Autonomous Agents for Scientific Discovery: Orchestrating Scientists, Language, Code, and Physics
作者: Lianhao Zhou, Hongyi Ling, Cong Fu, Yepeng Huang, Michael Sun, Wendi Yu, Xiaoxuan Wang, Xiner Li, Xingyu Su, Junkai Zhang, Xiusi Chen, Chenxing Liang, Xiaofeng Qian, Heng Ji, Wei Wang, Marinka Zitnik, Shuiwang Ji
分类: cs.AI
发布日期: 2026-04-07
💡 一句话要点
基于LLM的自主智能体加速科学发现,实现科学家、语言、代码和物理的协同。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主智能体 科学发现 大型语言模型 实验设计 自动化科研
📋 核心要点
- 现有科学发现流程面临自动化程度低、跨学科协作困难等挑战,阻碍了科研效率的提升。
- 论文提出利用大型语言模型(LLMs)构建自主智能体,以协调科学家、语言、代码和物理学之间的交互,从而加速科学发现。
- 该研究分析了当前基于LLM的科学智能体的方法,强调了其创新点和局限性,并指出了未来研究方向。
📝 摘要(中文)
计算长期以来一直是科学发现的基石。随着大型语言模型(LLMs)的兴起,一种新的范式正在出现,即引入自主系统(称为智能体),以不同程度的自主性加速发现。这些语言智能体提供了一个灵活且通用的框架,可以协调与人类科学家、自然语言、计算机语言和代码以及物理学的交互。本文介绍了我们对基于LLM的科学智能体的看法和愿景,以及它们在改变科学发现生命周期(从假设发现、实验设计和执行到结果分析和改进)方面日益增长的作用。我们批判性地考察了当前的方法,强调了关键创新、实际成就和突出的局限性。此外,我们还确定了开放的研究挑战,并概述了构建更强大、更通用和更具适应性的科学智能体的有希望的方向。我们的分析突出了自主智能体在加速不同领域科学发现方面的变革潜力。
🔬 方法详解
问题定义:当前科学发现过程高度依赖人工,自动化程度低,且不同学科之间的知识壁垒使得跨学科协作困难。此外,实验设计、数据分析等环节耗时耗力,严重制约了科研效率的提升。现有方法难以有效整合自然语言、代码和物理知识,无法实现科学发现流程的自动化和智能化。
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大语言理解和生成能力,构建自主智能体,作为科学家助手,自动化执行科学发现的各个环节。通过将LLM与各种工具(如代码解释器、物理模拟器等)集成,智能体可以理解科学家的指令,生成实验方案,执行实验,分析结果,并根据结果迭代优化。
技术框架:整体框架包含以下几个主要模块:1) 假设生成模块:利用LLM从科学文献或知识库中提取信息,生成潜在的科学假设。2) 实验设计模块:根据假设,LLM生成实验方案,包括实验步骤、参数设置等。3) 实验执行模块:智能体通过调用代码解释器或物理模拟器等工具,自动执行实验。4) 结果分析模块:LLM分析实验结果,提取关键信息,并评估假设的有效性。5) 迭代优化模块:根据结果分析,LLM调整实验方案或生成新的假设,进行迭代优化。
关键创新:最重要的技术创新点在于将大型语言模型应用于科学发现流程的自动化。与传统方法相比,该方法能够更好地理解和处理自然语言描述的科学问题,并能够利用代码和物理知识进行推理和预测。此外,自主智能体能够自主地进行实验设计、执行和结果分析,大大提高了科研效率。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,可以推断,关键设计包括:1) 如何有效地将LLM与各种工具集成,使其能够协同工作。2) 如何设计合适的提示(prompt)来引导LLM生成高质量的实验方案和结果分析。3) 如何设计奖励函数来鼓励智能体探索更有价值的科学假设。
