IV Co-Scientist: Multi-Agent LLM Framework for Causal Instrumental Variable Discovery
作者: Ivaxi Sheth, Zhijing Jin, Bryan Wilder, Dominik Janzing, Mario Fritz
分类: cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出IV Co-Scientist,利用多智能体LLM框架进行因果工具变量发现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推断 工具变量 大型语言模型 多智能体系统 因果发现
📋 核心要点
- 现有方法在识别工具变量时面临挑战,需要跨学科知识和创造性推理,难以自动化。
- IV Co-Scientist利用多智能体LLM框架,通过智能体之间的协作,提出、评估和改进工具变量。
- 实验表明,该方法能够从大型观测数据中发现有效的工具变量,并能识别和避免无效的工具变量。
📝 摘要(中文)
在内生变量和结果变量之间存在混淆的情况下,工具变量(IVs)被用于分离内生变量的因果效应。识别有效的工具变量需要跨学科知识、创造力和对上下文的理解,这是一项非常具有挑战性的任务。本文研究了大型语言模型(LLMs)是否可以帮助完成这项任务。我们执行了一个两阶段的评估框架。首先,我们测试LLMs是否能够从文献中恢复已建立的工具变量,评估它们复制标准推理的能力。其次,我们评估LLMs是否能够识别和避免在经验或理论上已被否定工具变量。基于这些结果,我们引入了IV Co-Scientist,一个多智能体系统,用于提出、批判和改进给定处理-结果对的工具变量。我们还引入了一个统计测试,以在缺乏真实标签的情况下对一致性进行语境化。我们的结果表明,LLMs有潜力从大型观测数据库中发现有效的工具变量。
🔬 方法详解
问题定义:论文旨在解决在存在混淆因素的情况下,如何自动发现有效的工具变量(IVs)的问题。现有方法依赖于专家知识和人工推理,成本高昂且难以规模化应用。此外,现有方法难以避免选择经验或理论上已被否定的工具变量。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的推理能力和知识储备,构建一个多智能体系统,模拟科学家团队协作的过程,从而自动发现和验证工具变量。通过多个智能体之间的相互协作、批判和改进,提高工具变量发现的效率和准确性。
技术框架:IV Co-Scientist是一个多智能体系统,包含以下几个主要模块:1) 提议智能体:负责根据给定的处理-结果对,提出可能的工具变量。2) 批判智能体:负责评估提议的工具变量的有效性,并提出改进建议。3) 改进智能体:负责根据批判智能体的建议,对提议的工具变量进行改进。4) 统计测试模块:用于在缺乏真实标签的情况下,对工具变量的一致性进行统计检验。整个流程是一个迭代的过程,直到找到满足要求的工具变量。
关键创新:论文的关键创新在于将多智能体系统与大型语言模型相结合,用于解决因果推断中的工具变量发现问题。这种方法能够充分利用LLMs的知识和推理能力,实现工具变量发现的自动化和规模化。此外,论文还提出了一个统计测试方法,用于在缺乏真实标签的情况下评估工具变量的一致性。
