LLM Attributor: Interactive Visual Attribution for LLM Generation
作者: Seongmin Lee, Zijie J. Wang, Aishwarya Chakravarthy, Alec Helbling, ShengYun Peng, Mansi Phute, Duen Horng Chau, Minsuk Kahng
分类: cs.CL, cs.AI, cs.HC, cs.LG
发布日期: 2024-04-01
备注: 8 pages, 3 figures, For a video demo, see https://youtu.be/mIG2MDQKQxM
💡 一句话要点
提出LLM Attributor以解决LLM文本生成的可追溯性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本生成 可追溯性 交互式可视化 模型可信度 数据归因 LLaMA2
📋 核心要点
- 现有大型语言模型在文本生成的可追溯性方面存在不足,难以理解生成过程中的数据来源。
- LLM Attributor通过交互式可视化工具,帮助用户快速归因文本生成至训练数据点,提升模型的透明度和可信度。
- 在对LLaMA2模型的实验中,使用不同数据集进行微调,展示了该工具在实际应用中的有效性和便利性。
📝 摘要(中文)
尽管大型语言模型(LLMs)在生成多领域的文本方面表现出色,但其潜在风险引发了对文本生成背后推理的关注。我们提出了LLM Attributor,这是一个Python库,提供LLM文本生成的训练数据归因的交互式可视化。该库为快速归因LLM的文本生成提供了新方法,以检查模型行为、增强其可信度,并将模型生成的文本与用户提供的文本进行比较。我们描述了工具的可视化和交互设计,并强调了其在使用LLaMA2模型时的应用场景。LLM Attributor广泛支持计算笔记本,用户可以轻松集成到工作流程中,以交互式地可视化模型的归因。该库已开源,地址为https://github.com/poloclub/LLM-Attribution。
🔬 方法详解
问题定义:本论文旨在解决大型语言模型生成文本时的可追溯性问题。现有方法缺乏有效的工具来理解模型生成文本的依据,导致用户对模型的信任度降低。
核心思路:LLM Attributor的核心思路是通过交互式可视化,快速归因模型生成的文本至具体的训练数据点,从而帮助用户理解模型的决策过程。这样的设计使得用户能够直观地看到生成文本与训练数据之间的关系。
技术框架:该工具的整体架构包括数据输入模块、归因计算模块和可视化展示模块。用户可以通过计算笔记本输入数据,工具将自动计算归因并生成可视化结果。
关键创新:LLM Attributor的主要创新在于其交互式可视化能力,允许用户实时查看和分析模型生成文本的来源。这与现有方法的静态分析方式形成鲜明对比,极大提升了用户体验。
关键设计:在技术细节上,LLM Attributor采用了灵活的参数设置,支持多种数据集的归因计算。损失函数和网络结构的设计旨在优化归因的准确性和可解释性。
🖼️ 关键图片
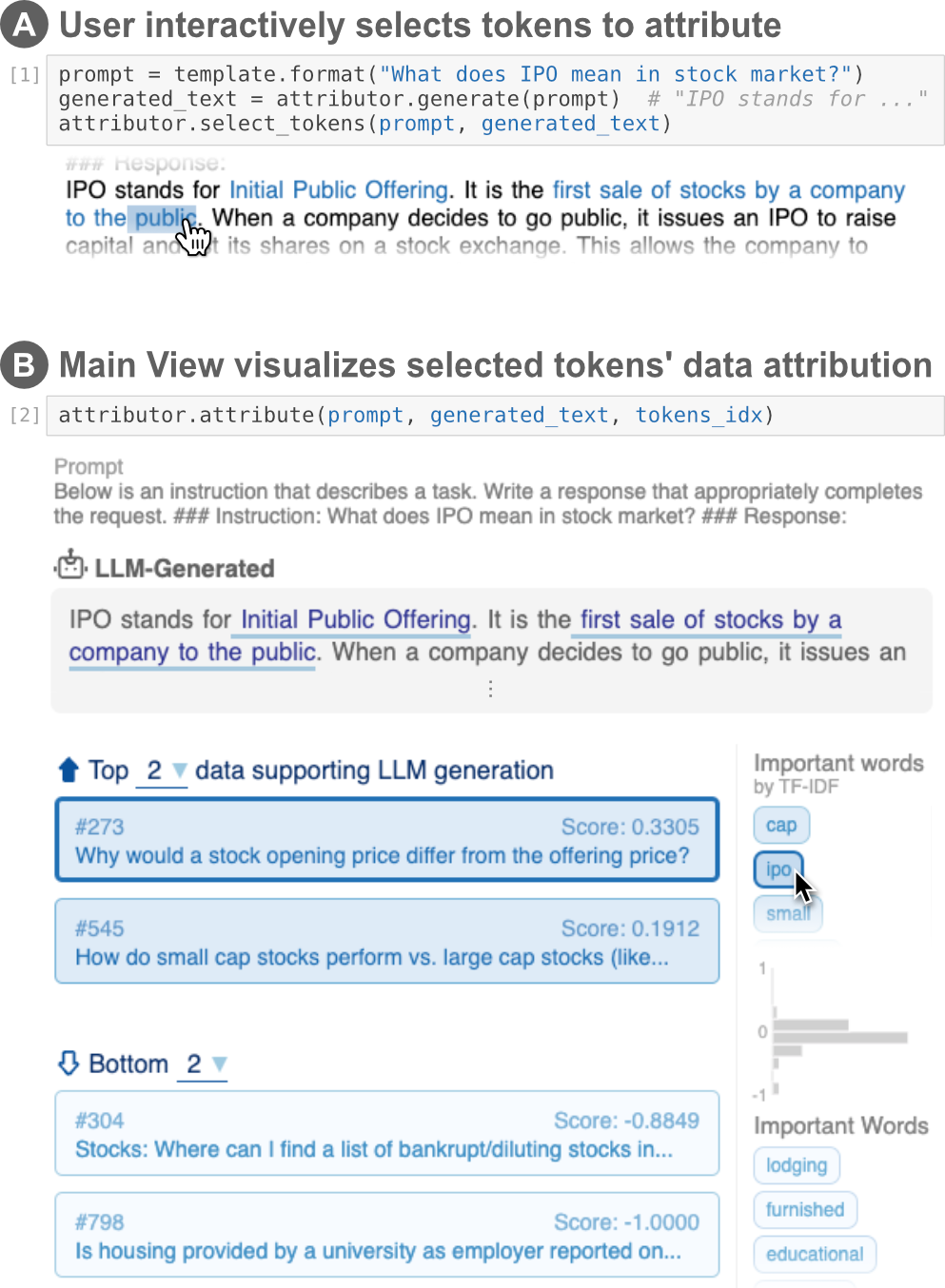

📊 实验亮点
