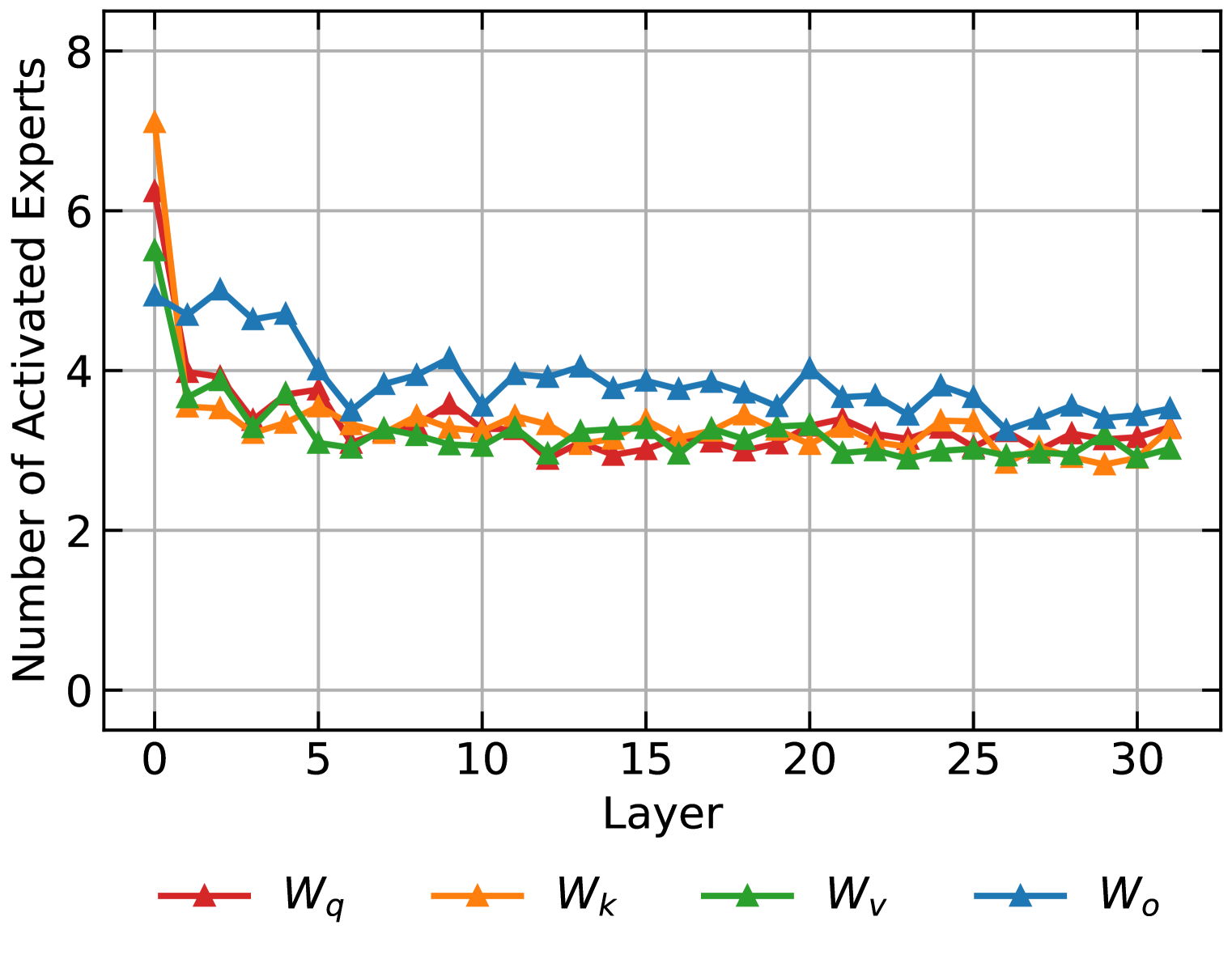
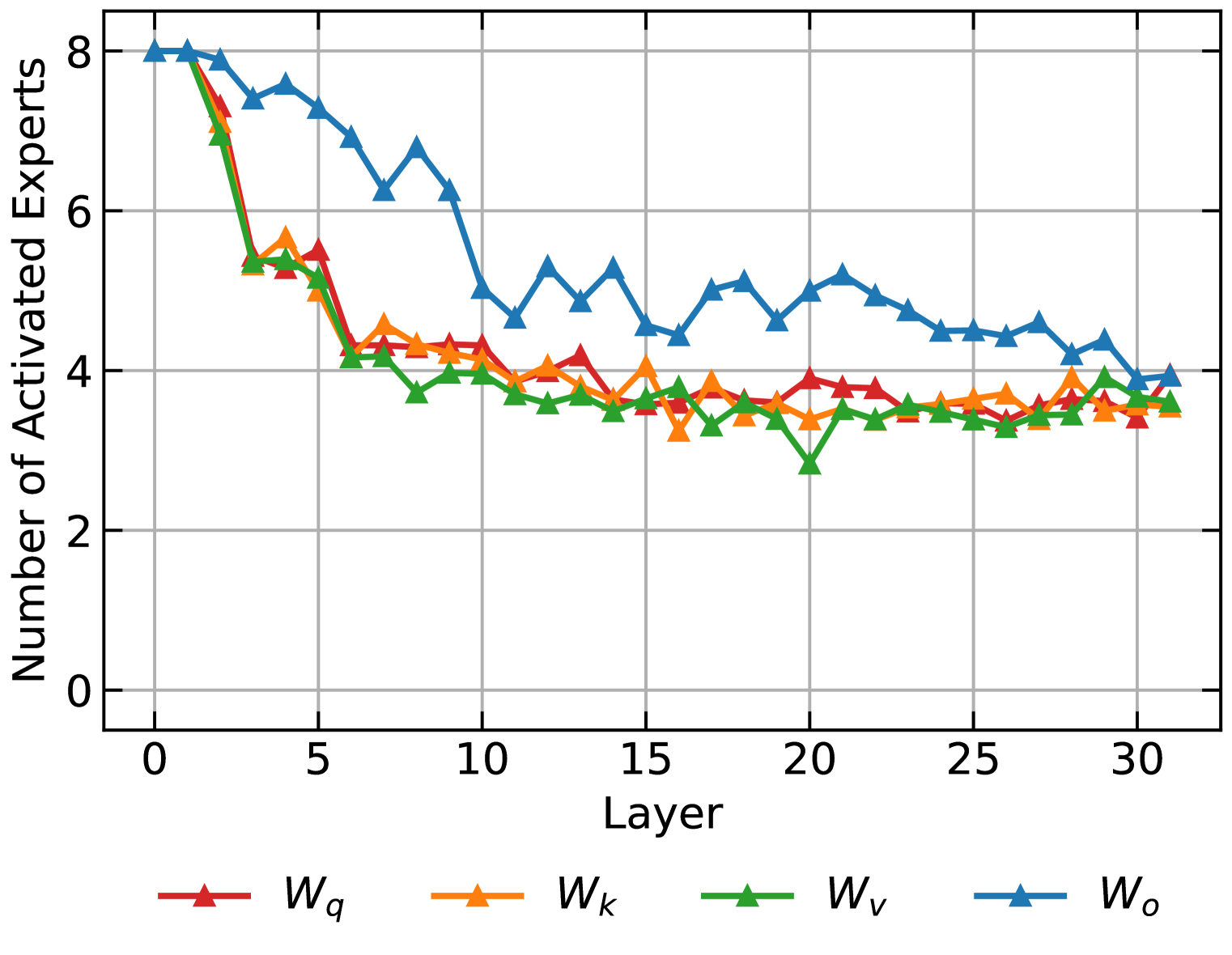
实验结果表明,AdaMoLE在多个常识推理和自然语言处理任务上均取得了显著的性能提升。例如,在CommonsenseQA数据集上,AdaMoLE的准确率比基线模型提高了2-3个百分点。此外,AdaMoLE在不增加专家数量的情况下,仍然能够取得优于基线模型的性能,证明了其自适应专家选择机制的有效性。
🎯 应用场景
AdaMoLE具有广泛的应用前景,可以应用于各种需要微调大型语言模型的场景,例如自然语言处理、机器翻译、文本生成、对话系统等。通过自适应地选择专家,AdaMoLE可以提高模型在不同任务上的性能,并降低计算成本。此外,AdaMoLE还可以应用于知识蒸馏,将大型模型的知识迁移到小型模型中,提高小型模型的性能。
📄 摘要(原文)
We introduce AdaMoLE, a novel method for fine-tuning large language models (LLMs) through an Adaptive Mixture of Low-Rank Adaptation (LoRA) Experts. Moving beyond conventional methods that employ a static top-k strategy for activating experts, AdaMoLE dynamically adjusts the activation threshold using a dedicated threshold network, adaptively responding to the varying complexities of different tasks. By replacing a single LoRA in a layer with multiple LoRA experts and integrating a gating function with the threshold mechanism, AdaMoLE effectively selects and activates the most appropriate experts based on the input context. Our extensive evaluations across a variety of commonsense reasoning and natural language processing tasks show that AdaMoLE exceeds baseline performance. This enhancement highlights the advantages of AdaMoLE's adaptive selection of LoRA experts, improving model effectiveness without a corresponding increase in the expert count. The experimental validation not only confirms AdaMoLE as a robust approach for enhancing LLMs but also suggests valuable directions for future research in adaptive expert selection mechanisms, potentially broadening the scope for optimizing model performance across diverse language processing tasks.