MM-MATH: Advancing Multimodal Math Evaluation with Process Evaluation and Fine-grained Classification
作者: Kai Sun, Yushi Bai, Ji Qi, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2024-04-07 (更新: 2024-07-02)
💡 一句话要点
提出MM-MATH以解决多模态数学推理评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态数学推理 过程评估 模型评估 错误分类 教育技术
📋 核心要点
- 现有的多模态数学推理评估方法主要依赖于简单的答案比较,无法全面评估解题过程。
- 本文提出的MM-MATH基准通过结合结果和过程评估,提供了更为全面的数学推理能力评估。
- 实验结果表明,现有模型在MM-MATH上表现不佳,最佳模型仅达到31%的准确率,显示出显著的改进空间。
📝 摘要(中文)
为推动大型多模态模型(LMMs)在数学推理评估中的应用,本文引入了一个新基准MM-MATH。该基准包含5,929个具有视觉背景的开放式中学数学问题,并在难度、年级和知识点上进行了细粒度分类。与现有基准依赖于二元答案比较不同,MM-MATH结合了结果和过程评估。过程评估利用LMM作为评判者,自动分析解题步骤,识别并分类错误类型。对十种模型在MM-MATH上的广泛评估显示,现有LMM面临显著挑战,尤其在视觉信息的利用和高难度问题的解决上。表现最佳的模型在MM-MATH上的准确率仅为31%,而人类为82%,显示出当前模型与人类在多模态推理能力上的显著差距。
🔬 方法详解
问题定义:本文旨在解决现有多模态数学推理评估方法的不足,特别是缺乏对解题过程的深入分析和评估。现有方法主要依赖于二元答案比较,无法有效识别解题中的错误类型和原因。
核心思路:论文提出MM-MATH基准,通过引入过程评估,利用LMM作为评判者,自动分析解题步骤,识别错误类型,从而实现更全面的数学推理能力评估。
