An Incomplete Loop: Instruction Inference, Instruction Following, and In-context Learning in Language Models
作者: Emmy Liu, Graham Neubig, Jacob Andreas
分类: cs.CL
发布日期: 2024-04-03 (更新: 2024-08-20)
备注: COLM 2024
💡 一句话要点
探讨语言模型中的指令推理与学习机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 指令推理 少量示例学习 推理机制 自然语言处理
📋 核心要点
- 现有语言模型在不同推理方式下的学习能力存在显著差异,导致其在某些任务上表现不佳。
- 论文提出通过分析指令跟随、少量示例提示和指令推理三种学习方式,探讨它们之间的关系与差异。
- 实验结果显示,语言模型在少量示例提示下能够有效学习,而在理解人类生成的任务描述时却可能失败。
📝 摘要(中文)
现代语言模型(LMs)能够通过不同方式学习新任务,包括指令跟随、少量示例提示和指令推理。指令跟随涉及演绎推理,少量示例提示涉及归纳推理,而指令推理则涉及溯因推理。研究发现,这些推理能力之间存在显著的分离:语言模型在少量示例提示下有时能有效学习,而在无法解释自身预测规则时,反之亦然。这表明即使在当前最大的语言模型中,推理的非系统性特征依然存在,且看似相似的提示程序可能调用不同的学习机制。
🔬 方法详解
问题定义:本论文旨在探讨语言模型在指令跟随、少量示例提示和指令推理三种学习方式下的表现差异。现有方法未能系统性地理解这些推理能力之间的关系,导致模型在某些任务上表现不佳。
核心思路:论文通过对四种语言模型(来自gpt和llama系列)在算术函数和机器翻译任务上的表现进行比较,分析不同推理方式的有效性和局限性。
技术框架:研究设计包括对不同推理方式的实验设置,分别测试指令跟随、少量示例提示和指令推理的效果,比较它们在相同任务上的表现差异。
关键创新:本研究的创新点在于揭示了语言模型在不同推理方式下的非系统性学习特征,强调了看似相似的提示程序可能激活不同的学习机制。
关键设计:实验中使用了多种语言模型,设置了不同的任务描述方式,采用了标准的评估指标来衡量模型的学习效果和推理能力。具体参数设置和损失函数的选择未在摘要中详细说明。
🖼️ 关键图片

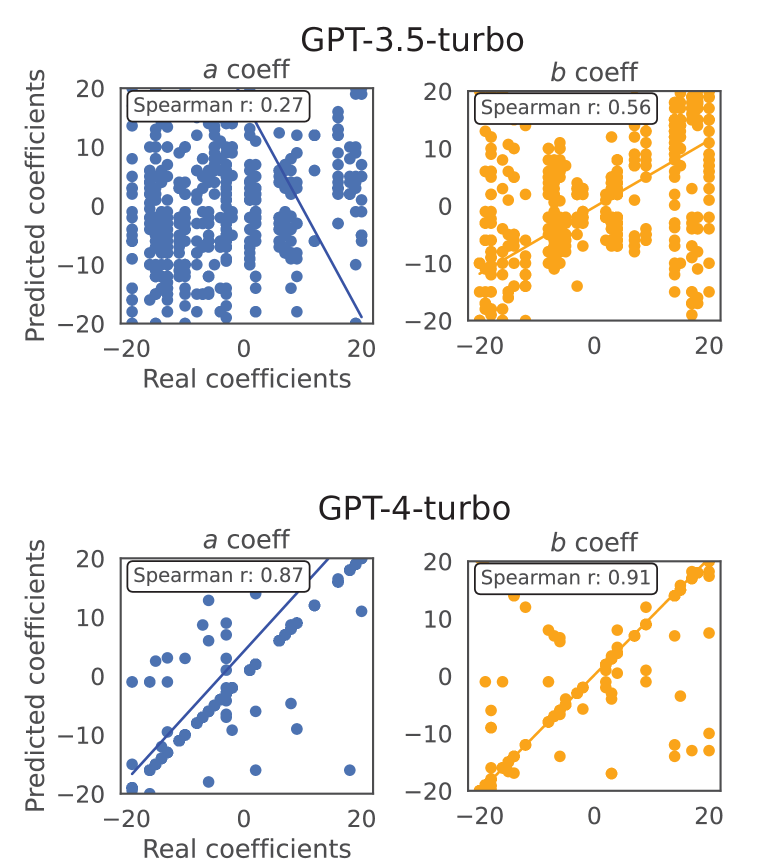

📊 实验亮点
实验结果显示,语言模型在少量示例提示下的学习效果显著,尽管在某些情况下无法解释其预测规则。此外,模型在推理任务中能够生成有效的任务描述,但在学习人类生成的描述时却表现不佳,显示出推理能力的复杂性。
🎯 应用场景
该研究为语言模型的设计和优化提供了重要的理论基础,尤其是在自然语言处理和人机交互等领域。通过理解不同推理方式的特性,可以更好地开发出适应多样化任务的智能系统,提升其在实际应用中的表现。
📄 摘要(原文)
Modern language models (LMs) can learn to perform new tasks in different ways: in instruction following, the target task is described explicitly in natural language; in few-shot prompting, the task is specified implicitly with a small number of examples; in instruction inference, LMs are presented with in-context examples and are then prompted to generate a natural language task description before making predictions. Each of these procedures may be thought of as invoking a different form of reasoning: instruction following involves deductive reasoning, few-shot prompting involves inductive reasoning, and instruction inference involves abductive reasoning. How do these different capabilities relate? Across four LMs (from the gpt and llama families) and two learning problems (involving arithmetic functions and machine translation) we find a strong dissociation between the different types of reasoning: LMs can sometimes learn effectively from few-shot prompts even when they are unable to explain their own prediction rules; conversely, they sometimes infer useful task descriptions while completely failing to learn from human-generated descriptions of the same task. Our results highlight the non-systematic nature of reasoning even in some of today's largest LMs, and underscore the fact that very different learning mechanisms may be invoked by seemingly similar prompting procedures.