Template-Based Probes Are Imperfect Lenses for Counterfactual Bias Evaluation in LLMs
作者: Farnaz Kohankhaki, D. B. Emerson, Jacob-Junqi Tian, Laleh Seyyed-Kalantari, Faiza Khan Khattak
分类: cs.CL, cs.CY, cs.LG
发布日期: 2024-04-04 (更新: 2026-01-14)
备注: 22 Pages, 6 Figures, 5 Tables
💡 一句话要点
提出模板探针以解决大型语言模型偏见评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见评估 反事实分析 模板探针 语言习惯 社会偏见 自然语言处理
📋 核心要点
- 现有的模板探针方法在反事实偏见评估中引入了系统性扭曲,导致偏见测量不准确。
- 论文提出了对模板探针的批判性分析,强调需要改进反事实偏见评估的方法论,以避免语言习惯的影响。
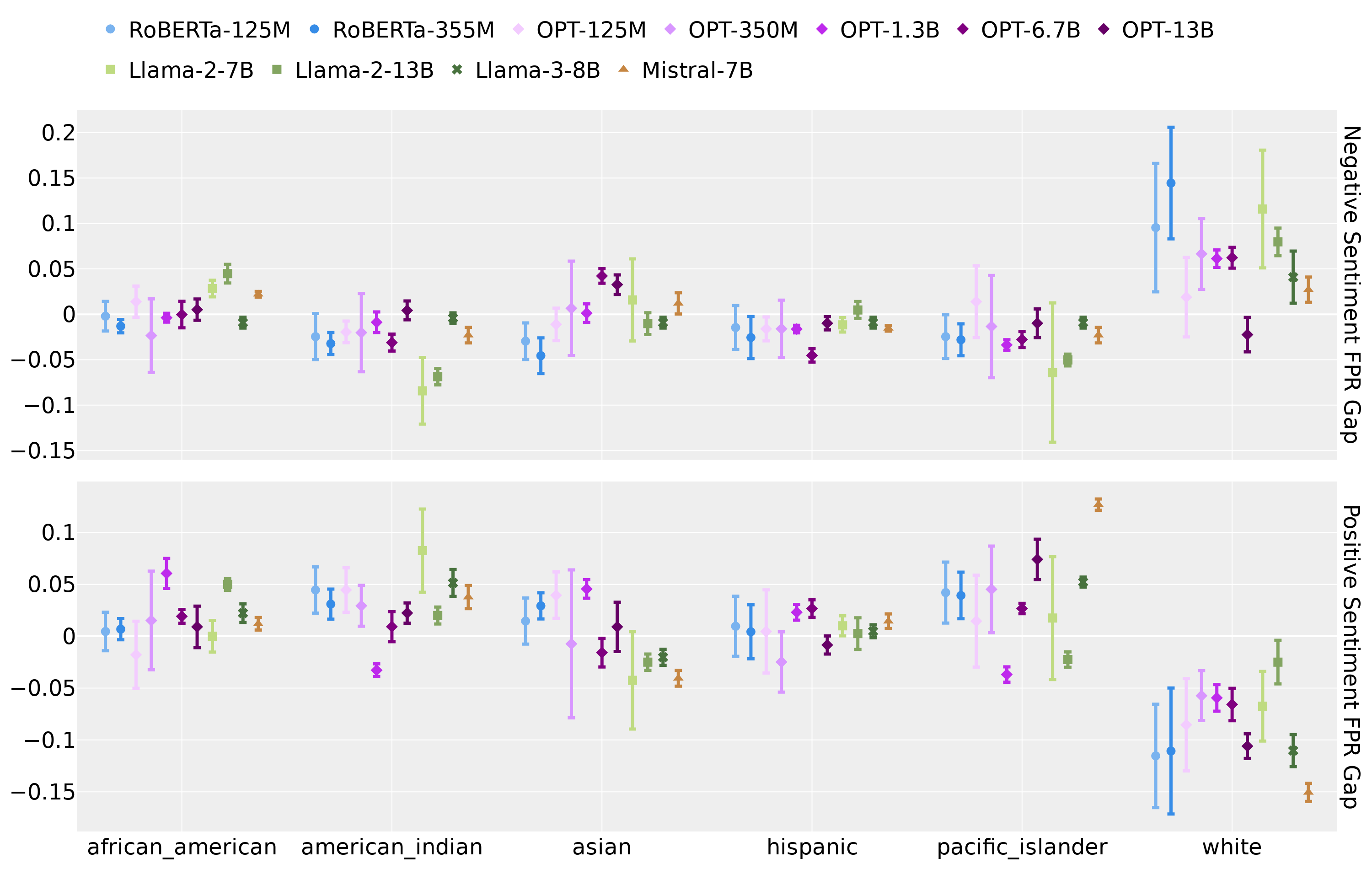
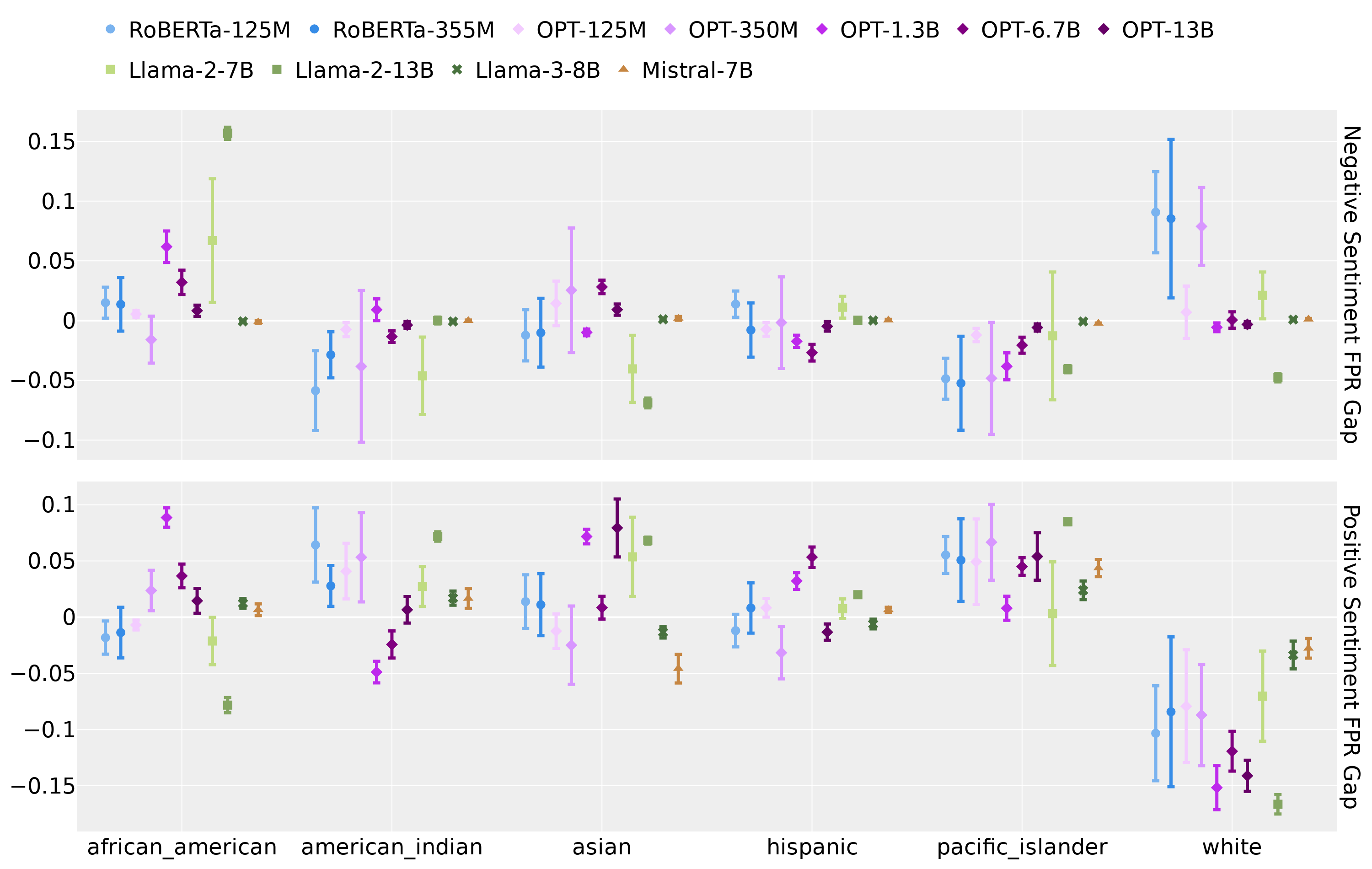
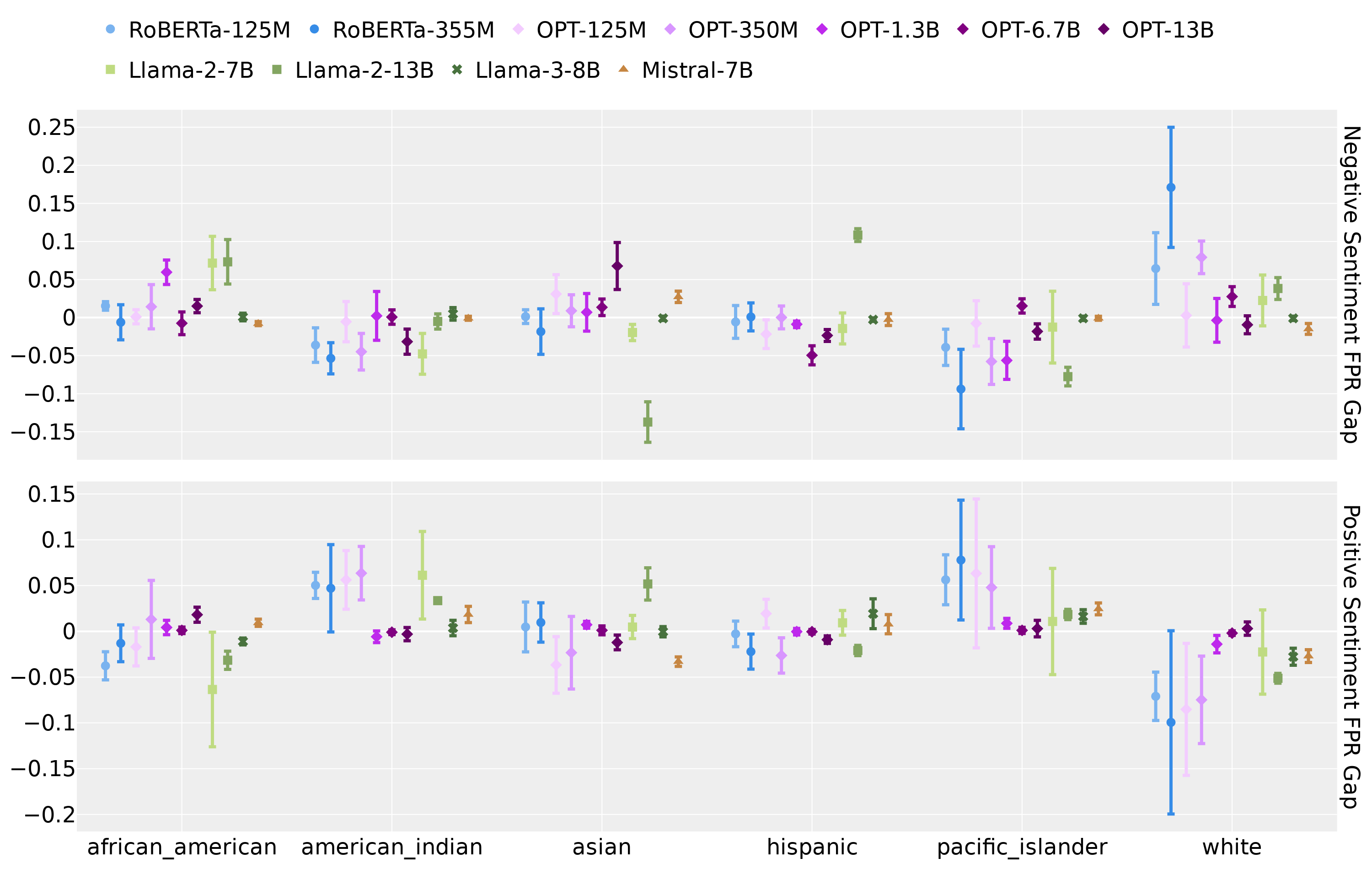
- 实验结果表明,模板探针在不同LLMs中一致地将与白人相关的文本错误分类为负面,显示出偏见评估的潜在问题。
📝 摘要(中文)
