SilverSight: A Multi-Task Chinese Financial Large Language Model Based on Adaptive Semantic Space Learning
作者: Yuhang Zhou, Zeping Li, Siyu Tian, Yuchen Ni, Sen Liu, Guangnan Ye, Hongfeng Chai
分类: cs.CL, cs.CE
发布日期: 2024-04-07
备注: 17 pages, 17 figures
💡 一句话要点
提出自适应语义空间学习框架以提升金融领域多任务LLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自适应学习 金融领域 多任务学习 数据重组 模型泛化 性能提升
📋 核心要点
- 现有大型语言模型在金融领域的多任务学习中面临数据异质性和任务迁移冲突的问题。
- 本文提出的自适应语义空间学习框架,通过重组数据分布,提升了多专家模型的性能和选择效率。
- 实验结果显示,使用10%的数据,模型性能接近全数据训练,且具有良好的泛化能力。
📝 摘要(中文)
大型语言模型(LLMs)在各个专业领域的应用日益广泛,利用其丰富的知识支持多种场景。然而,各领域的特定任务多样且数据异质性可能导致模型任务迁移时的冲突。为应对这一挑战,本文提出了一种自适应语义空间学习(ASSL)框架,通过在语义空间内自适应重组数据分布,提升多专家模型的性能和选择效率。基于该框架,我们训练了名为“SilverSight”的金融多任务LLM。研究结果表明,使用仅10%的数据,该框架的表现接近于全数据训练,同时展现出强大的泛化能力。
🔬 方法详解
问题定义:本文旨在解决金融领域多任务学习中由于数据异质性导致的模型任务迁移冲突问题。现有方法在处理不同任务时,往往无法有效利用有限的数据,导致性能下降。
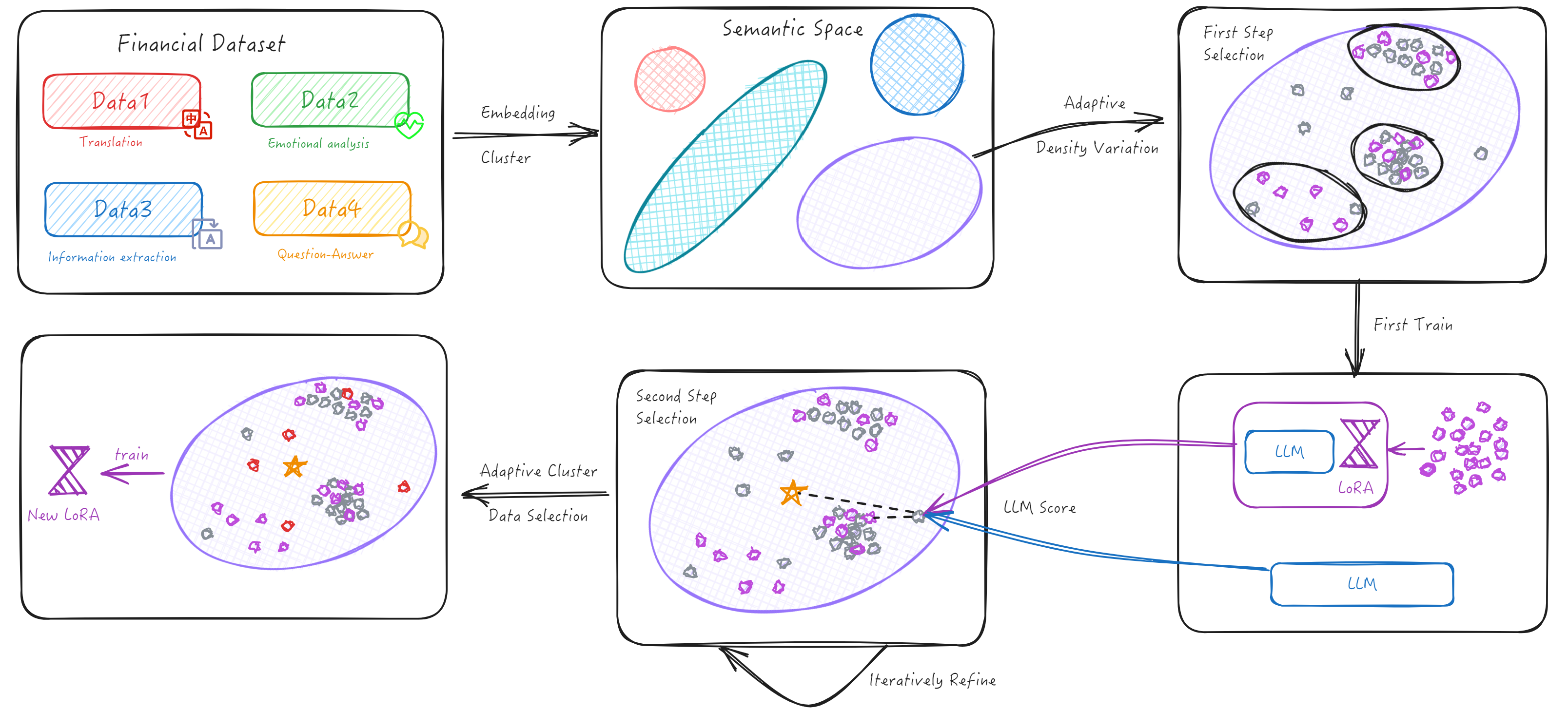
核心思路:提出自适应语义空间学习(ASSL)框架,通过对数据分布的自适应重组,优化多专家模型的学习过程,从而提升模型在多任务场景下的表现。
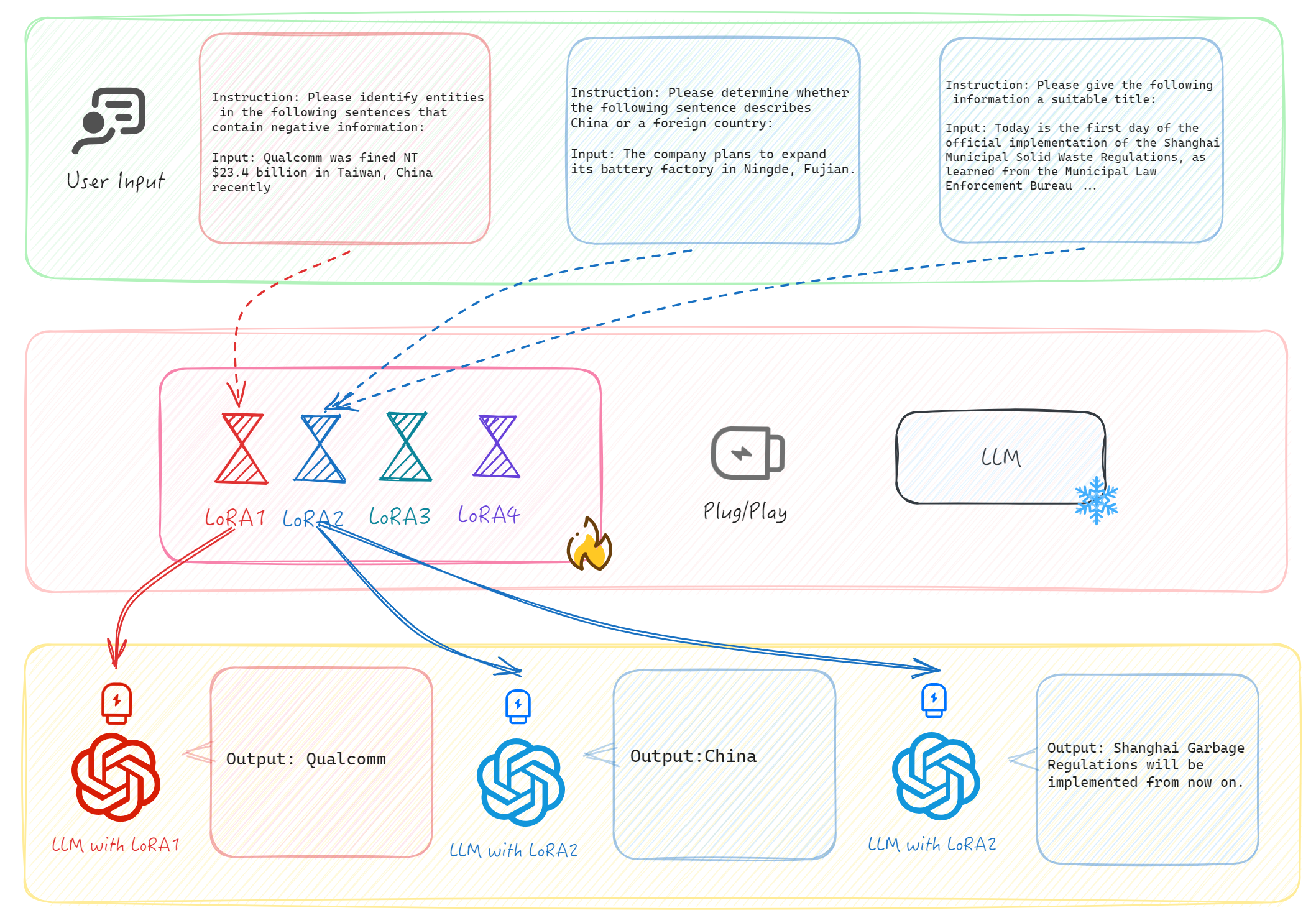
技术框架:该框架包括数据重组模块、模型训练模块和性能评估模块。数据重组模块负责根据任务需求调整数据分布,模型训练模块则利用重组后的数据进行训练,最后通过评估模块验证模型的泛化能力。
关键创新:最重要的创新在于自适应重组数据分布的机制,使得模型能够在多任务学习中更有效地利用有限的数据,显著提升了模型的选择效率和性能。
