From Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
作者: Bowen Cao, Dongdong Zhang, Yixia Li, Junpeng Liu, Shijue Huang, Chufan Shi, Hongyuan Lu, Yaokang Wu, Guanhua Chen, Wai Lam, Furu Wei
分类: cs.AI
发布日期: 2026-04-06
💡 一句话要点
ContextMATH基准测试揭示大语言模型在上下文数学推理中问题建模能力的不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 上下文理解 问题建模 基准测试
📋 核心要点
- 现有大语言模型在抽象数学问题上表现出色,但在实际场景中,由于缺乏问题建模能力,性能显著下降。
- 论文提出ContextMATH基准,包含场景接地和复杂性缩放两种设置,评估模型在现实场景下的数学推理能力。
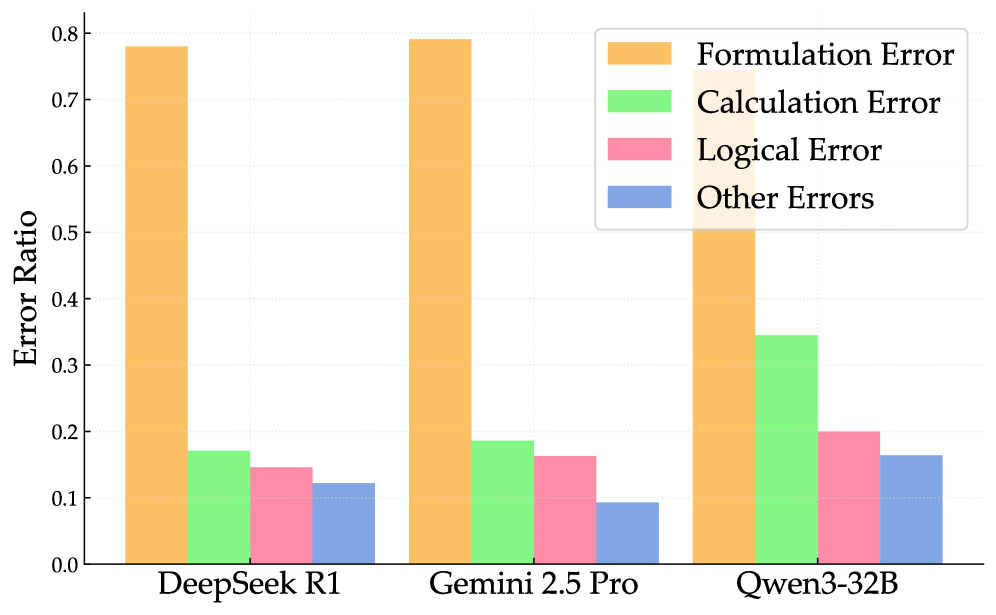
- 实验表明,模型在ContextMATH上性能大幅下降,错误主要源于不正确的公式化问题,表明问题建模是关键瓶颈。
📝 摘要(中文)
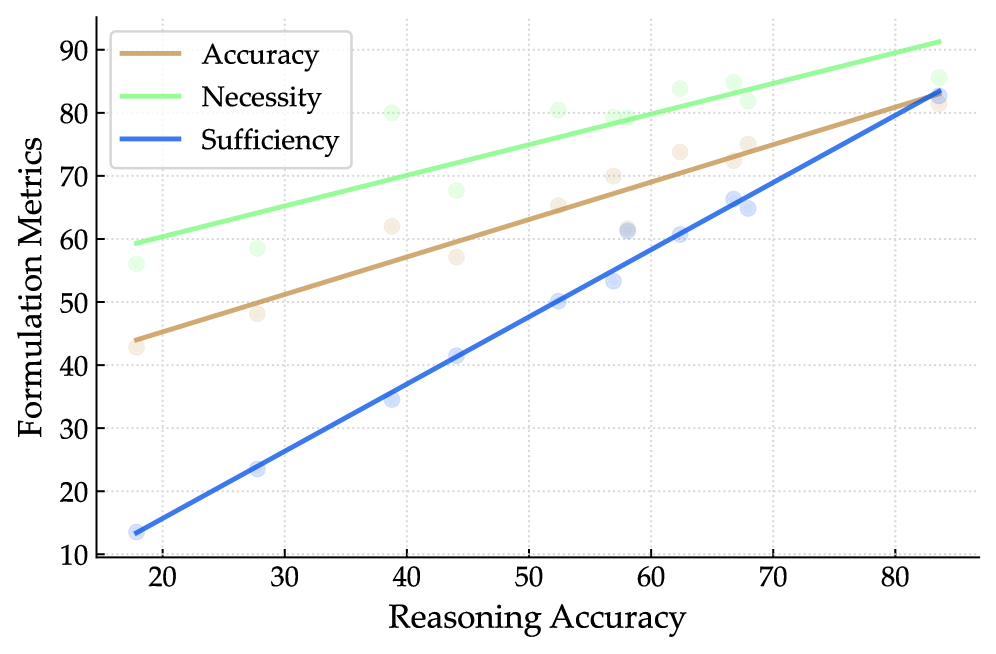
大型语言模型(LLMs)在基准数学问题上已达到接近专家的水平,但这种进步并未完全转化为实际应用中的可靠性能。本文通过上下文数学推理研究了这一差距,其中数学核心必须从描述性场景中构建。我们引入了ContextMATH,这是一个将AIME和MATH-500问题重新用于两个上下文设置的基准:场景接地(SG),将抽象问题嵌入到现实叙述中而不增加推理复杂性;复杂性缩放(CS),将显式条件转换为子问题,以捕捉约束在实践中出现的频率。对61个专有和开源模型进行评估,我们观察到明显的下降:平均而言,开源模型在SG和CS上分别下降13和34个百分点,而专有模型下降13和20个百分点。错误分析表明,错误主要由不正确的公式化问题主导,公式化准确性随着原始问题难度的增加而降低。正确的公式化成为成功的先决条件,其充分性随着模型规模的扩大而提高,表明更大的模型在理解和推理方面都有进步。然而,公式化和推理仍然是限制上下文数学问题解决的两个互补瓶颈。最后,我们发现使用场景数据进行微调可以提高性能,而仅使用公式化进行训练是无效的。然而,性能差距仅得到部分缓解,突显了上下文数学推理是LLM面临的一个尚未解决的核心挑战。
🔬 方法详解
问题定义:现有的大语言模型在解决抽象的数学问题时表现出了强大的能力,但是在实际应用场景中,数学问题往往不是直接给出的,而是隐藏在复杂的上下文信息中。模型需要首先理解上下文,然后将问题转化为数学形式才能进行求解。现有的方法在处理这种上下文数学推理问题时,由于缺乏有效的问题建模能力,性能会显著下降。因此,如何提高模型在复杂上下文中的数学问题建模能力是一个重要的研究问题。
