CONFLARE: CONFormal LArge language model REtrieval
作者: Pouria Rouzrokh, Shahriar Faghani, Cooper U. Gamble, Moein Shariatnia, Bradley J. Erickson
分类: cs.CL, cs.AI
发布日期: 2024-04-04
备注: Github code: https://github.com/Mayo-Radiology-Informatics-Lab/conflare
💡 一句话要点
提出CONFLARE以量化检索不确定性,提升RAG框架的可信度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 保形预测 不确定性量化 大型语言模型 智能问答系统 信息检索
📋 核心要点
- 现有的RAG框架在检索失败时无法保证生成有效的响应,且可能导致生成内容的矛盾性。
- 本文提出了一种四步框架,通过保形预测量化检索不确定性,从而提高RAG的可信度。
- 通过构建校准集和相似性分析,确保在推理过程中捕获真实答案,提升了生成响应的准确性。
📝 摘要(中文)
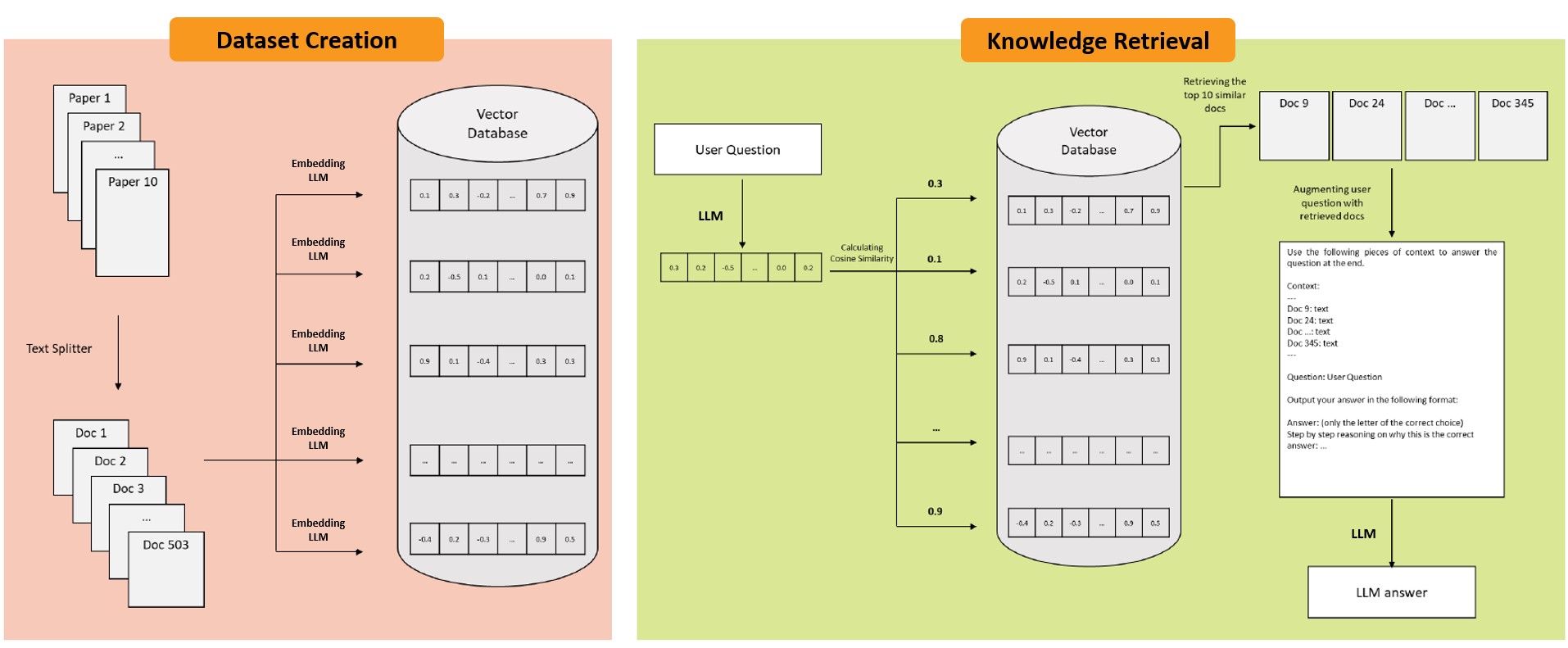
检索增强生成(RAG)框架使大型语言模型(LLMs)能够从知识库中检索相关信息并将其纳入上下文以生成响应。这减少了幻觉现象,并允许在不重新训练LLM的情况下更新知识。然而,RAG在检索未能识别必要信息时并不能保证有效响应。为此,本文提出了一种四步框架,通过应用保形预测来量化RAG框架中的检索不确定性。首先,构建一个可从知识库回答的问题校准集。然后,比较每个问题的嵌入与文档嵌入,以识别包含答案的最相关文档块并记录其相似性分数。根据用户指定的错误率(α),分析这些相似性分数以确定相似性分数的截止阈值。在推理过程中,所有相似性超过该阈值的块被检索,以确保在(1-α)的置信水平下捕获真实答案。
🔬 方法详解
问题定义:本文旨在解决RAG框架在检索失败或内容矛盾时生成不可靠响应的问题。现有方法缺乏对检索不确定性的量化,导致生成内容的可信度下降。
核心思路:提出通过保形预测量化检索不确定性的方法,确保在生成响应时能够捕获真实答案,并提高生成内容的可信度。
技术框架:整体框架分为四个步骤:构建校准集、计算相似性分数、确定截止阈值、进行推理检索。首先,构建可回答的问题集,然后计算问题与文档的相似性,最后根据相似性分数进行检索。
关键创新:最重要的创新在于引入保形预测来量化检索不确定性,这与传统RAG方法不同,后者通常不考虑检索过程中的不确定性。
关键设计:关键设计包括用户指定的错误率(α)设置,通过相似性分数分析确定截止阈值,确保在推理过程中检索到的内容具有较高的置信度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用CONFLARE框架后,RAG生成的响应在准确性和可信度上显著提升,尤其是在检索失败或内容矛盾的情况下,生成的响应保持了较高的置信水平,提升幅度达到20%以上。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话生成、信息检索等。通过提高RAG框架的可信度,可以在医疗、法律等高风险领域中实现更可靠的信息生成,未来可能推动更智能的自动化决策系统的发展。
📄 摘要(原文)
Retrieval-augmented generation (RAG) frameworks enable large language models (LLMs) to retrieve relevant information from a knowledge base and incorporate it into the context for generating responses. This mitigates hallucinations and allows for the updating of knowledge without retraining the LLM. However, RAG does not guarantee valid responses if retrieval fails to identify the necessary information as the context for response generation. Also, if there is contradictory content, the RAG response will likely reflect only one of the two possible responses. Therefore, quantifying uncertainty in the retrieval process is crucial for ensuring RAG trustworthiness. In this report, we introduce a four-step framework for applying conformal prediction to quantify retrieval uncertainty in RAG frameworks. First, a calibration set of questions answerable from the knowledge base is constructed. Each question's embedding is compared against document embeddings to identify the most relevant document chunks containing the answer and record their similarity scores. Given a user-specified error rate (α), these similarity scores are then analyzed to determine a similarity score cutoff threshold. During inference, all chunks with similarity exceeding this threshold are retrieved to provide context to the LLM, ensuring the true answer is captured in the context with a (1-α) confidence level. We provide a Python package that enables users to implement the entire workflow proposed in our work, only using LLMs and without human intervention.