Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction
作者: Bowen Zhang, Harold Soh
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-04-05 (更新: 2024-10-02)
备注: 18 pages, 3 figures, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
🔗 代码/项目: GITHUB
💡 一句话要点
提出EDC框架以解决知识图谱构建中的复杂模式问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱 自动化构建 大型语言模型 信息提取 模式生成 机器学习
📋 核心要点
- 现有知识图谱构建方法在处理复杂文本时面临模式限制,导致无法有效提取信息。
- 提出的EDC框架通过开放信息提取、模式定义和后期规范化,灵活应对有无预定义模式的情况。
- 实验结果显示,EDC在多个基准测试中提取的三元组质量显著提高,且无需参数调优。
📝 摘要(中文)
本研究关注从输入文本中自动创建知识图谱(KGC)的方法。尽管大型语言模型(LLMs)在小型特定领域数据集上取得了一定成功,但在处理复杂的现实应用文本时仍面临挑战。现有方法要求在LLM提示中包含KG模式,导致较大的模式超出LLM的上下文窗口。为了解决这些问题,本文提出了一个名为Extract-Define-Canonicalize(EDC)的三阶段框架,能够在有无预定义模式的情况下灵活应用,并通过自生成模式和后期规范化构建高质量的知识图谱。实验表明,EDC在三个KGC基准上能够提取高质量的三元组,且无需参数调优,支持更大规模的模式。
🔬 方法详解
问题定义:本论文旨在解决现有知识图谱构建方法在处理复杂文本时的局限性,尤其是对大型模式的支持不足,导致信息提取效果不佳。
核心思路:提出的EDC框架通过三个阶段(提取、定义、规范化)来自动构建知识图谱,能够在缺乏预定义模式的情况下自生成模式,从而提高灵活性和适应性。
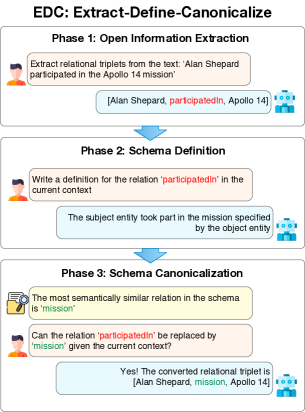
技术框架:EDC框架分为三个主要模块:第一阶段为开放信息提取,提取文本中的关键信息;第二阶段为模式定义,构建适合提取信息的模式;第三阶段为后期规范化,确保生成的知识图谱符合标准。
关键创新:EDC的创新在于其灵活性,能够在有无预定义模式的情况下自动生成模式,并通过自我规范化提升知识图谱的质量。这一设计与传统方法的依赖于固定模式的方式形成鲜明对比。
关键设计:在EDC框架中,特别设计了一个训练组件,用于检索与输入文本相关的模式元素,从而增强LLM的提取性能,类似于检索增强生成的方式。
🖼️ 关键图片
📊 实验亮点
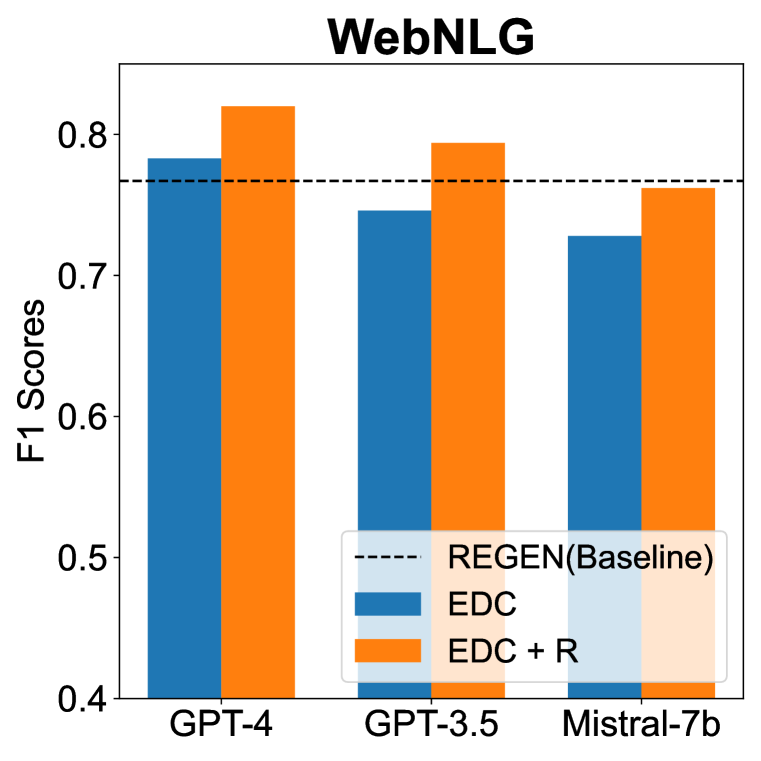
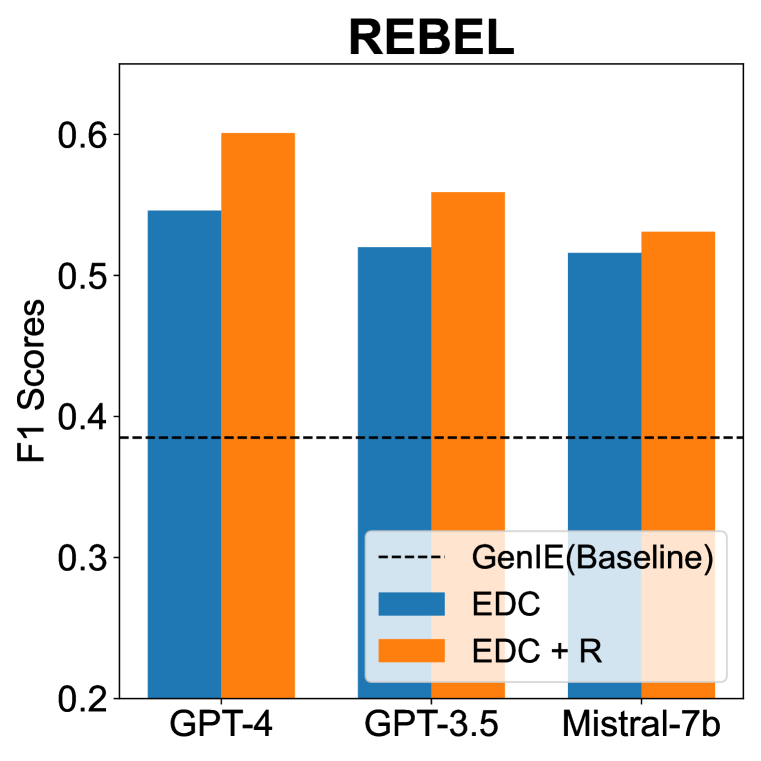
在三个知识图谱构建基准测试中,EDC框架成功提取高质量的三元组,且无需任何参数调优。与以往方法相比,EDC能够处理更大规模的模式,显著提升了信息提取的效果,展示了其在实际应用中的潜力。
🎯 应用场景
该研究的潜在应用领域包括信息检索、智能问答系统和数据集成等。通过自动构建知识图谱,能够有效支持企业在数据管理和决策支持中的需求,提升信息处理的效率和准确性。未来,该框架有望在更广泛的领域中推广应用,推动知识图谱技术的发展。
📄 摘要(原文)
In this work, we are interested in automated methods for knowledge graph creation (KGC) from input text. Progress on large language models (LLMs) has prompted a series of recent works applying them to KGC, e.g., via zero/few-shot prompting. Despite successes on small domain-specific datasets, these models face difficulties scaling up to text common in many real-world applications. A principal issue is that, in prior methods, the KG schema has to be included in the LLM prompt to generate valid triplets; larger and more complex schemas easily exceed the LLMs' context window length. Furthermore, there are scenarios where a fixed pre-defined schema is not available and we would like the method to construct a high-quality KG with a succinct self-generated schema. To address these problems, we propose a three-phase framework named Extract-Define-Canonicalize (EDC): open information extraction followed by schema definition and post-hoc canonicalization. EDC is flexible in that it can be applied to settings where a pre-defined target schema is available and when it is not; in the latter case, it constructs a schema automatically and applies self-canonicalization. To further improve performance, we introduce a trained component that retrieves schema elements relevant to the input text; this improves the LLMs' extraction performance in a retrieval-augmented generation-like manner. We demonstrate on three KGC benchmarks that EDC is able to extract high-quality triplets without any parameter tuning and with significantly larger schemas compared to prior works. Code for EDC is available at https://github.com/clear-nus/edc.