SEME at SemEval-2024 Task 2: Comparing Masked and Generative Language Models on Natural Language Inference for Clinical Trials
作者: Mathilde Aguiar, Pierre Zweigenbaum, Nona Naderi
分类: cs.CL
发布日期: 2024-04-05
💡 一句话要点
比较掩码语言模型与生成语言模型在临床试验自然语言推理中的应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言推理 临床试验 掩码语言模型 生成语言模型 生物医学 模型微调 推理一致性 可信度评估
📋 核心要点
- 现有的自然语言推理模型在临床试验报告中的一致性和可信度评估存在不足,亟需改进。
- 本研究提出了两种方法:一种是微调和集成掩码语言模型,另一种是通过模板提示大型语言模型,旨在提高推理性能。
- 实验结果显示,使用Flan-T5-large模型的2-shot设置取得了0.57的F1得分,0.64的可信度和0.56的一致性,表现优异。
📝 摘要(中文)
本文描述了我们对SemEval-2024任务2的提交,聚焦于安全生物医学自然语言推理在临床试验中的应用。多证据自然语言推理(NLI4CT)任务评估了应用于临床试验报告的自然语言推理模型的一致性和可信度。我们测试了两种不同的方法:一种是基于微调和集成掩码语言模型,另一种是使用模板对大型语言模型进行提示,特别是使用思维链和对比思维链。在2-shot设置下,提示Flan-T5-large模型取得了最佳效果,F1得分为0.57,可信度为0.64,一致性为0.56。
🔬 方法详解
问题定义:本文旨在解决自然语言推理模型在临床试验报告中的一致性和可信度评估问题。现有方法在处理复杂的临床数据时,往往无法有效捕捉信息之间的关系,导致推理结果不够可靠。
核心思路:本研究提出了两种不同的策略:一种是通过微调和集成掩码语言模型来增强模型的推理能力,另一种是利用模板对大型语言模型进行提示,特别是采用思维链和对比思维链的方式,以提高模型的推理准确性。
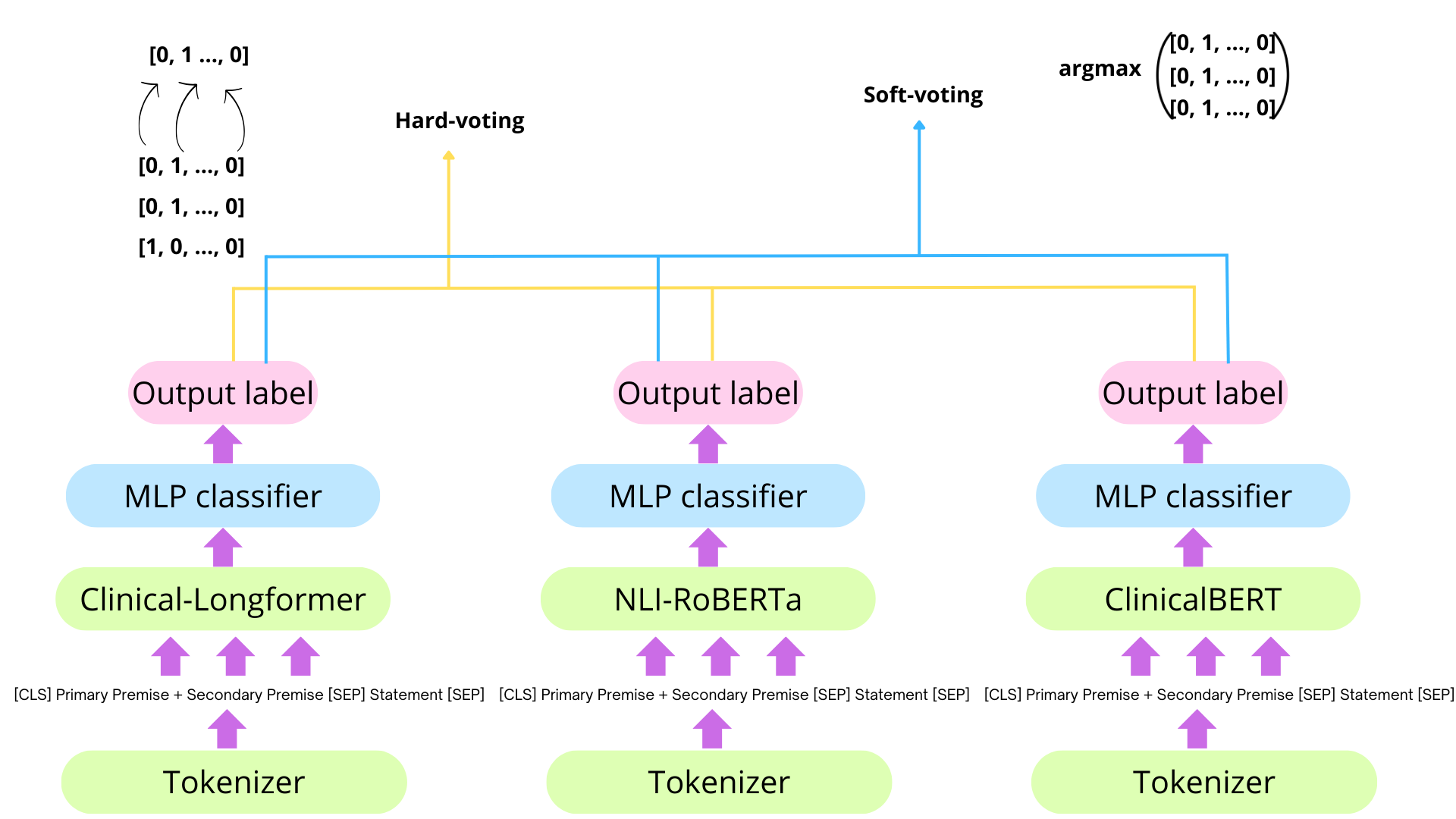
技术框架:整体架构包括两个主要模块:首先是掩码语言模型的微调与集成,其次是大型语言模型的提示机制。通过对比这两种方法的效果,评估各自的优缺点。
关键创新:本研究的创新点在于结合了掩码语言模型的微调与大型语言模型的提示技术,形成了一个多元化的推理框架。这种方法在处理临床试验数据时,能够更好地捕捉文本之间的逻辑关系。
