Seemingly Simple Planning Problems are Computationally Challenging: The Countdown Game
作者: Michael Katz, Harsha Kokel, Sarath Sreedharan
分类: cs.AI
发布日期: 2026-04-07
💡 一句话要点
提出基于倒计时游戏的规划基准,挑战现有LLM辅助规划方法的长程规划能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 规划基准 倒计时游戏 LLM辅助规划 长程规划 NP完全 人工智能 智能体 计算复杂性
📋 核心要点
- 现有规划基准要么任务定义松散难以验证,要么针对传统规划器的弱点设计,无法有效评估通用智能体的规划能力。
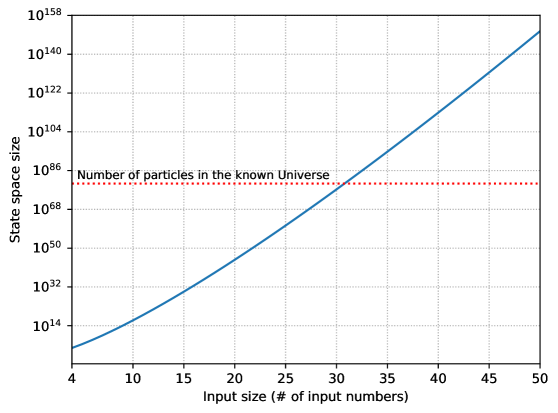
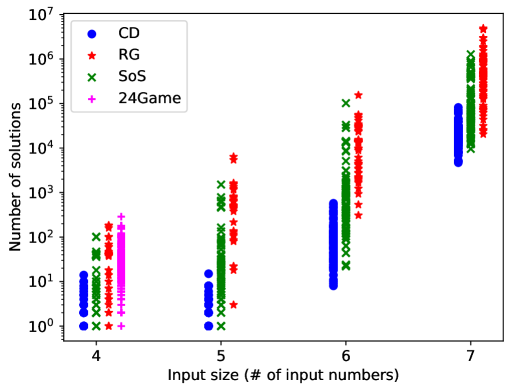
- 论文提出基于倒计时游戏的规划基准,该游戏具有明确的状态转移模型、NP完全的计算复杂度和丰富的实例空间。
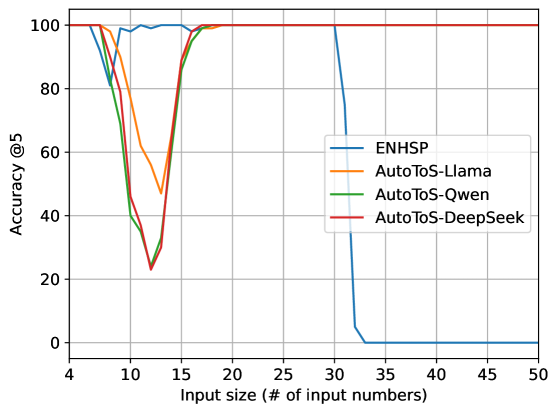
- 实验表明,该基准对现有的LLM辅助规划方法构成严峻挑战,突显了现有方法在复杂规划任务上的不足。
📝 摘要(中文)
当前基础模型和智能体在形成长期规划方面存在局限性。现有的规划基准不足以衡量其规划能力。本文提出一种基于倒计时游戏的规划基准,玩家需要通过算术运算,利用给定的数字列表得到目标数字。每个实例都诱导出一个完全指定的转移模型,从而能够评估具有可验证结果的规划。该问题具有直观的自然语言描述,计算上具有挑战性(NP完全),且实例空间足够丰富,无需担心记忆问题。理论分析证明了其计算复杂性,并展示了实例生成程序优于公共基准的优势。在生成的实例上评估了各种现有的LLM辅助规划方法,结果表明,与24点游戏等其他领域不同,该动态基准对现有的基于LLM的方法仍然极具挑战性。
🔬 方法详解
问题定义:现有规划基准存在不足,无法有效评估通用智能体的长程规划能力。具体来说,现有基准要么是像旅行规划这样定义模糊的任务,要么是来自国际规划竞赛的传统领域,这些领域专门设计来测试现有自动规划器的弱点。因此,需要一个更具挑战性、可验证且不易被记忆的规划基准。
核心思路:论文的核心思路是利用倒计时游戏作为规划基准。倒计时游戏要求玩家通过算术运算,从给定的数字列表中得到目标数字。这种游戏具有明确的状态转移规则,并且可以通过调整数字列表和目标数字来生成各种难度级别的实例。此外,倒计时游戏可以用自然语言直观地描述,方便人类理解和验证。
技术框架:该研究提出了一种生成倒计时游戏实例的程序。每个实例都定义了一个规划问题,其中状态是当前可用的数字列表,动作是算术运算(加、减、乘、除)。目标是使用这些运算将列表中的数字组合成目标数字。该框架允许对生成的实例进行难度控制,并确保实例的计算复杂性(NP完全)。然后,使用这些生成的实例来评估各种LLM辅助的规划方法。
关键创新:该研究的关键创新在于将倒计时游戏形式化为一个规划基准,并证明了其计算复杂性。与现有的规划基准相比,倒计时游戏具有更强的可验证性、更高的计算难度和更丰富的实例空间。此外,该研究还提供了一种生成具有不同难度级别的倒计时游戏实例的程序,从而可以更全面地评估规划算法的性能。
关键设计:实例生成过程的关键设计包括:选择合适的数字范围和目标数字范围,确保生成的实例具有解,并控制实例的解的长度和复杂性。此外,还设计了评估指标来衡量LLM辅助规划方法在倒计时游戏上的性能,例如成功率、规划长度和计算时间。没有涉及具体的网络结构或损失函数,因为重点在于基准的构建和对现有LLM方法的评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的LLM辅助规划方法在倒计时游戏基准上表现不佳,成功率远低于人类水平。这表明,即使是看似简单的规划问题,对于当前的LLM模型来说仍然具有挑战性。与24点游戏等其他领域相比,该基准对LLM提出了更高的要求,突显了现有方法在复杂规划任务上的不足。
🎯 应用场景
该研究提出的倒计时游戏规划基准可用于评估和改进通用人工智能体的规划能力,尤其是在需要长期推理和复杂操作的场景中。例如,可以应用于机器人任务规划、自动驾驶决策、以及游戏AI等领域,促进这些领域中智能体规划能力的提升。
