StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
作者: Jialin Yang, Dongfu Jiang, Lipeng He, Sherman Siu, Yuxuan Zhang, Disen Liao, Zhuofeng Li, Huaye Zeng, Yiming Jia, Haozhe Wang, Benjamin Schneider, Chi Ruan, Wentao Ma, Zhiheng Lyu, Yifei Wang, Yi Lu, Quy Duc Do, Ziyan Jiang, Ping Nie, Wenhu Chen
分类: cs.SE, cs.AI, cs.CL
发布日期: 2026-04-06
💡 一句话要点
StructEval:构建LLM结构化输出能力评测基准,揭示模型在多种格式上的性能差距。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 结构化输出 评测基准 格式保真度 结构正确性
📋 核心要点
- 现有LLM在生成结构化输出时面临格式保真和结构正确性的挑战,限制了其在软件开发中的应用。
- StructEval通过生成和转换两种任务范式,系统评估LLM在多种结构化格式上的输出能力。
- 实验结果表明,即使是先进的LLM在结构化输出任务中仍存在显著差距,尤其是在生成任务和视觉内容方面。
📝 摘要(中文)
随着大型语言模型(LLMs)在软件开发流程中变得不可或缺,它们生成结构化输出的能力至关重要。我们推出了StructEval,这是一个综合性的基准,用于评估LLMs生成非渲染(JSON、YAML、CSV)和渲染(HTML、React、SVG)结构化格式的能力。与之前的基准不同,StructEval通过两种范式系统地评估跨多种格式的结构保真度:1)生成任务,从自然语言提示生成结构化输出;2)转换任务,在结构化格式之间进行翻译。我们的基准包含18种格式和44种任务类型,并具有用于格式遵守和结构正确性的新颖指标。结果表明存在显著的性能差距——即使是最先进的模型如o1-mini也仅达到75.58的平均分,而开源替代方案落后约10分。我们发现生成任务比转换任务更具挑战性,并且生成正确的视觉内容比生成纯文本结构更困难。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成结构化输出时面临的挑战。现有的方法缺乏对LLM在不同结构化格式(如JSON、HTML等)上的生成能力进行全面、系统的评估。此外,现有方法难以衡量LLM生成的结构化输出的格式保真度和结构正确性,阻碍了LLM在软件开发等领域的应用。