技术框架:整体架构包括数据集构建、过程评估模块和模型评估模块。数据集构建阶段涉及5,929个数学问题的设计,过程评估模块负责分析解题步骤,模型评估模块则对不同LMM进行性能评估。
关键创新:最重要的技术创新在于结合了结果和过程评估,尤其是通过LMM自动分析解题步骤,识别和分类错误类型,这与现有方法的单一答案比较形成了本质区别。
关键设计:在模型评估中,设置了多个难度级别和知识点,采用了细粒度分类方法,确保评估的全面性和准确性。
🖼️ 关键图片
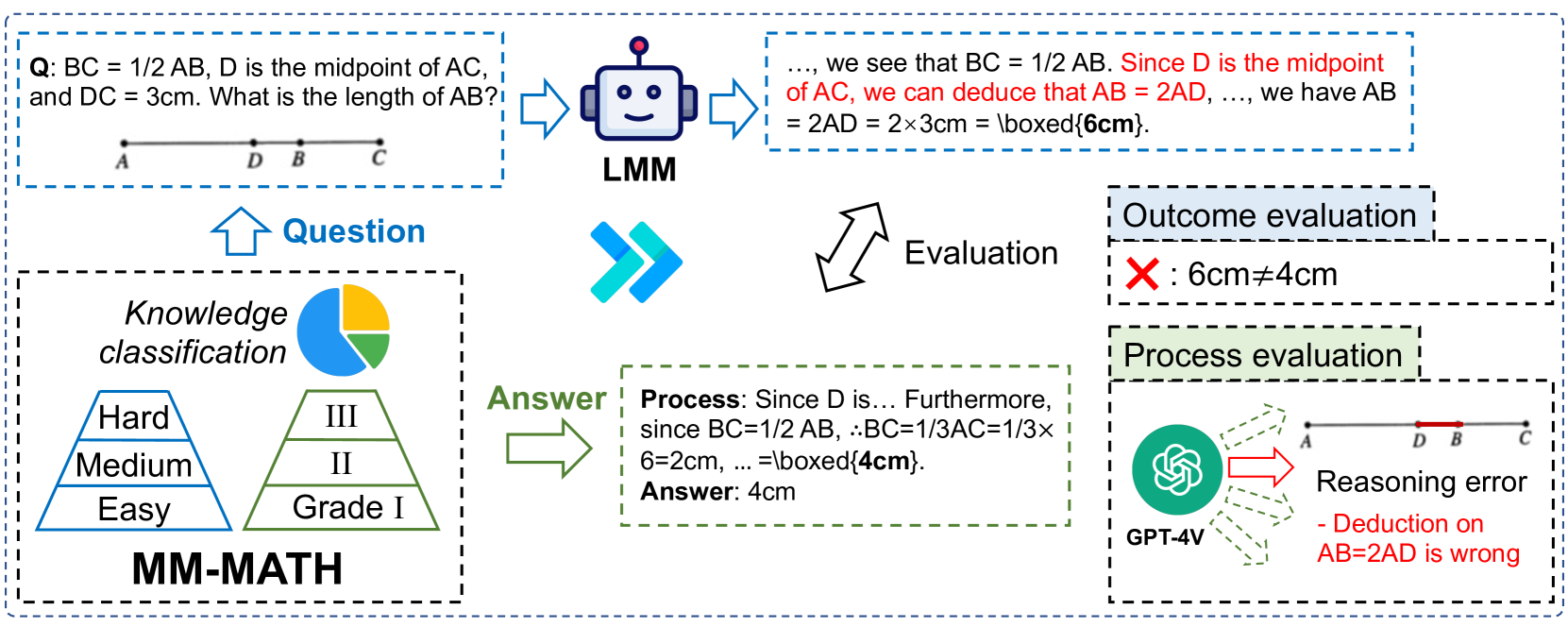
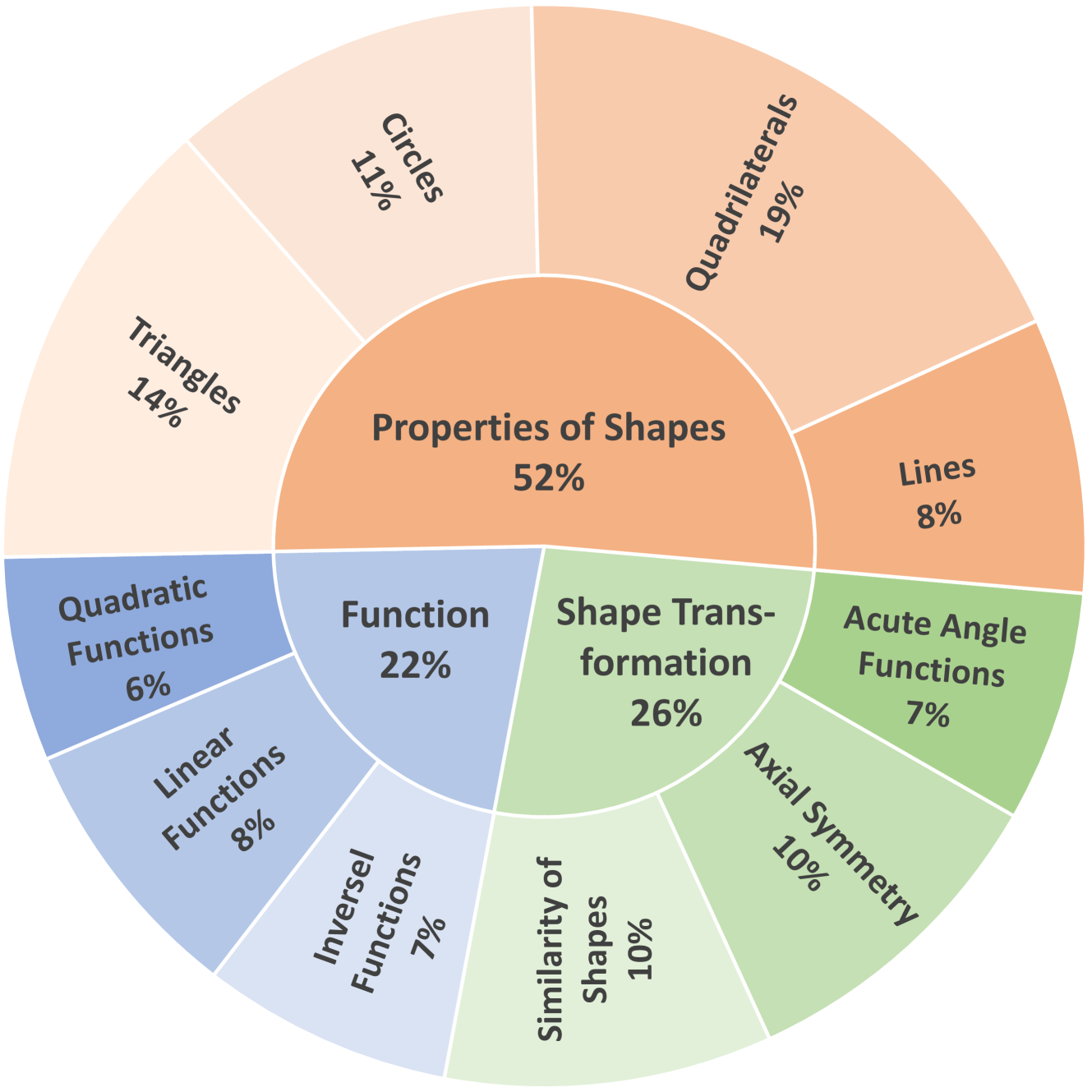
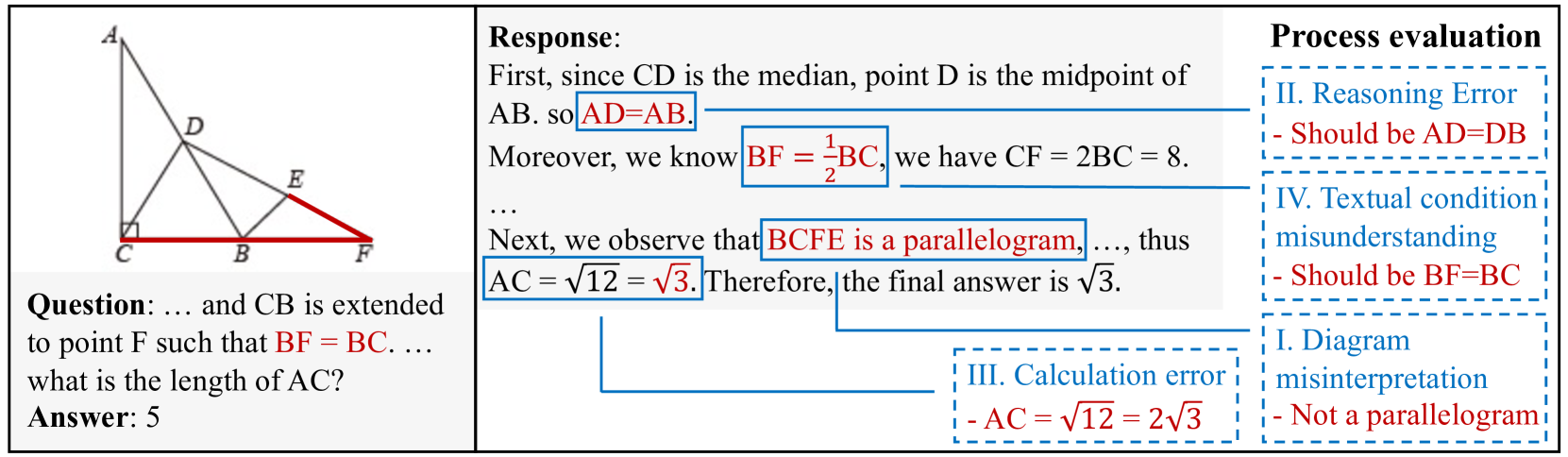
📊 实验亮点
实验结果显示,现有模型在MM-MATH基准上的表现不佳,最佳模型的准确率仅为31%,而人类的准确率达到82%。这表明当前模型在处理高难度问题和视觉信息利用方面存在显著挑战,强调了该基准的难度和重要性。
🎯 应用场景
该研究的潜在应用领域包括教育技术、智能辅导系统和数学教育评估工具。通过更准确的数学推理能力评估,教育者可以更好地理解学生的学习过程,从而制定个性化的教学策略,提升学习效果。未来,该基准可能推动多模态模型在教育领域的广泛应用。
📄 摘要(原文)
To advance the evaluation of multimodal math reasoning in large multimodal models (LMMs), this paper introduces a novel benchmark, MM-MATH. MM-MATH consists of 5,929 open-ended middle school math problems with visual contexts, with fine-grained classification across difficulty, grade level, and knowledge points. Unlike existing benchmarks relying on binary answer comparison, MM-MATH incorporates both outcome and process evaluations. Process evaluation employs LMM-as-a-judge to automatically analyze solution steps, identifying and categorizing errors into specific error types. Extensive evaluation of ten models on MM-MATH reveals significant challenges for existing LMMs, highlighting their limited utilization of visual information and struggles with higher-difficulty problems. The best-performing model achieves only 31% accuracy on MM-MATH, compared to 82% for humans. This highlights the challenging nature of our benchmark for existing models and the significant gap between the multimodal reasoning capabilities of current models and humans. Our process evaluation reveals that diagram misinterpretation is the most common error, accounting for more than half of the total error cases, underscoring the need for improved image comprehension in multimodal reasoning.