An Investigation into Misuse of Java Security APIs by Large Language Models
作者: Zahra Mousavi, Chadni Islam, Kristen Moore, Alsharif Abuadbba, Muhammad Ali Babar
分类: cs.CR, cs.CL, cs.CY
发布日期: 2024-04-04
备注: This paper has been accepted by ACM ASIACCS 2024
💡 一句话要点
评估大型语言模型在Java安全API生成中的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全API 代码生成 软件安全 漏洞检测 ChatGPT 编程任务
📋 核心要点
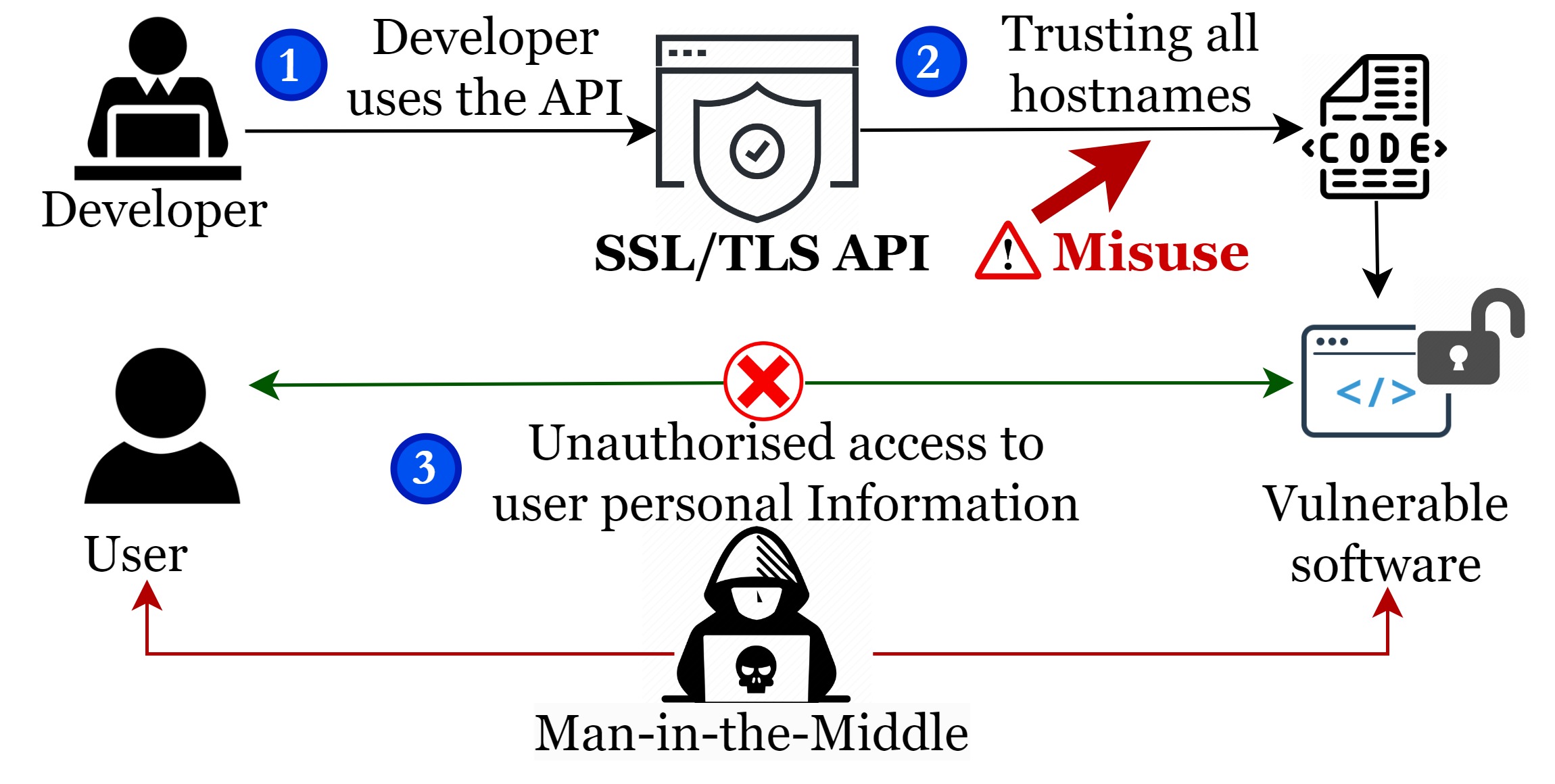
- 现有方法在安全API的有效整合上面临重大挑战,导致开发者可能无意中滥用API,从而引发安全漏洞。
- 本文通过系统评估ChatGPT在Java安全API代码生成中的可信度,提出了一种全面的评估方法。
- 实验结果显示,约70%的生成代码存在安全API滥用,部分任务的滥用率高达100%,表明当前LLMs在此领域的可靠性不足。
📝 摘要(中文)
随着大型语言模型(LLMs)在代码生成中的使用日益增加,其生成可信代码的能力引发了关注。尽管许多研究者探讨了代码生成在发现软件漏洞中的应用,但安全应用程序接口(API)的有效整合仍面临重大挑战,导致开发者可能无意中滥用这些API,从而使软件暴露于漏洞之中。本文系统评估了ChatGPT在Java安全API用例中的代码生成可信度,编制了48个编程任务的广泛集合,采用自动化和手动方法检测生成代码中的安全API滥用。研究发现,约70%的代码实例存在安全API滥用,且在约一半的任务中滥用率达到100%。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在生成Java安全API代码时的滥用问题。现有方法未能有效识别和防止安全API的错误使用,导致软件安全性降低。
核心思路:通过系统评估ChatGPT生成的代码,识别安全API的滥用情况,提供针对性的改进建议,以提高生成代码的安全性和可靠性。
技术框架:研究首先编制了48个编程任务,涵盖5个广泛使用的安全API。接着,采用自动化和手动相结合的方法,检测生成代码中的安全API滥用。
关键创新:本文的主要创新在于系统性地评估了LLMs在安全API代码生成中的表现,识别了20种不同的滥用类型,填补了现有研究的空白。
关键设计:在实验中,设置了多种编程任务,采用了自动化检测工具和人工审查相结合的方式,以确保对安全API滥用的全面识别。
🖼️ 关键图片


📊 实验亮点
实验结果显示,在30次任务尝试中,约70%的代码实例存在安全API滥用,且在近一半的任务中滥用率达到100%。这些发现表明,当前的LLMs在安全API代码生成方面的可靠性亟待提升。
🎯 应用场景
该研究的潜在应用领域包括软件开发、代码审查和安全性评估等。通过提高大型语言模型在安全API生成中的可靠性,能够有效减少软件漏洞,提升整体软件安全性,具有重要的实际价值和未来影响。
📄 摘要(原文)
The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.