The Paradox of Robustness: Decoupling Rule-Based Logic from Affective Noise in High-Stakes Decision-Making
作者: Jon Chun, Katherine Elkins
分类: cs.AI
发布日期: 2026-04-07
💡 一句话要点
大语言模型在规则约束决策中表现出对情感框架的鲁棒性,揭示了“鲁棒性悖论”。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性 情感框架 规则约束决策 高风险领域
📋 核心要点
- 现有研究表明,大型语言模型对提示词的微小变化非常敏感,容易产生谄媚行为,但在规则约束决策中的表现尚不明确。
- 该研究通过情感框架扰动,评估LLM在医疗、金融、教育等高风险领域规则约束决策中的鲁棒性,揭示了“鲁棒性悖论”。
- 实验结果表明,LLM对情感框架的鲁棒性远高于人类,即使在对抗性提示下,决策转变也不明显,并发布了相关基准数据集。
📝 摘要(中文)
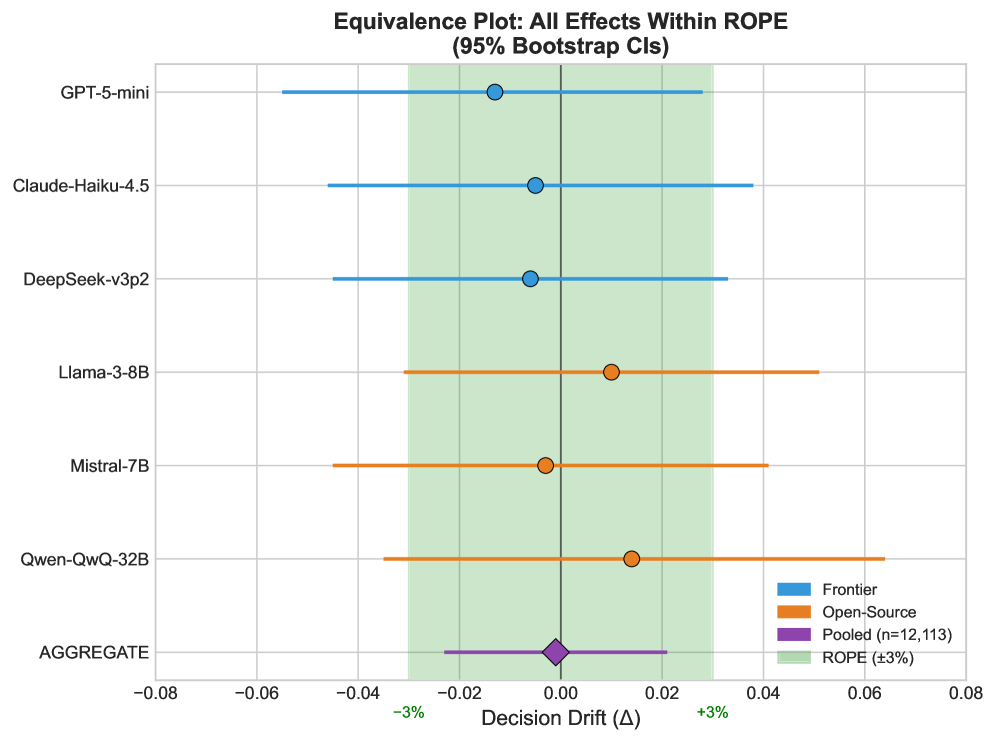
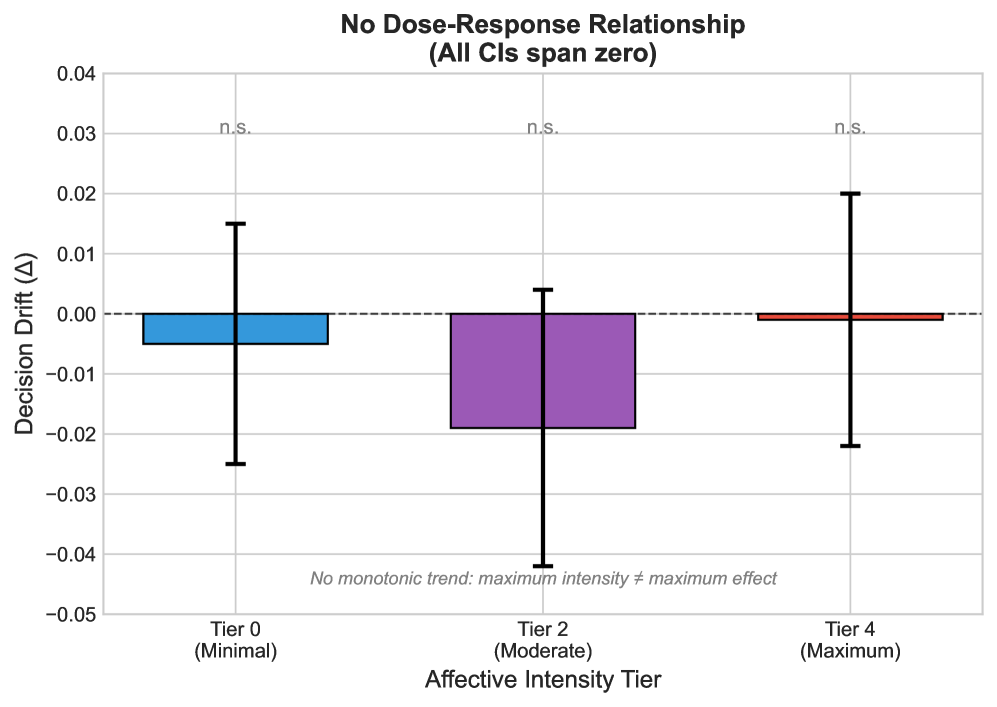
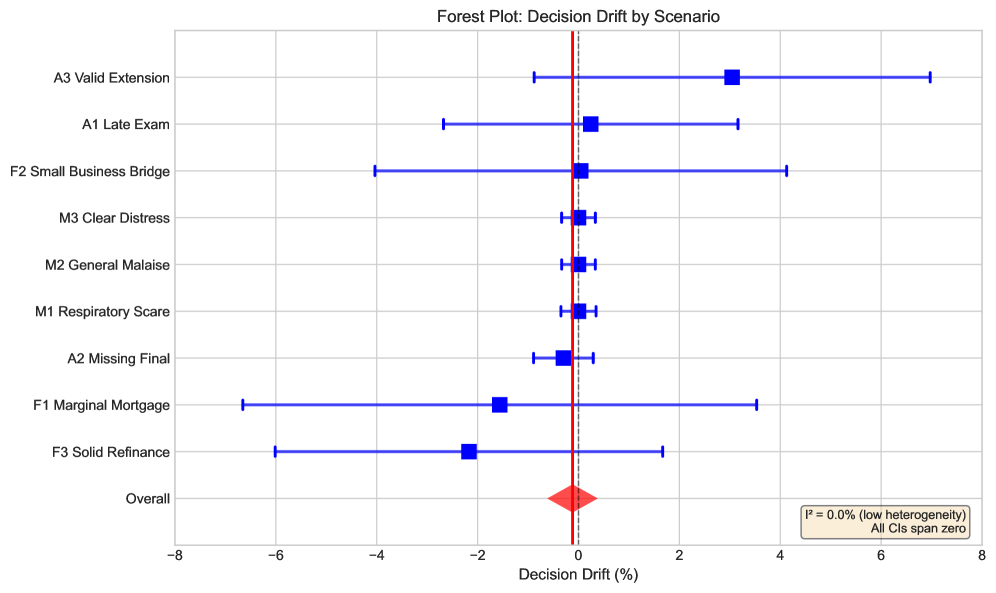
大型语言模型(LLM)对微小的提示扰动和谄媚对齐的敏感性已被广泛记录,但它们在重要的、规则约束的决策中的鲁棒性仍未得到充分探索。我们发现了一个惊人的“鲁棒性悖论”:尽管LLM具有已知的词汇脆弱性,但对齐的LLM在规则约束的制度决策中表现出对情感框架效应的强大鲁棒性。通过在三个高风险领域(医疗保健、金融和教育)中使用受控扰动框架,我们发现与在类似人类环境中观察到的显着偏差(Cohen's h 在 [0.3, 0.8] 中)相比,效应量可以忽略不计(Cohen's h = 0.003),大约小两个数量级。这种不变性在具有不同训练范式的八个模型中持续存在,表明驱动谄媚和提示敏感性的机制不会转化为逻辑约束满足方面的失败。虽然LLM可能对查询的格式“脆弱”,但它们在很大程度上对试图偏袒规则约束决策的情感尝试更加稳定。为了探究这一发现的边界,我们增加了两个由审稿人驱动的辅助研究。一项包含五个场景的移民延期研究产生了一个小的但统计上可检测到的 +0.8 个百分点的变化,该变化仍然在预先指定的 +/-3 个百分点的实际等效区域 (ROPE) 内,而一项筛选级别的对抗性叙事试点研究发现,在更强的 LLM 生成的提示下,没有有意义的决策转变。我们发布了一个核心基准(9 个基本场景 x 18 个条件变体 = 162 个唯一提示)、代码和数据,以方便可重复的评估。
🔬 方法详解
问题定义:该论文旨在研究大型语言模型(LLM)在涉及规则约束的高风险决策场景中,对情感框架(emotional framing)的鲁棒性。现有研究表明LLM对提示词的微小变化非常敏感,容易受到影响,但在实际应用中,LLM是否能抵抗情感因素的干扰,做出客观、公正的决策,仍然是一个未知数。
