TSPO: Breaking the Double Homogenization Dilemma in Multi-turn Search Policy Optimization
作者: Shichao Ma, Zhiyuan Ma, Ming Yang, Xiaofan Li, Xing Wu, Jintao Du, Yu Cheng, Weiqiang Wang, Qiliang Liu, Zhengyang Zhou, Yang Wang
分类: cs.AI
发布日期: 2026-04-07
💡 一句话要点
TSPO通过引入Turn-level奖励机制,解决多轮搜索策略优化中的双重同质化问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮搜索 策略优化 强化学习 奖励塑形 大型语言模型 工具集成 推理 过程奖励
📋 核心要点
- 现有方法在多轮搜索策略优化中面临双重同质化问题,忽略了推理过程和组内差异。
- TSPO通过引入首次出现潜在奖励(FOLR)机制,在turn级别分配奖励,保留过程信号。
- 实验结果表明,TSPO在Qwen2.5-3B和7B模型上分别实现了平均24%和13.6%的性能提升。
📝 摘要(中文)
多轮工具集成推理使得大型语言模型(LLMs)能够通过迭代信息检索解决复杂任务。然而,当前用于搜索增强推理的强化学习(RL)框架主要依赖于稀疏的结果级奖励,导致“双重同质化困境”。这表现为:(1)过程同质化,即忽略了生成过程中涉及的思考、推理和工具使用。(2)组内同质化,粗粒度的结果奖励通常导致在使用诸如组相对策略优化(GRPO)等方法进行采样时,组内优势估计效率低下。为了解决这个问题,我们提出了Turn-level Stage-aware Policy Optimization(TSPO)。TSPO引入了首次出现潜在奖励(FOLR)机制,将部分奖励分配给首次出现真实答案的步骤,从而保留过程级信号并增加组内奖励方差,而无需外部奖励模型或任何标注。大量实验表明,TSPO显著优于最先进的基线,在Qwen2.5-3B和7B模型上分别实现了平均24%和13.6%的性能提升。
🔬 方法详解
问题定义:论文旨在解决多轮搜索策略优化中存在的“双重同质化困境”。现有方法依赖于稀疏的结果级奖励,忽略了推理过程中的思考、推理和工具使用(过程同质化),并且粗粒度的奖励导致组内优势估计效率低下(组内同质化)。这种稀疏奖励信号使得模型难以学习有效的搜索策略。
核心思路:论文的核心思路是在turn级别引入更细粒度的奖励信号,从而保留过程级信息并增加组内奖励的方差。具体而言,通过识别首次出现正确答案的turn,并给予该turn一定的奖励,从而鼓励模型探索更有效的推理路径。这种方法不需要额外的奖励模型或人工标注,降低了成本。
技术框架:TSPO(Turn-level Stage-aware Policy Optimization)的整体框架基于现有的强化学习方法,如GRPO。主要的改进在于奖励机制上。在每个episode中,模型执行多轮搜索和推理。在每一轮(turn),模型生成一个动作(例如,调用工具或给出最终答案)。TSPO的关键在于引入FOLR(First-Occurrence Latent Reward)机制,该机制检测在哪个turn首次出现了正确的答案,并将部分奖励分配给该turn。最终的奖励是结果奖励和FOLR的加权和。
关键创新:TSPO最重要的创新点在于FOLR机制,它是一种无需额外标注或奖励模型即可实现turn级别奖励分配的方法。与传统的只在episode结束时给予奖励的方法不同,FOLR能够提供更密集的奖励信号,从而加速学习过程并提高策略的有效性。这种方法能够有效缓解双重同质化问题。