关键设计:在模型训练中,采用了特定的损失函数以优化推理结果,并在参数设置上进行了细致调整,以确保模型在不同任务下的适应性和性能提升。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Flan-T5-large模型的2-shot设置达到了0.57的F1得分,0.64的可信度和0.56的一致性,显著优于传统方法。这一成果展示了大型语言模型在处理复杂临床试验数据时的潜力,为未来的研究提供了新的方向。
🎯 应用场景
该研究的潜在应用领域包括医疗健康、临床试验数据分析和生物医学文献检索等。通过提高自然语言推理模型在临床数据中的表现,可以为临床决策提供更为可靠的支持,进而改善患者的治疗效果和医疗服务质量。未来,该方法有望推广至更广泛的生物医学领域,推动智能医疗的发展。
📄 摘要(原文)
This paper describes our submission to Task 2 of SemEval-2024: Safe Biomedical Natural Language Inference for Clinical Trials. The Multi-evidence Natural Language Inference for Clinical Trial Data (NLI4CT) consists of a Textual Entailment (TE) task focused on the evaluation of the consistency and faithfulness of Natural Language Inference (NLI) models applied to Clinical Trial Reports (CTR). We test 2 distinct approaches, one based on finetuning and ensembling Masked Language Models and the other based on prompting Large Language Models using templates, in particular, using Chain-Of-Thought and Contrastive Chain-Of-Thought. Prompting Flan-T5-large in a 2-shot setting leads to our best system that achieves 0.57 F1 score, 0.64 Faithfulness, and 0.56 Consistency.