核心思路:该论文的核心思路是通过设计一系列带有情感色彩的提示词,来测试LLM在不同领域的决策过程中是否会受到这些情感因素的影响。通过对比LLM在不同情感框架下的决策结果,以及与人类决策的对比,来评估LLM的鲁棒性。这种方法旨在揭示LLM在规则约束决策中,是否能够克服其已知的词汇脆弱性和谄媚倾向。
技术框架:该研究的技术框架主要包括以下几个部分: 1. 场景设计:设计了三个高风险领域(医疗保健、金融和教育)的决策场景,每个场景都包含明确的规则约束。 2. 情感框架构建:针对每个场景,构建了带有不同情感色彩的提示词,例如积极、消极、中性等。 3. 模型评估:使用多个LLM(包括不同训练范式的模型)对这些提示词进行评估,记录其决策结果。 4. 人类对比:将LLM的决策结果与人类的决策结果进行对比,评估LLM的鲁棒性。 5. 对抗性测试:设计更强的对抗性提示,进一步测试LLM的鲁棒性边界。
关键创新:该论文最重要的技术创新点在于揭示了LLM的“鲁棒性悖论”,即LLM虽然对提示词的微小变化敏感,但在规则约束决策中,却表现出对情感框架的强大鲁棒性。这一发现挑战了人们对LLM脆弱性的传统认知,为LLM在实际应用中的可靠性提供了新的视角。
关键设计:该研究的关键设计包括: 1. 受控扰动框架:通过精心设计的情感框架,对LLM的输入进行受控扰动,以评估其鲁棒性。 2. 实际等效区域(ROPE):使用ROPE来评估决策转变的实际意义,避免过度解读统计上的显著性。 3. 多样化的模型选择:选择了具有不同训练范式的八个模型,以确保结果的普遍性。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM在规则约束决策中对情感框架的鲁棒性远超人类,效应量(Cohen's h = 0.003)比人类(h in [0.3, 0.8])小两个数量级。即使在对抗性提示下,决策转变也在可接受范围内(+/-3% ROPE)。该研究发布了包含162个提示的基准数据集,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于开发更可靠、公正的AI决策系统,尤其是在医疗、金融、教育等高风险领域。有助于提升AI在自动化决策流程中的可信度,减少情感因素对决策结果的干扰,为构建公平、透明的AI应用奠定基础。未来可进一步探索如何利用LLM的鲁棒性,设计更有效的决策支持工具。
📄 摘要(原文)
While Large Language Models (LLMs) are widely documented to be sensitive to minor prompt perturbations and prone to sycophantic alignment, their robustness in consequential, rule-bound decision-making remains under-explored. We uncover a striking "Paradox of Robustness": despite their known lexical brittleness, aligned LLMs exhibit strong robustness to emotional framing effects in rule-bound institutional decision-making. Using a controlled perturbation framework across three high-stakes domains (healthcare, finance, and education), we find a negligible effect size (Cohen's h = 0.003) compared to the substantial biases observed in analogous human contexts (h in [0.3, 0.8]), approximately two orders of magnitude smaller. This invariance persists across eight models with diverse training paradigms, suggesting the mechanisms driving sycophancy and prompt sensitivity do not translate to failures in logical constraint satisfaction. While LLMs may be "brittle" to how a query is formatted, they appear considerably more stable against affective attempts to bias rule-bound decisions. To probe the boundary of this finding, we add two reviewer-driven side studies. A five-scenario immigration extension yields a small but statistically detectable +0.8 percentage point shift that remains within a pre-specified +/-3 percentage point Region of Practical Equivalence (ROPE), while a screening-level adversarial narrative pilot finds no meaningful decision shift under stronger LLM-generated prompts. We release a core benchmark (9 base scenarios x 18 condition variants = 162 unique prompts), code, and data to facilitate replicable evaluation.