Evaluating Large Language Models Using Contrast Sets: An Experimental Approach
作者: Manish Sanwal
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-04-02 (更新: 2024-10-02)
期刊: Article ID: IJAIRD_02_02_007, Volume 2, Issue 2, July-Dec 2024, pp. 90-97
💡 一句话要点
提出对比集生成方法以提升自然语言推理模型评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言推理 对比集生成 模型评估 语言理解 ELECTRA模型
📋 核心要点
- 现有的交叉熵损失指标在评估模型理解语言蕴含能力时存在显著不足,无法有效区分真正的语言理解与模式识别。
- 本研究提出了一种通过同义词自动替换生成对比集的方法,以评估模型的语言理解能力,旨在提高NLI任务的评估标准。
- 实验结果显示,ELECTRA-small模型在对比集上的准确率显著低于传统数据集,经过微调后准确率有所提升,表明对比集的有效性。
📝 摘要(中文)
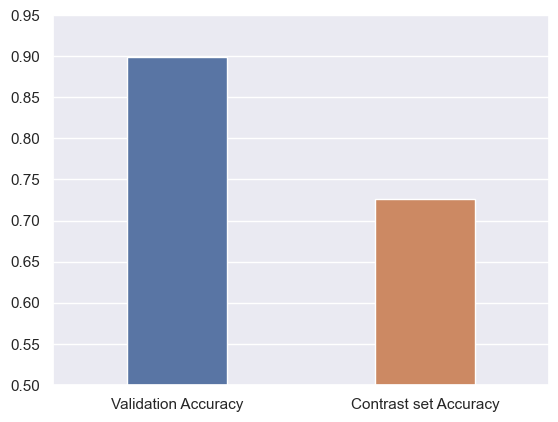
在自然语言推理(NLI)领域,尤其是涉及多输入文本分类的任务中,交叉熵损失指标被广泛使用。然而,该指标在有效评估模型理解语言蕴含能力方面存在不足。本研究提出了一种创新的对比集生成技术,针对斯坦福自然语言推理(SNLI)数据集,通过自动替换动词、副词和形容词的同义词来保持句子的原意。我们使用ELECTRA-small模型进行分析,发现其在传统SNLI数据集上的准确率为89.9%,而在对比集上的准确率降至72.5%,显示出17%的显著下降。为此,我们通过对比增强训练数据集对模型进行微调,使其在对比集上的准确率提升至85.5%。我们的研究强调了在NLI任务中引入多样化语言表达的重要性,期望能促进更具包容性的数据集创建,从而推动NLI模型的更高效发展。
🔬 方法详解
问题定义:本研究旨在解决现有自然语言推理模型在评估语言理解能力时的不足,特别是交叉熵损失指标无法有效反映模型的真实理解能力。
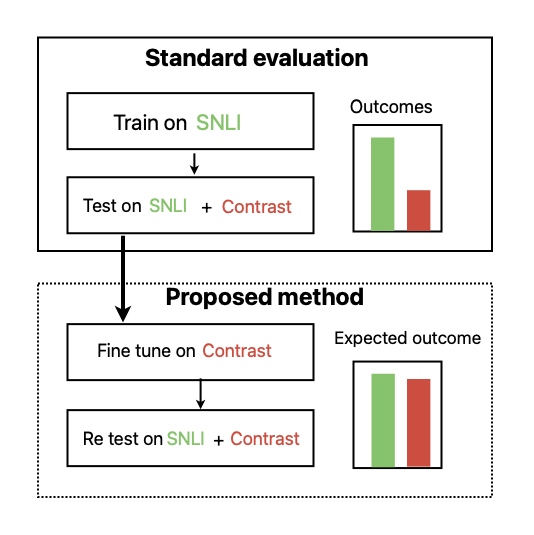
核心思路:论文提出通过自动替换动词、副词和形容词的同义词生成对比集,以保持句子原意,从而评估模型是否依赖于真正的语言理解而非简单的模式识别。
技术框架:整体流程包括对SNLI数据集的对比集生成、模型训练与评估。主要模块包括同义词替换算法、模型训练过程及性能评估。
关键创新:最重要的技术创新在于对比集的生成方法,通过同义词替换保持句子原意,能够有效评估模型的语言理解能力,与传统方法相比,更能揭示模型的真实表现。
关键设计:在模型训练中,采用了ELECTRA-small架构,使用交叉熵损失函数进行优化,并通过对比增强训练数据集进行微调,提升模型在对比集上的表现。具体参数设置和训练细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果显示,ELECTRA-small模型在传统SNLI数据集上的准确率为89.9%,而在对比集上的准确率降至72.5%,下降幅度达到17%。经过微调后,模型在对比集上的准确率提升至85.5%,表明对比集的有效性和重要性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、机器翻译和对话系统等。通过引入对比集生成方法,可以提升模型在复杂语言理解任务中的表现,促进更高效的NLI模型开发,具有重要的实际价值和未来影响。
📄 摘要(原文)
In the domain of Natural Language Inference (NLI), especially in tasks involving the classification of multiple input texts, the Cross-Entropy Loss metric is widely employed as a standard for error measurement. However, this metric falls short in effectively evaluating a model's capacity to understand language entailments. In this study, we introduce an innovative technique for generating a contrast set for the Stanford Natural Language Inference (SNLI) dataset. Our strategy involves the automated substitution of verbs, adverbs, and adjectives with their synonyms to preserve the original meaning of sentences. This method aims to assess whether a model's performance is based on genuine language comprehension or simply on pattern recognition. We conducted our analysis using the ELECTRA-small model. The model achieved an accuracy of 89.9% on the conventional SNLI dataset but showed a reduced accuracy of 72.5% on our contrast set, indicating a substantial 17% decline. This outcome led us to conduct a detailed examination of the model's learning behaviors. Following this, we improved the model's resilience by fine-tuning it with a contrast-enhanced training dataset specifically designed for SNLI, which increased its accuracy to 85.5% on the contrast sets. Our findings highlight the importance of incorporating diverse linguistic expressions into datasets for NLI tasks. We hope that our research will encourage the creation of more inclusive datasets, thereby contributing to the development of NLI models that are both more sophisticated and effective.