关键设计:在模型设计中,采用了特定的损失函数以平衡不同任务的学习目标,并通过调节超参数来优化模型的训练过程,确保模型在多任务学习中的稳定性和有效性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SilverSight在仅使用10%的数据时,其性能接近于全数据训练的模型,展现出强大的泛化能力。这一成果在金融领域的多任务学习中具有显著的提升幅度,验证了ASSL框架的有效性。
🎯 应用场景
该研究的潜在应用场景包括金融分析、风险评估、投资决策等领域。通过提升多任务学习的效率,SilverSight能够为金融机构提供更精准的决策支持,降低数据处理成本,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) are increasingly being applied across various specialized fields, leveraging their extensive knowledge to empower a multitude of scenarios within these domains. However, each field encompasses a variety of specific tasks that require learning, and the diverse, heterogeneous data across these domains can lead to conflicts during model task transfer. In response to this challenge, our study introduces an Adaptive Semantic Space Learning (ASSL) framework, which utilizes the adaptive reorganization of data distributions within the semantic space to enhance the performance and selection efficacy of multi-expert models. Utilizing this framework, we trained a financial multi-task LLM named "SilverSight". Our research findings demonstrate that our framework can achieve results close to those obtained with full data training using only 10% of the data, while also exhibiting strong generalization capabilities.