Source-Aware Training Enables Knowledge Attribution in Language Models
作者: Muhammad Khalifa, David Wadden, Emma Strubell, Honglak Lee, Lu Wang, Iz Beltagy, Hao Peng
分类: cs.CL, cs.AI
发布日期: 2024-04-01 (更新: 2024-08-13)
备注: COLM '24
🔗 代码/项目: GITHUB
💡 一句话要点
提出源感知训练以解决语言模型知识归属问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 知识归属 源感知训练 透明性 可解释性 预训练 指令调优
📋 核心要点
- 现有的语言模型在生成内容时,无法有效识别和引用其知识来源,导致透明性和可解释性不足。
- 本文提出源感知训练,通过将源文档标识符与知识关联,并进行指令调优,使模型能够引用支持的预训练来源。
- 实验结果显示,该方法在合成数据上实现了对预训练数据的准确归属,同时对模型的困惑度影响不大。
📝 摘要(中文)
大型语言模型(LLMs)在预训练过程中学习了大量知识,但通常无法识别这些知识的来源。本文研究了内在源引用问题,即要求LLMs在生成响应时引用支持其内容的预训练来源。内在源引用可以增强LLM的透明性、可解释性和可验证性。为赋予LLMs这种能力,本文探索了源感知训练,包括将唯一的源文档标识符与每个文档中的知识关联的训练阶段,以及在提示时教会LLMs引用支持的预训练来源的指令调优阶段。实验结果表明,该训练方法能够在不显著影响模型困惑度的情况下,实现对预训练数据的忠实归属。
🔬 方法详解
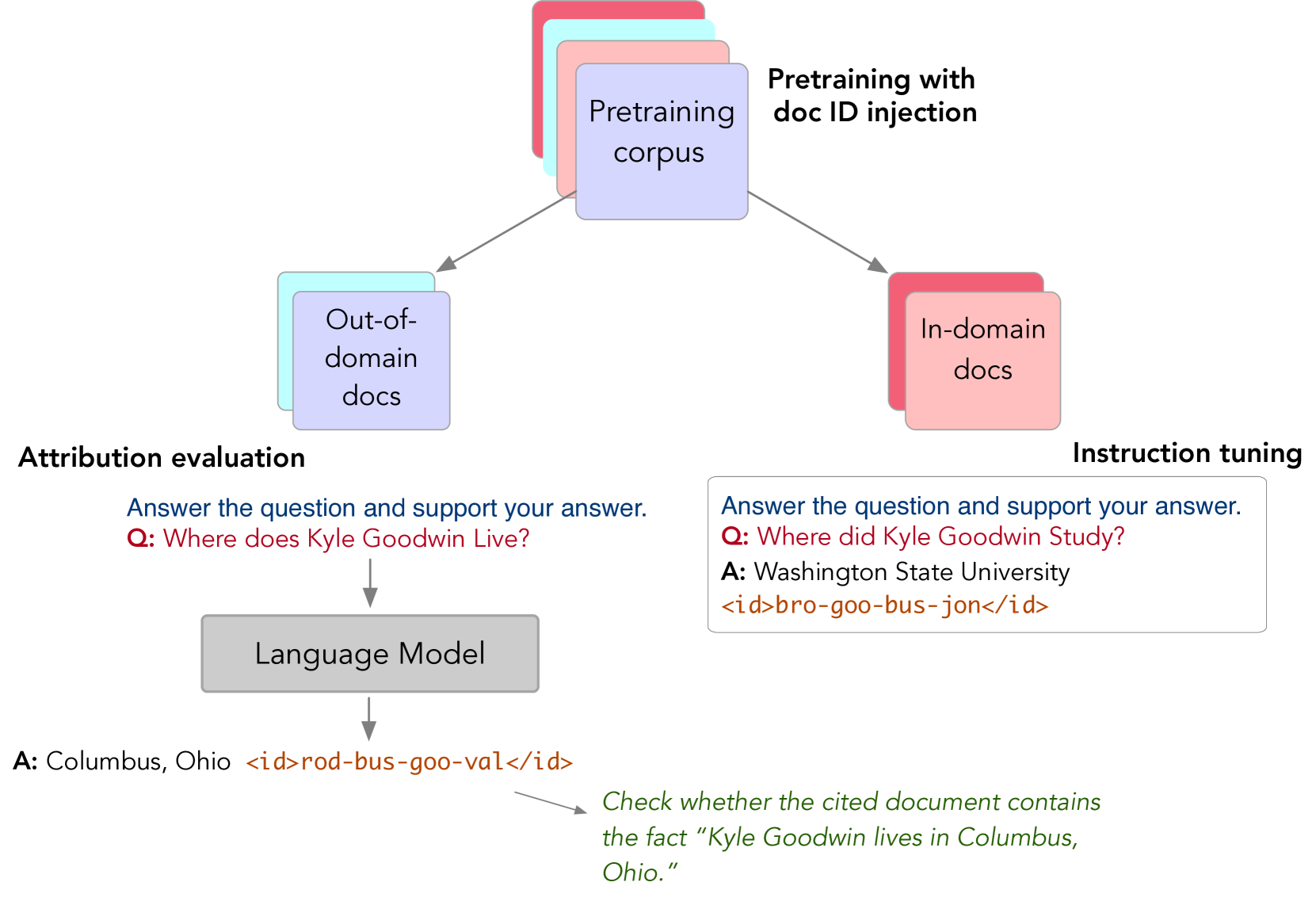
问题定义:本文旨在解决大型语言模型在生成内容时无法识别知识来源的问题。现有方法缺乏对知识来源的引用能力,导致模型的透明性和可解释性不足。
核心思路:论文提出源感知训练,核心思想是通过训练模型将唯一的源文档标识符与知识关联,并在后续的指令调优阶段教会模型如何引用这些来源。这样的设计旨在增强模型的知识归属能力。
技术框架:整体架构包括两个主要阶段:第一阶段是将源文档标识符与知识关联的训练,第二阶段是指令调优,使模型能够在提示下引用支持的来源。该方法对模型架构或实现的改动最小。
关键创新:最重要的技术创新在于源感知训练的设计,使得模型能够在生成响应时准确引用知识来源,这在现有的预训练和微调框架中尚未实现。
关键设计:在训练过程中,模型通过特定的损失函数来优化源文档标识符的关联性,同时在指令调优阶段使用了特定的提示格式,以确保模型能够有效地引用来源。
🖼️ 关键图片


📊 实验亮点
实验结果表明,源感知训练能够在合成数据上实现对预训练数据的忠实归属,且模型的困惑度与标准预训练相比没有显著增加。这一发现强调了预训练数据增强在实现知识归属中的重要性。
🎯 应用场景
该研究的潜在应用领域包括教育、法律和科研等需要高透明度和可验证性的场景。通过增强语言模型的知识归属能力,可以提高其在实际应用中的可信度和有效性,未来可能对信息检索和知识管理产生深远影响。
📄 摘要(原文)
Large language models (LLMs) learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning stage to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training borrows from existing pretraining/fine-tuning frameworks and requires minimal changes to the model architecture or implementation. Through experiments on synthetic data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's perplexity compared to standard pretraining. Our findings also highlight the importance of pretraining data augmentation in achieving attribution. Code and data available here: \url{https://github.com/mukhal/intrinsic-source-citation}