核心思路:论文的核心思路是构建一个更贴近实际应用场景的数学推理基准,即ContextMATH。该基准通过将现有的数学问题(AIME和MATH-500)嵌入到两种不同的上下文设置中,来模拟实际场景中数学问题的复杂性和多样性。这两种设置分别是场景接地(SG)和复杂性缩放(CS)。通过在这个基准上评估各种大语言模型的性能,可以更准确地了解模型在上下文数学推理方面的能力,并找出模型存在的不足。
技术框架:ContextMATH基准包含两个主要组成部分:场景接地(SG)和复杂性缩放(CS)。SG通过将抽象的数学问题嵌入到现实的叙述中,来模拟实际场景中问题描述的复杂性。CS则通过将显式的条件转化为子问题,来模拟实际场景中约束条件的隐蔽性。论文使用AIME和MATH-500数据集中的问题作为基础,然后根据SG和CS的设置对问题进行修改,生成新的数据集。然后,论文使用这些数据集来评估各种大语言模型的性能。
关键创新:ContextMATH基准的主要创新在于它更贴近实际应用场景,能够更准确地评估模型在上下文数学推理方面的能力。与传统的数学推理基准相比,ContextMATH不仅考察了模型的数学推理能力,还考察了模型的问题建模能力。这使得ContextMATH能够更全面地反映模型在实际应用中的性能。
关键设计:ContextMATH基准的关键设计在于SG和CS两种设置。SG通过引入现实的叙述,增加了问题描述的复杂性,使得模型需要从叙述中提取关键信息才能进行求解。CS通过将显式的条件转化为子问题,增加了约束条件的隐蔽性,使得模型需要进行更深入的推理才能找到解决方案。此外,论文还对AIME和MATH-500数据集中的问题进行了筛选和修改,以确保数据集的质量和难度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,无论是开源模型还是专有模型,在ContextMATH基准上的性能都出现了显著下降。开源模型在SG和CS上分别下降13和34个百分点,而专有模型下降13和20个百分点。错误分析表明,错误主要由不正确的公式化问题主导,公式化准确性随着原始问题难度的增加而降低。这表明,问题建模是当前大语言模型在上下文数学推理方面的一个重要瓶颈。
🎯 应用场景
该研究成果可应用于智能教育、智能客服、金融分析等领域。例如,在智能教育中,可以帮助学生理解实际场景中的数学问题,提高解决实际问题的能力。在智能客服中,可以帮助客服人员理解用户提出的问题,并提供准确的解决方案。在金融分析中,可以帮助分析师从复杂的市场数据中提取关键信息,并进行预测。
📄 摘要(原文)
Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.