🖼️ 关键图片
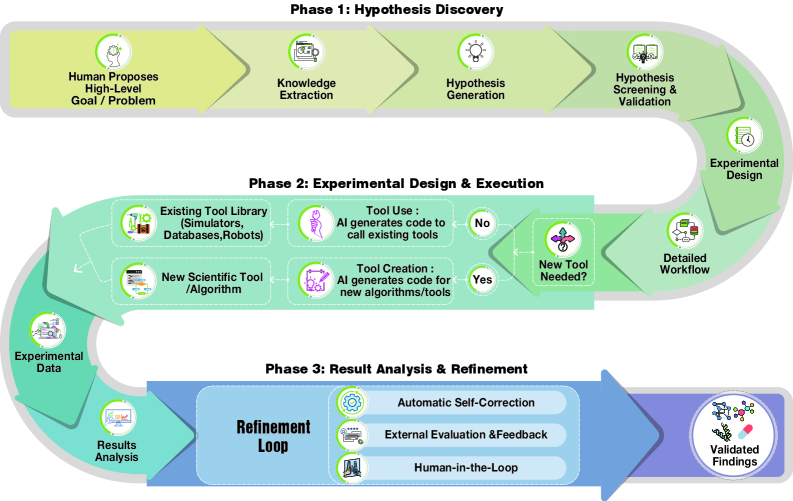
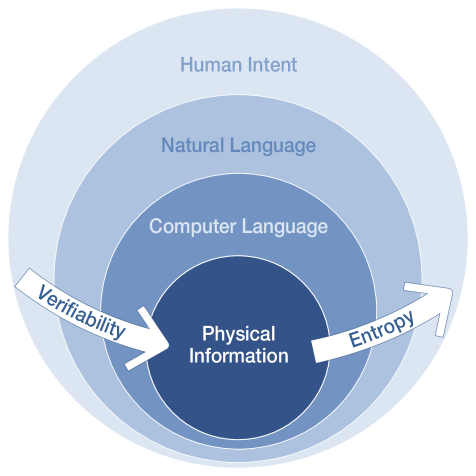
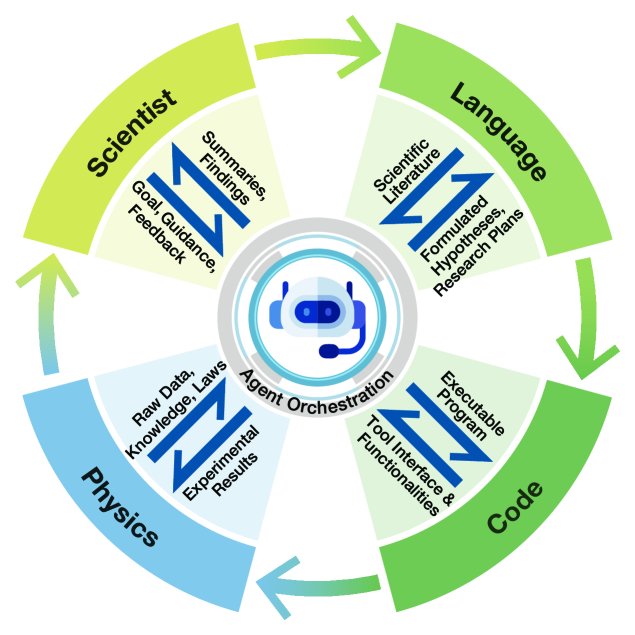
📊 实验亮点
论文主要侧重于概念和框架的提出,以及对现有方法的分析和展望,并没有提供具体的实验结果。因此,无法总结具体的性能数据、对比基线和提升幅度。未来的研究需要通过实验验证该方法的有效性,并与其他方法进行比较。
🎯 应用场景
该研究成果可广泛应用于化学、生物学、材料科学等多个领域,加速新材料发现、药物研发等过程。通过自动化实验设计和数据分析,可以大幅缩短科研周期,降低科研成本,并有望发现传统方法难以发现的科学规律。未来,该技术有望成为科学家进行科学研究的重要辅助工具。
📄 摘要(原文)
Computing has long served as a cornerstone of scientific discovery. Recently, a paradigm shift has emerged with the rise of large language models (LLMs), introducing autonomous systems, referred to as agents, that accelerate discovery across varying levels of autonomy. These language agents provide a flexible and versatile framework that orchestrates interactions with human scientists, natural language, computer language and code, and physics. This paper presents our view and vision of LLM-based scientific agents and their growing role in transforming the scientific discovery lifecycle, from hypothesis discovery, experimental design and execution, to result analysis and refinement. We critically examine current methodologies, emphasizing key innovations, practical achievements, and outstanding limitations. Additionally, we identify open research challenges and outline promising directions for building more robust, generalizable, and adaptive scientific agents. Our analysis highlights the transformative potential of autonomous agents to accelerate scientific discovery across diverse domains.