Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
作者: Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
分类: cs.CL, cs.AI
发布日期: 2024-04-04
备注: This paper is accepted to LREC-COLING 2024
💡 一句话要点
提出LM-Guided CoT框架以提升大语言模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 推理能力 知识蒸馏 强化学习 问答系统 多跳推理
📋 核心要点
- 现有的大语言模型在推理任务中表现出色,但其黑箱特性使得理解和优化变得困难,且资源消耗较大。
- 论文提出的LM-Guided CoT框架通过轻量级语言模型生成推理依据,指导大语言模型进行任务预测,从而提高推理效率。
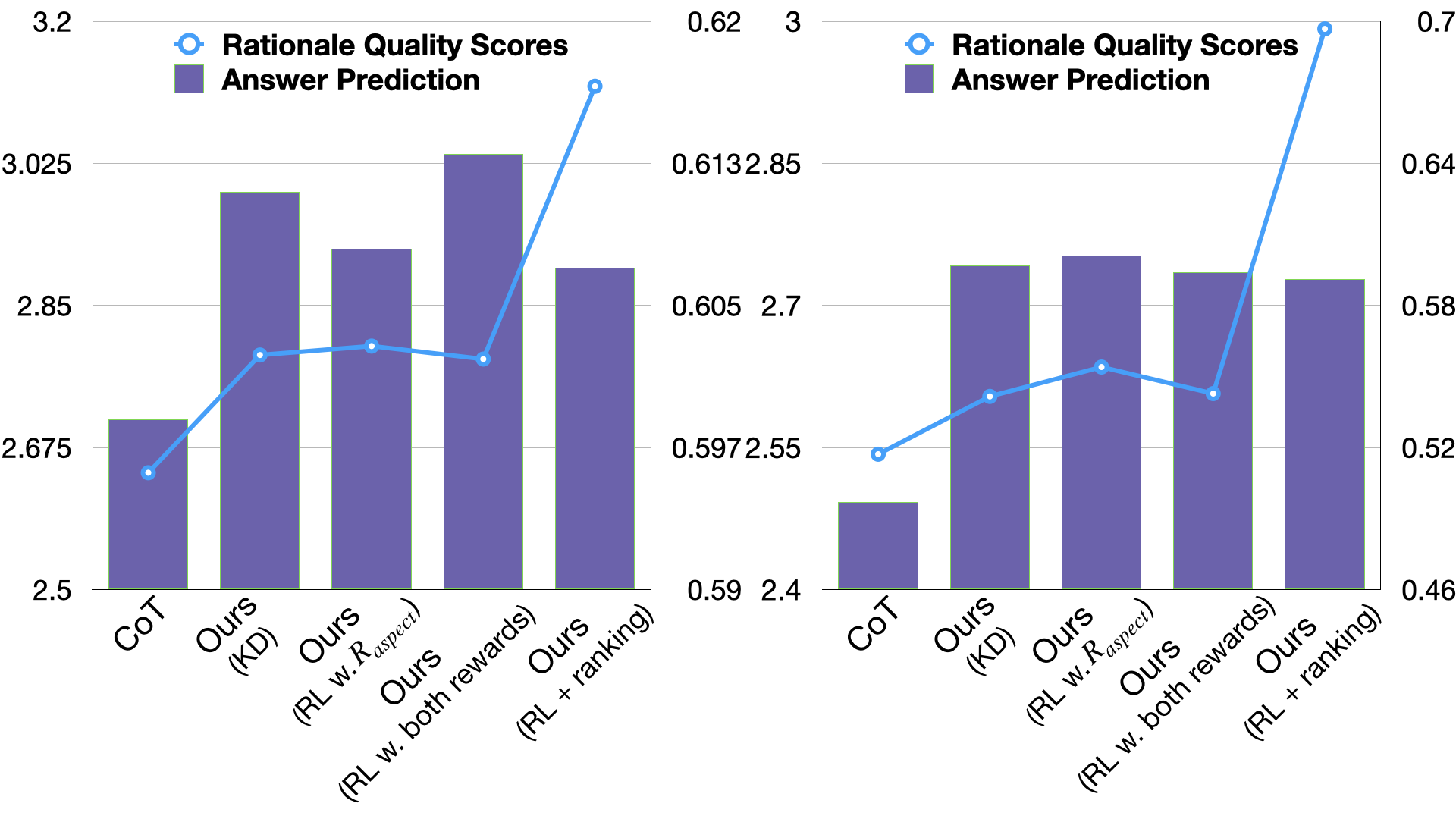
- 实验结果显示,该方法在多个问答基准上优于现有方法,且强化学习显著提升了推理依据的质量和问答性能。
📝 摘要(中文)
本文介绍了一种新颖的框架LM-Guided CoT,该框架利用一个轻量级(<1B参数)语言模型来指导一个黑箱大语言模型(>10B参数)进行推理任务。具体而言,轻量级语言模型首先为每个输入实例生成推理依据,随后冻结的大语言模型根据该推理依据进行任务输出预测。该方法在资源使用上高效,仅需训练轻量级语言模型。我们通过知识蒸馏和基于推理和任务导向奖励信号的强化学习来优化模型。实验结果表明,该方法在多跳抽取式问答基准HotpotQA和2WikiMultiHopQA上超越了所有基线,且强化学习有助于生成更高质量的推理依据,从而提升问答性能。
🔬 方法详解
问题定义:本文旨在解决大语言模型在推理任务中的黑箱特性和高资源消耗问题。现有方法往往难以优化且缺乏透明性。
核心思路:LM-Guided CoT框架通过轻量级语言模型生成推理依据,进而指导大语言模型进行任务输出预测。这种设计使得推理过程更加高效且易于理解。
技术框架:该框架主要包括两个阶段:首先,轻量级语言模型生成推理依据;其次,冻结的大语言模型根据该依据进行任务输出预测。优化过程通过知识蒸馏和强化学习进行。
关键创新:最重要的创新在于将轻量级语言模型与大语言模型结合,通过生成推理依据来提升后者的推理能力,这在现有方法中尚属首次。
关键设计:在模型训练中,采用了知识蒸馏技术来传递轻量级模型的知识,同时使用强化学习来优化推理依据的质量,确保最终的问答性能得到提升。具体的损失函数和奖励信号设计也对模型性能至关重要。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LM-Guided CoT框架在HotpotQA和2WikiMultiHopQA基准上均超越了所有基线模型,问答预测准确率显著提高。强化学习的引入使得推理依据的质量得到提升,从而进一步改善了问答性能。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话系统以及任何需要推理能力的自然语言处理任务。通过提升大语言模型的推理能力,能够在教育、医疗、法律等多个行业中提供更为精准和高效的服务,未来可能对人机交互产生深远影响。
📄 摘要(原文)
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.