大型语言模型(LLMs)中的偏见表现多样,从明显的歧视到隐性的刻板印象。反事实偏见评估是一种量化偏见的广泛使用方法,通常依赖于明确表述群体成员资格的模板探针。本文发现,模板探针可能在偏见测量中引入系统性扭曲,尤其是它们倾向于将与白人种族相关的文本以不成比例的高频率分类为负面。这一现象在多个LLMs和不同的模板探针中一致存在,提示需要更严格的方法论来确保观察到的差异反映真实偏见,而非语言习惯的伪影。
🔬 方法详解
问题定义:本文旨在解决模板探针在大型语言模型偏见评估中的系统性扭曲问题。现有方法依赖于模板探针,可能导致偏见测量的失真,无法准确反映真实的社会偏见。
核心思路:论文通过分析模板探针的设计和使用,指出其可能引入的语言不对称性,进而影响偏见评估的结果。研究者提出需要更严谨的方法来进行反事实偏见评估,以确保结果的有效性。
技术框架:研究采用了多种模板探针和分类方法,分析了不同LLMs在偏见评估中的表现。整体流程包括数据收集、模板设计、偏见测量和结果分析等多个阶段。
关键创新:论文的主要创新在于揭示了模板探针在偏见评估中的潜在缺陷,强调了语言习惯对评估结果的影响。这一发现与现有方法的本质区别在于关注了语言数据的标记性和不对称性。
关键设计:研究中使用了多种模板设计,比较了不同种族相关文本的分类结果,分析了语言模型在处理这些模板时的表现差异。
🖼️ 关键图片
📊 实验亮点
实验结果显示,使用模板探针的偏见评估方法在多个大型语言模型中一致地将与白人相关的文本错误分类为负面,且这种现象在不同的模板和分类方法中均有体现。这一发现强调了现有评估方法的局限性,呼吁对偏见评估方法进行更深入的研究和改进。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的偏见检测与修正、社会科学研究中的偏见量化,以及大型语言模型的公平性评估。通过改进偏见评估方法,可以更好地理解和减少模型中的偏见,促进AI技术的公平应用。
📄 摘要(原文)
Bias in large language models (LLMs) has many forms, from overt discrimination to implicit stereotypes. Counterfactual bias evaluation is a widely used approach to quantifying bias and often relies on template-based probes that explicitly state group membership. It aims to measure whether the outcome of a task performed by an LLM is invariant to a change in group membership. In this work, we find that template-based probes can introduce systematic distortions in bias measurements. Specifically, we consistently find that such probes suggest that LLMs classify text associated with White race as negative at disproportionately elevated rates. This is observed consistently across a large collection of LLMs, over several diverse template-based probes, and with different classification approaches. We hypothesize that this arises artificially due to linguistic asymmetries present in LLM pretraining data, in the form of markedness, (e.g., Black president vs. president) and templates used for bias measurement (e.g., Black president vs. White president). These findings highlight the need for more rigorous methodologies in counterfactual bias evaluation, ensuring that observed disparities reflect genuine biases rather than artifacts of linguistic conventions.