Radial Networks: Dynamic Layer Routing for High-Performance Large Language Models
作者: Jordan Dotzel, Yash Akhauri, Ahmed S. AbouElhamayed, Carly Jiang, Mohamed Abdelfattah, Zhiru Zhang
分类: cs.CL
发布日期: 2024-04-07
备注: First two authors have equal contribution
💡 一句话要点
提出Radial Networks以解决大语言模型的动态层稀疏问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 动态层稀疏 大语言模型 计算效率 资源优化 深度学习
📋 核心要点
- 现有的大语言模型在处理内存和计算资源时面临挑战,尤其是在层数不断增加的情况下。
- 本文提出Radial Networks,通过动态层稀疏和令牌级路由,优化了模型的计算效率和资源使用。
- 实验结果表明,Radial Networks在计算和服务成本上显著降低,同时保持了模型的容量和性能。
📝 摘要(中文)
大语言模型(LLMs)在内存、延迟和功耗方面面临严格的需求。为满足这些需求,提出了各种动态稀疏方法,以输入为基础减少计算。本文探讨了动态层稀疏的实用性,通过分析残差连接,建立了模型深度与层稀疏之间的关系。提出的Radial Networks通过训练的路由模块在层之间进行令牌级路由,能够在不增加层数的情况下扩展模型规模,并减少生成整个序列所需的资源,从而实现更高效的计算和服务成本。
🔬 方法详解
问题定义:本文旨在解决大语言模型在内存和计算资源方面的高需求问题,现有的静态方法无法有效利用输入间的差异,导致资源浪费。
核心思路:通过引入动态层稀疏,Radial Networks能够在模型运行时根据输入动态选择计算层,从而提高计算效率和降低资源消耗。
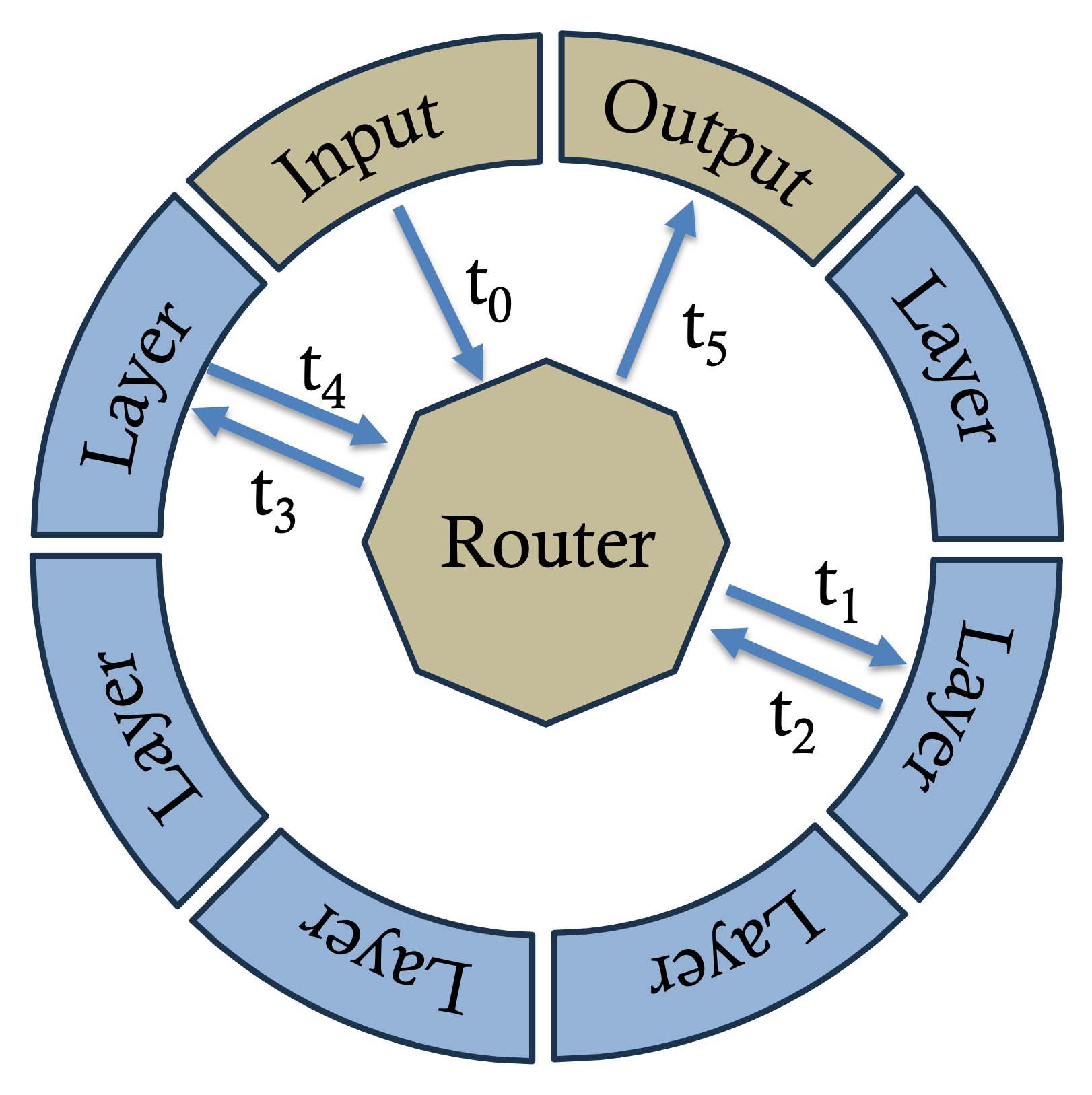
技术框架:Radial Networks的整体架构包括一个训练的路由模块,该模块负责在不同层之间进行令牌级路由。模型可以通过后训练蒸馏或从头训练来共同学习路由和层权重。
关键创新:最重要的创新在于动态层稀疏的实现,允许模型在深度和计算需求之间解耦,显著提升了模型的灵活性和效率。
关键设计:在设计中,模型的残差块贡献被分析,发现其对输出的中位贡献仅为5%。通过这种分析,优化了层的使用和计算资源的分配。具体的损失函数和网络结构设计也为动态稀疏提供了支持。
🖼️ 关键图片


📊 实验亮点
实验结果显示,Radial Networks在计算和服务成本上显著降低,具体性能提升幅度未知。通过动态层稀疏,模型能够在保持容量的同时,减少整体计算资源的需求,展现出较传统方法更高的效率。
🎯 应用场景
Radial Networks的研究成果可广泛应用于需要高效计算的大语言模型,如自然语言处理、对话系统和机器翻译等领域。其动态层稀疏的设计能够有效降低计算资源消耗,提升模型的实际应用价值,未来可能推动更大规模模型的开发与应用。
📄 摘要(原文)
Large language models (LLMs) often struggle with strict memory, latency, and power demands. To meet these demands, various forms of dynamic sparsity have been proposed that reduce compute on an input-by-input basis. These methods improve over static methods by exploiting the variance across individual inputs, which has steadily grown with the exponential increase in training data. Yet, the increasing depth within modern models, currently with hundreds of layers, has opened opportunities for dynamic layer sparsity, which skips the computation for entire layers. In this work, we explore the practicality of layer sparsity by profiling residual connections and establish the relationship between model depth and layer sparsity. For example, the residual blocks in the OPT-66B model have a median contribution of 5% to its output. We then take advantage of this dynamic sparsity and propose Radial Networks, which perform token-level routing between layers guided by a trained router module. These networks can be used in a post-training distillation from sequential networks or trained from scratch to co-learn the router and layer weights. They enable scaling to larger model sizes by decoupling the number of layers from the dynamic depth of the network, and their design allows for layer reuse. By varying the compute token by token, they reduce the overall resources needed for generating entire sequences. Overall, this leads to larger capacity networks with significantly lower compute and serving costs for large language models.