📄 摘要(原文)
There is a broad consensus that the inability to form long-term plans is one of the key limitations of current foundational models and agents. However, the existing planning benchmarks remain woefully inadequate to truly measure their planning capabilities. Most existing benchmarks either focus on loosely defined tasks like travel planning or end up leveraging existing domains and problems from international planning competitions. While the former tasks are hard to formalize and verify, the latter were specifically designed to test and challenge the weaknesses of existing automated planners. To address these shortcomings, we propose a procedure for creating a planning benchmark centered around the game called Countdown, where a player is expected to form a target number from a list of input numbers through arithmetic operations. From a world-model perspective, each instance induces a fully specified transition model (dynamics) over states and actions, enabling evaluation of planning with verifiable outcomes. We discuss how this problem meets many of the desiderata associated with an ideal benchmark for planning capabilities evaluation. Specifically, the domain allows for an intuitive, natural language description for each problem instance, it is computationally challenging (NP-complete), and the instance space is rich enough that we do not have to worry about memorization. We perform an extensive theoretical analysis, establishing the computational complexity result and demonstrate the advantage of our instance generation procedure over public benchmarks. We evaluate a variety of existing LLM-assisted planning methods on instances generated using our procedure. Our results show that, unlike other domains like 24 Game (a special case of Countdown), our proposed dynamic benchmark remains extremely challenging for existing LLM-based approaches.