关键设计:论文的关键设计包括:1) 智能体的角色分配和协作机制,确保智能体之间能够有效地进行信息交流和知识共享。2) LLM的选择和微调策略,以提高LLM在工具变量发现任务中的性能。3) 统计测试方法的选择和参数设置,以确保测试结果的可靠性。具体的LLM选择和微调策略以及统计测试方法的细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
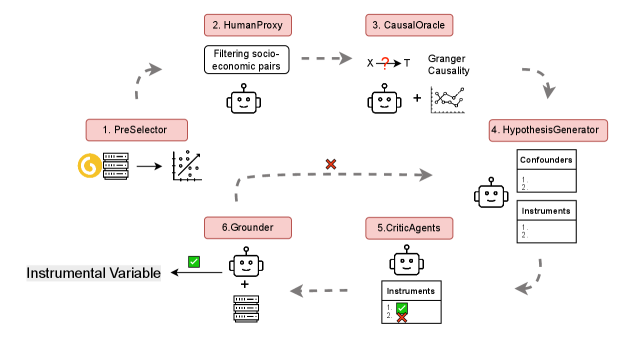

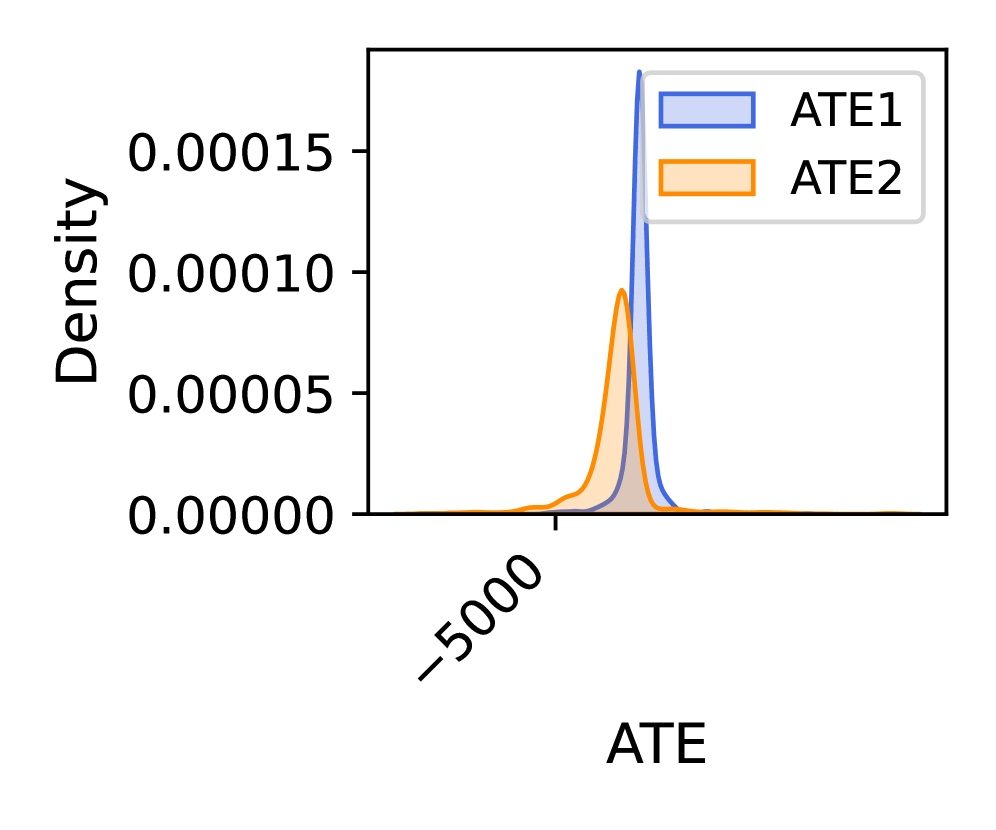
📊 实验亮点
论文通过实验验证了IV Co-Scientist的有效性。实验结果表明,该方法能够从大型观测数据中发现有效的工具变量,并能识别和避免无效的工具变量。具体的性能数据、对比基线和提升幅度在摘要中没有给出,属于未知信息。
🎯 应用场景
该研究成果可应用于医疗健康、经济学、社会科学等领域,帮助研究人员在存在混淆因素的情况下,更准确地估计因果效应。例如,在医疗领域,可以利用该方法发现影响疾病治疗效果的工具变量,从而制定更有效的治疗方案。在经济学领域,可以利用该方法分析政策对经济的影响。
📄 摘要(原文)
In the presence of confounding between an endogenous variable and the outcome, instrumental variables (IVs) are used to isolate the causal effect of the endogenous variable. Identifying valid instruments requires interdisciplinary knowledge, creativity, and contextual understanding, making it a non-trivial task. In this paper, we investigate whether large language models (LLMs) can aid in this task. We perform a two-stage evaluation framework. First, we test whether LLMs can recover well-established instruments from the literature, assessing their ability to replicate standard reasoning. Second, we evaluate whether LLMs can identify and avoid instruments that have been empirically or theoretically discredited. Building on these results, we introduce IV Co-Scientist, a multi-agent system that proposes, critiques, and refines IVs for a given treatment-outcome pair. We also introduce a statistical test to contextualize consistency in the absence of ground truth. Our results show the potential of LLMs to discover valid instrumental variables from a large observational database.