ShadowNPU: System and Algorithm Co-design for NPU-Centric On-Device LLM Inference
作者: Wangsong Yin, Daliang Xu, Mengwei Xu, Gang Huang, Xuanzhe Liu
分类: cs.PF, cs.AI, cs.LG
发布日期: 2026-04-07
💡 一句话要点
ShadowNPU:面向NPU的片上LLM推理系统与算法协同设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 片上推理 大型语言模型 神经处理单元 系统算法协同设计 稀疏注意力 量化敏感性 边缘计算
📋 核心要点
- 现有框架在设备端运行LLM时,注意力机制因量化敏感性易回退至CPU/GPU,影响性能和增加调度复杂性。
- ShadowNPU提出shadowAttn,一种系统算法协同设计的稀疏注意力模块,最小化对CPU/GPU的依赖,提升NPU利用率。
- ShadowNPU通过NPU计算图分桶、head-wise流水线和细粒度稀疏度控制等技术,在资源受限情况下实现高性能。
📝 摘要(中文)
本文提出了一种名为shadowAttn的系统-算法协同设计的稀疏注意力模块,旨在最小化对CPU/GPU的依赖,从而实现在设备上高效运行大型语言模型(LLMs)。现有框架中,由于量化敏感性,注意力算子通常会从专用NPU回退到通用CPU/GPU,导致用户体验下降和系统调度复杂性增加。shadowAttn通过仅在少量token上进行稀疏计算来解决这个问题。其核心思想是利用基于NPU的pilot compute来隐藏估计重要token的开销。此外,shadowAttn还提出了诸如NPU计算图分桶、head-wise NPU-CPU/GPU流水线和per-head细粒度稀疏度比例等技术,以实现高精度和高效率。shadowAttn在CPU/GPU资源高度受限的情况下也能提供最佳性能,并且只需更少的CPU/GPU资源即可达到与SoTA框架相当的性能。
🔬 方法详解
问题定义:现有在设备上运行大型语言模型(LLMs)的框架,在执行注意力机制时,由于量化操作的敏感性,经常需要将计算任务从专用的神经处理单元(NPU)回退到通用的CPU或GPU上。这种回退会导致推理速度下降,用户体验变差,并且增加了系统调度的复杂性。因此,论文要解决的问题是如何在设备端,特别是在NPU资源有限的情况下,高效地运行LLM的注意力机制,避免对CPU/GPU的过度依赖。
核心思路:论文的核心思路是提出一种稀疏注意力机制,即shadowAttn,只在少量重要的token上进行注意力计算,从而降低计算量,使得NPU能够高效地处理。为了确定这些重要的token,论文采用了一种基于NPU的pilot compute,在不增加额外开销的前提下,估计token的重要性。通过这种方式,shadowAttn能够在保证精度的同时,显著减少对CPU/GPU的依赖。
技术框架:shadowAttn的技术框架主要包括以下几个模块:1) NPU-based pilot compute:用于快速估计token的重要性;2) 稀疏注意力计算:只在选定的重要token上进行注意力计算;3) NPU计算图分桶:将计算图划分为多个桶,以便更好地利用NPU资源;4) head-wise NPU-CPU/GPU流水线:针对不同的注意力头,采用不同的计算设备,实现并行计算;5) per-head细粒度稀疏度比例:为每个注意力头设置不同的稀疏度,以平衡精度和效率。
关键创新:论文的关键创新在于系统和算法的协同设计。一方面,通过稀疏注意力机制降低了计算复杂度,使得NPU能够高效地处理注意力计算;另一方面,通过NPU计算图分桶、head-wise流水线和细粒度稀疏度控制等技术,充分利用了NPU的计算资源,避免了对CPU/GPU的过度依赖。这种系统和算法的协同设计是现有方法所不具备的。
关键设计:在关键设计方面,论文提出了以下几个技术细节:1) NPU计算图分桶:通过将计算图划分为多个桶,可以更好地利用NPU的并行计算能力,提高计算效率。具体的分桶策略未知。2) head-wise NPU-CPU/GPU流水线:针对不同的注意力头,可以根据其计算复杂度选择不同的计算设备。例如,对于计算复杂度较高的注意力头,可以使用GPU进行计算,而对于计算复杂度较低的注意力头,可以使用NPU进行计算。3) per-head细粒度稀疏度比例:为每个注意力头设置不同的稀疏度,可以根据其重要性平衡精度和效率。重要的注意力头可以设置较低的稀疏度,以保证精度,而不重要的注意力头可以设置较高的稀疏度,以提高效率。
🖼️ 关键图片
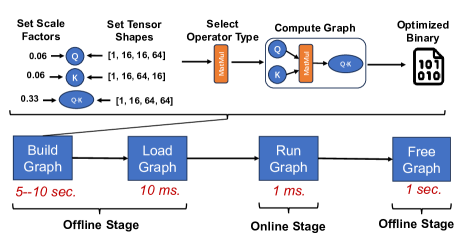
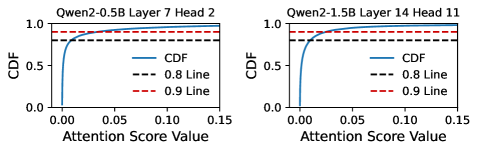

📊 实验亮点
论文重点在于在资源受限的设备上实现高性能的LLM推理。通过shadowAttn,在CPU/GPU资源有限的情况下,实现了与SoTA框架相当的性能,并且显著减少了对CPU/GPU的依赖。具体的性能数据和提升幅度在摘要中未明确给出,需要在论文正文中查找。
🎯 应用场景
ShadowNPU技术可广泛应用于各种需要设备端LLM推理的场景,例如智能手机、智能家居设备、可穿戴设备等。它能够保护用户隐私,降低网络延迟,并提高设备在离线环境下的可用性。这项研究对于推动边缘计算和人工智能的普及具有重要意义,未来可能促进更多创新应用的发展。
📄 摘要(原文)
On-device running Large Language Models (LLMs) is nowadays a critical enabler towards preserving user privacy. We observe that the attention operator falls back from the special-purpose NPU to the general-purpose CPU/GPU because of quantization sensitivity in state-of-the-art frameworks. This fallback results in a degraded user experience and increased complexity in system scheduling. To this end, this paper presents shadowAttn, a system-algorithm codesigned sparse attention module with minimal reliance on CPU/GPU by only sparsely calculating the attention on a tiny portion of tokens. The key idea is to hide the overhead of estimating the important tokens with a NPU-based pilot compute. Further, shadowAttn proposes insightful techniques such as NPU compute graph bucketing, head-wise NPU-CPU/GPU pipeline and per-head fine-grained sparsity ratio to achieve high accuracy and efficiency. shadowAttn delivers the best performance with highly limited CPU/GPU resource; it requires much less CPU/GPU resource to deliver on-par performance of SoTA frameworks.