在实验中,LLM Attributor成功地将LLaMA2模型的文本生成归因至训练数据点,用户能够直观地看到生成文本与数据的关联。与传统方法相比,该工具在可视化交互性和归因速度上有显著提升,增强了用户对模型的信任。
🎯 应用场景
LLM Attributor在多个领域具有广泛的应用潜力,尤其是在需要高可信度和透明度的文本生成任务中,如法律文书、医疗记录和金融报告等。通过提升模型的可解释性,该工具能够帮助用户更好地理解和信任模型的输出,促进其在实际应用中的推广和使用。
📄 摘要(原文)
While large language models (LLMs) have shown remarkable capability to generate convincing text across diverse domains, concerns around its potential risks have highlighted the importance of understanding the rationale behind text generation. We present LLM Attributor, a Python library that provides interactive visualizations for training data attribution of an LLM's text generation. Our library offers a new way to quickly attribute an LLM's text generation to training data points to inspect model behaviors, enhance its trustworthiness, and compare model-generated text with user-provided text. We describe the visual and interactive design of our tool and highlight usage scenarios for LLaMA2 models fine-tuned with two different datasets: online articles about recent disasters and finance-related question-answer pairs. Thanks to LLM Attributor's broad support for computational notebooks, users can easily integrate it into their workflow to interactively visualize attributions of their models. For easier access and extensibility, we open-source LLM Attributor at https://github.com/poloclub/ LLM-Attribution. The video demo is available at https://youtu.be/mIG2MDQKQxM.