Towards Analyzing and Understanding the Limitations of DPO: A Theoretical Perspective
作者: Duanyu Feng, Bowen Qin, Chen Huang, Zheng Zhang, Wenqiang Lei
分类: cs.CL, cs.AI
发布日期: 2024-04-06
备注: Draft version
💡 一句话要点
提出理论框架以分析DPO的局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 大型语言模型 人类偏好对齐 理论分析 优化算法
📋 核心要点
- DPO方法在对齐大型语言模型与人类偏好时存在对SFT有效性敏感及学习能力不足的问题。
- 论文提出了一个基于场论的分析框架,以理论方式分析DPO的优化过程及其局限性。
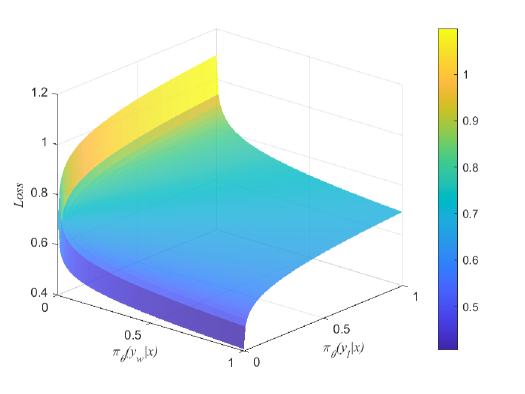
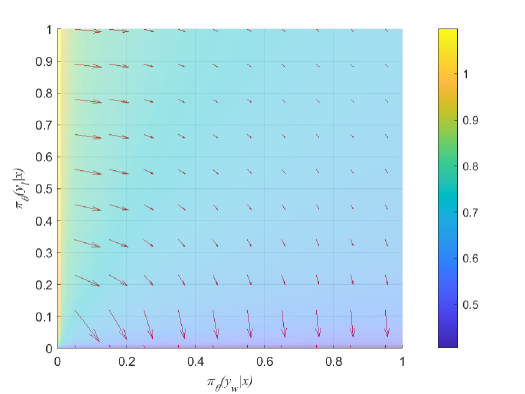
- 通过分析DPO损失函数的梯度,发现其在降低不偏好数据概率方面的效率高于提高偏好数据概率的效率。
📝 摘要(中文)
直接偏好优化(DPO)通过从成对偏好数据中直接推导奖励信号,已在对齐大型语言模型(LLMs)与人类偏好方面显示出有效性。然而,DPO在对SFT有效性的敏感性以及对人类偏好响应学习能力的阻碍方面受到批评,导致性能不尽如人意。为了解决这些局限性,理论理解DPO是不可或缺的,但仍然缺乏。为此,我们采取了一步,理论分析和理解DPO的局限性。具体而言,我们提供了一个使用场论的分析框架来分析DPO的优化过程。通过分析DPO损失函数的梯度向量场,我们发现DPO损失函数以比产生偏好数据更快的速度降低产生人类不偏好数据的概率。这为理解相关研究实验中发现的DPO局限性提供了理论见解,从而为其改进奠定了基础。
🔬 方法详解
问题定义:本论文旨在解决DPO在对齐人类偏好时的局限性,尤其是其对SFT有效性的敏感性和对人类偏好响应学习能力的阻碍,这些问题导致了DPO在实际应用中的性能不佳。
核心思路:通过建立一个理论分析框架,利用场论对DPO的优化过程进行深入分析,旨在揭示其损失函数的特性及其对生成偏好数据的影响,从而为改进DPO提供理论依据。
技术框架:整体架构包括对DPO损失函数的梯度向量场进行分析,主要模块包括损失函数的定义、梯度计算及其对生成数据概率的影响评估。
关键创新:论文的关键创新在于首次将场论应用于DPO的分析,揭示了DPO损失函数在降低不偏好数据生成概率方面的效率高于提高偏好数据生成概率的效率,这一发现为DPO的改进提供了新的视角。
关键设计:在技术细节上,论文详细描述了DPO损失函数的构造及其梯度计算方法,强调了如何通过优化策略调整生成数据的概率分布,以实现更好的对齐效果。
🖼️ 关键图片
📊 实验亮点
通过理论分析,发现DPO损失函数在降低人类不偏好数据生成概率方面的效率显著高于提高偏好数据生成概率的效率。这一发现为DPO的改进提供了重要的理论依据,可能会在后续研究中引领新的优化策略。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、推荐系统和人机交互等。通过深入理解DPO的局限性,未来可以设计出更有效的优化算法,从而提升大型语言模型在实际应用中的表现,增强其与人类偏好的对齐能力。
📄 摘要(原文)
Direct Preference Optimization (DPO), which derives reward signals directly from pairwise preference data, has shown its effectiveness on aligning Large Language Models (LLMs) with human preferences. Despite its widespread use across various tasks, DPO has been criticized for its sensitivity to the SFT's effectiveness and its hindrance to the learning capacity towards human-preferred responses, leading to less satisfactory performance. To overcome those limitations, the theoretical understanding of DPO are indispensable but still lacking. To this end, we take a step towards theoretically analyzing and understanding the limitations of DPO. Specifically, we provide an analytical framework using the field theory to analyze the optimization process of DPO. By analyzing the gradient vector field of the DPO loss function, we find that the DPO loss function decreases the probability of producing human dispreferred data at a faster rate than it increases the probability of producing preferred data. This provides theoretical insights for understanding the limitations of DPO discovered in the related research experiments, thereby setting the foundation for its improvement.