关键设计:FOLR的关键设计在于如何确定“首次出现正确答案”的turn。论文中具体如何实现这一检测机制的细节未知。此外,结果奖励和FOLR的权重也是一个重要的超参数,需要根据具体任务进行调整。损失函数是标准的策略梯度损失函数,但使用了更细粒度的奖励信号。
🖼️ 关键图片
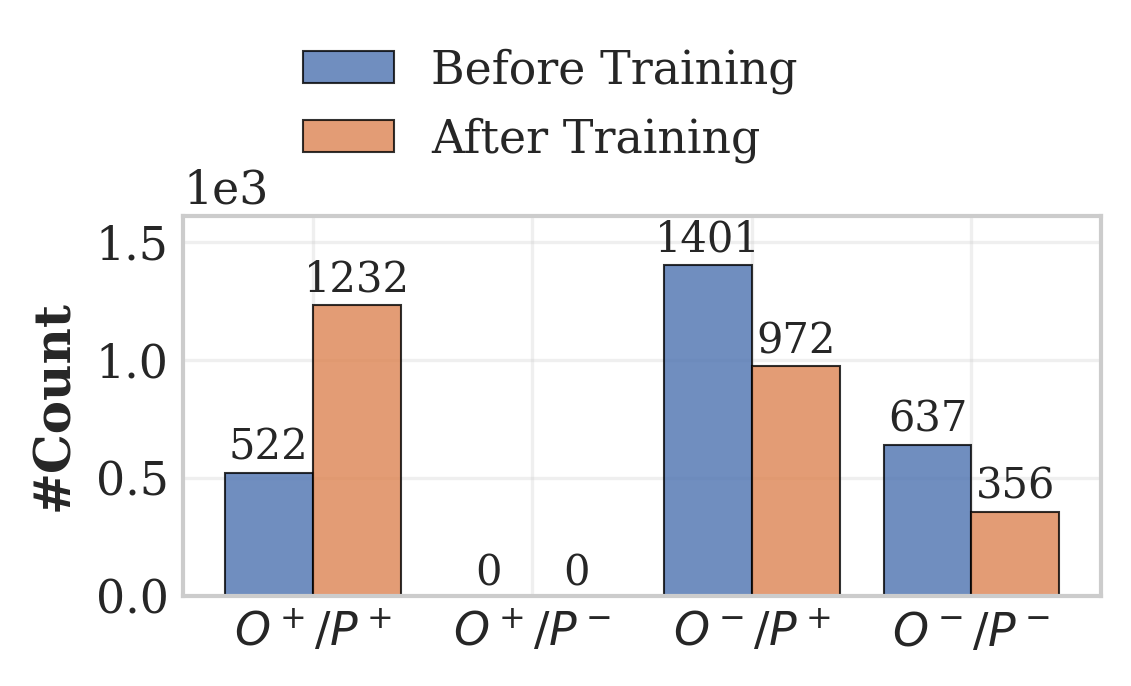
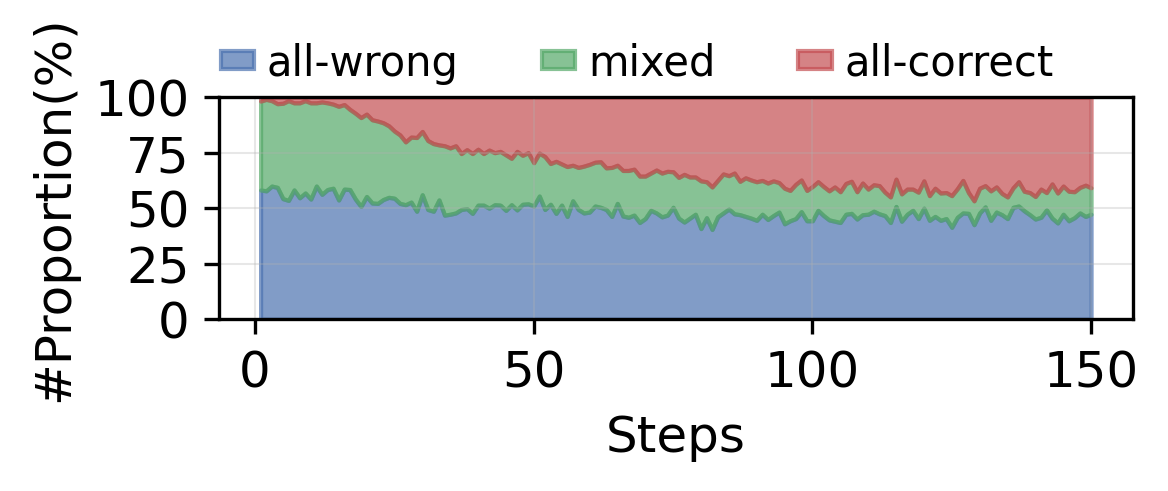

📊 实验亮点
实验结果表明,TSPO在Qwen2.5-3B和7B模型上分别实现了平均24%和13.6%的性能提升,显著优于现有的基线方法。这表明TSPO能够有效缓解双重同质化问题,并提高LLM在多轮搜索策略优化中的性能。具体的评估指标和数据集未知。
🎯 应用场景
TSPO可应用于各种需要多轮搜索和推理的场景,例如智能问答、任务型对话系统、代码生成等。通过提高LLM在复杂任务中的推理能力,可以提升用户体验,并降低人工干预的需求。该研究对于提升LLM的实用性和可靠性具有重要意义。
📄 摘要(原文)
Multi-turn tool-integrated reasoning enables Large Language Models (LLMs) to solve complex tasks through iterative information retrieval. However, current reinforcement learning (RL) frameworks for search-augmented reasoning predominantly rely on sparse outcome-level rewards, leading to a "Double Homogenization Dilemma." This manifests as (1) Process homogenization, where the thinking, reasoning, and tooling involved in generation are ignored. (2) Intra-group homogenization, coarse-grained outcome rewards often lead to inefficiencies in intra-group advantage estimation with methods like Group Relative Policy Optimization (GRPO) during sampling. To address this, we propose Turn-level Stage-aware Policy Optimization (TSPO). TSPO introduces the First-Occurrence Latent Reward (FOLR) mechanism, allocating partial rewards to the step where the ground-truth answer first appears, thereby preserving process-level signals and increasing reward variance within groups without requiring external reward models or any annotations. Extensive experiments demonstrate that TSPO significantly outperforms state-of-the-art baselines, achieving average performance gains of 24% and 13.6% on Qwen2.5-3B and 7B models, respectively. Code is available atthis https URL.