核心思路:论文的核心思路是构建一个综合性的评测基准StructEval,通过设计生成任务和转换任务,全面评估LLM在多种结构化格式上的输出能力。StructEval不仅关注LLM能否生成符合格式要求的输出,还关注输出的结构是否正确,从而更准确地反映LLM的结构化输出能力。
技术框架:StructEval包含两个主要任务范式:生成任务和转换任务。生成任务要求LLM根据自然语言提示生成结构化输出,例如根据描述生成JSON对象或HTML页面。转换任务要求LLM在不同的结构化格式之间进行转换,例如将JSON对象转换为YAML文件。StructEval涵盖18种格式和44种任务类型,并设计了新的指标来衡量格式遵守和结构正确性。
关键创新:StructEval的关键创新在于其全面性和系统性。它不仅涵盖了多种结构化格式,还设计了生成和转换两种任务范式,从而更全面地评估LLM的结构化输出能力。此外,StructEval还提出了新的指标来衡量格式遵守和结构正确性,从而更准确地评估LLM的输出质量。
关键设计:StructEval的关键设计包括任务类型的选择、评估指标的设计和数据集的构建。任务类型的选择需要覆盖常见的结构化格式和应用场景。评估指标的设计需要能够准确衡量格式遵守和结构正确性。数据集的构建需要保证数据的多样性和质量。
🖼️ 关键图片


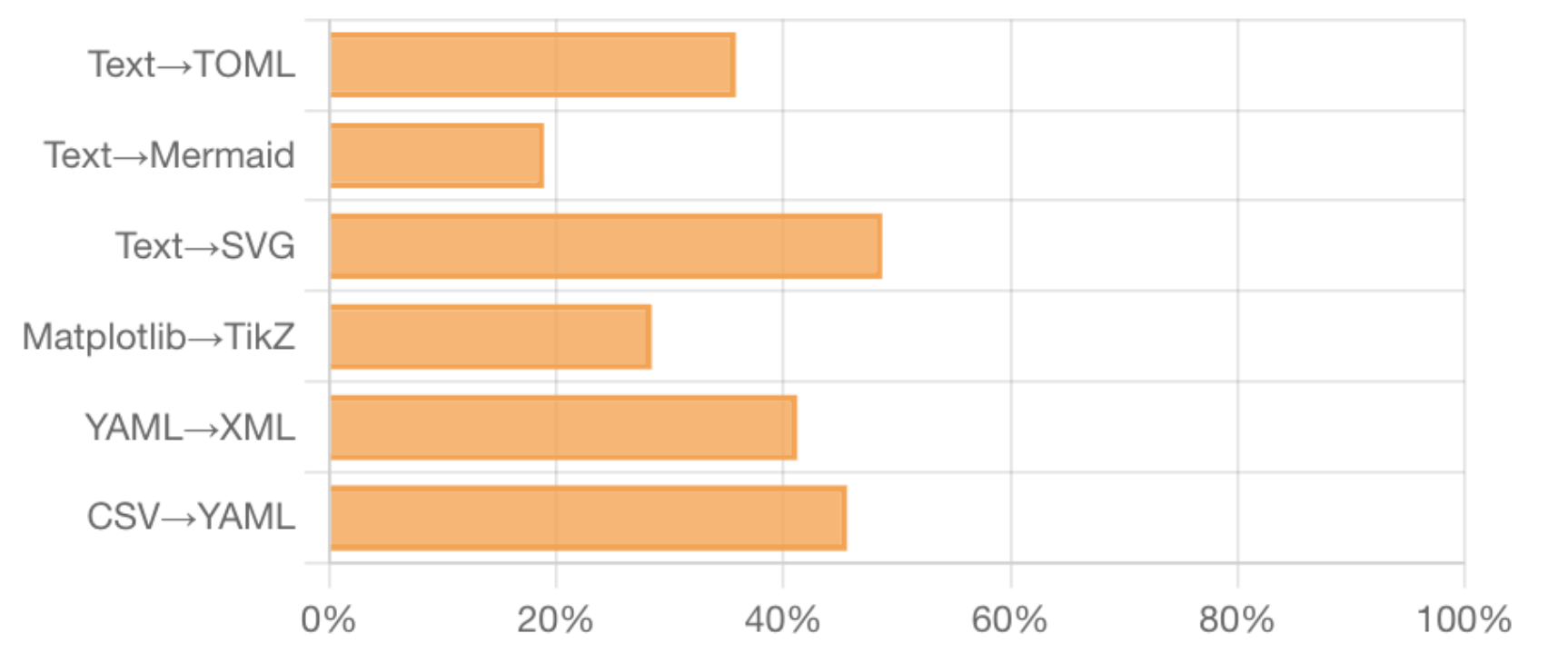
📊 实验亮点
StructEval的实验结果表明,即使是最先进的LLM(如o1-mini)在结构化输出任务中也存在显著差距,平均得分仅为75.58。开源LLM的性能落后于闭源LLM约10分。生成任务比转换任务更具挑战性,生成正确的视觉内容比生成纯文本结构更困难。这些结果揭示了LLM在结构化输出方面的局限性,为未来的研究方向提供了指导。
🎯 应用场景
StructEval的研究成果可应用于评估和改进LLM在软件开发、数据处理、网页生成等领域的结构化输出能力。通过StructEval,开发者可以选择更适合特定任务的LLM,并针对性地改进LLM的结构化输出能力,从而提高软件开发效率和数据处理质量。未来,StructEval可以扩展到更多结构化格式和任务类型,并与其他评测基准相结合,形成更全面的LLM评估体系。
📄 摘要(原文)
As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and \textbf{2)} conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps-even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.