Automated Vulnerability Detection in Source Code Using Deep Representation Learning
作者: C. Seas, G. Fitzpatrick, J. A. Hamilton, M. C. Carlisle
分类: cs.CR, cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出基于深度学习的C代码漏洞自动检测方法,提升漏洞召回率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 漏洞检测 深度学习 卷积神经网络 C代码 软件安全
📋 核心要点
- 现有软件漏洞检测方法存在精度和召回率的挑战,尤其是在复杂C代码中。
- 利用卷积神经网络学习C代码的深层表示,从而自动识别潜在的漏洞。
- 实验表明,该模型在C代码漏洞检测中实现了更高的召回率,同时保持了较高的精度。
📝 摘要(中文)
本文提出了一种基于卷积神经网络的C代码漏洞自动检测模型,旨在解决软件漏洞带来的安全风险。该模型使用两个互补的数据集进行训练:一个是Draper Labs使用静态分析器自动标注的数据集,另一个是NIST SATE Juliet人工标注的数据集,后者专门用于测试静态分析器。与Russell等人先前的工作不同,本文专注于C语言程序,从而能够针对该语言进行专门的优化。在去除重复数据后,将输入代码标记化为91个token类别,并将类别值转换为二进制向量以节省内存。模型使用卷积和池化层提取特征,然后使用全连接层将程序分类到常见的弱点枚举类别或标记为“干净”。实验结果表明,在保持高精度的前提下,本文方法比Russell等人的工作获得了更高的召回率。此外,还在定制的Linux内核数据集上验证了该方法在复杂代码中发现真实漏洞的能力,且具有较低的误报率。
🔬 方法详解
问题定义:论文旨在解决C代码中软件漏洞的自动检测问题。现有的静态分析器虽然可以检测漏洞,但通常存在较高的误报率和漏报率,尤其是在处理复杂的C代码时。此外,人工审计代码既耗时又容易出错。因此,需要一种能够自动、准确地检测C代码漏洞的方法。
核心思路:论文的核心思路是利用深度学习技术,特别是卷积神经网络(CNN),从C代码中学习到漏洞的深层表示。通过在大规模数据集上训练CNN模型,使其能够自动识别代码中的漏洞模式。这种方法避免了人工特征工程的需要,并且能够捕捉到传统静态分析器难以发现的复杂漏洞。
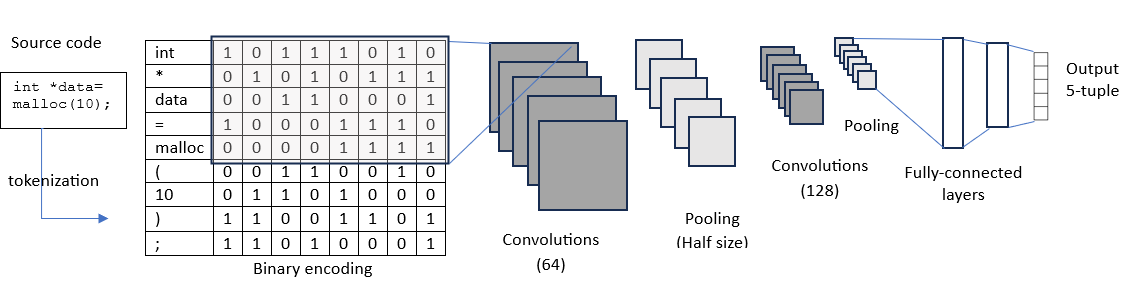
技术框架:整体框架包括以下几个主要步骤:1) 数据预处理:首先,从Draper Labs和NIST SATE Juliet数据集中收集C代码样本,并去除重复项。2) 代码标记化:将C代码分解为token序列,共计91个token类别。3) 特征编码:将每个token类别转换为二进制向量,以节省内存空间。4) 模型训练:使用卷积神经网络对token序列进行训练,学习漏洞的深层表示。5) 漏洞分类:使用全连接层将程序分类到常见的弱点枚举(CWE)类别或标记为“干净”。
关键创新:该论文的关键创新在于将深度学习技术应用于C代码漏洞检测,并针对C语言的特点进行了优化。与以往基于静态分析器或人工特征工程的方法相比,该方法能够自动学习漏洞的深层表示,从而提高检测的准确性和召回率。此外,论文还通过使用二进制向量编码token类别,有效地节省了内存空间。
关键设计:在网络结构方面,论文使用了两个卷积层和两个池化层,用于提取代码的局部特征。第一个卷积层的滤波器大小被设置为覆盖整个token的编码,以便能够捕捉到token之间的关系。损失函数未知,但推测使用了交叉熵损失函数进行分类任务。数据集由Draper Labs和NIST SATE Juliet组成,并进行了去重处理。具体训练参数未知。
🖼️ 关键图片

📊 实验亮点
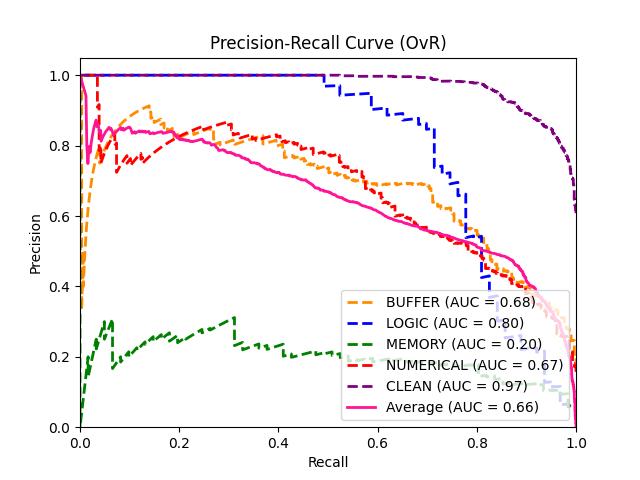
实验结果表明,该模型在C代码漏洞检测中取得了显著的性能提升。在保持高精度的前提下,该模型比Russell等人的工作获得了更高的召回率。此外,在定制的Linux内核数据集上的实验表明,该模型能够以较低的误报率发现真实漏洞,验证了其在复杂代码中的有效性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于软件安全领域,帮助开发人员自动检测和修复C代码中的漏洞,提高软件的安全性。此外,该方法还可以用于安全审计、恶意代码分析等领域,具有广泛的应用前景。未来,可以将该方法扩展到其他编程语言,并结合其他安全分析技术,进一步提高漏洞检测的准确性和效率。
📄 摘要(原文)
Each year, software vulnerabilities are discovered, which pose significant risks of exploitation and system compromise. We present a convolutional neural network model that can successfully identify bugs in C code. We trained our model using two complementary datasets: a machine-labeled dataset created by Draper Labs using three static analyzers and the NIST SATE Juliet human-labeled dataset designed for testing static analyzers. In contrast with the work of Russell et al. on these datasets, we focus on C programs, enabling us to specialize and optimize our detection techniques for this language. After removing duplicates from the dataset, we tokenize the input into 91 token categories. The category values are converted to a binary vector to save memory. Our first convolution layer is chosen so that the entire encoding of the token is presented to the filter. We use two convolution and pooling layers followed by two fully connected layers to classify programs into either a common weakness enumeration category or as ``clean.'' We obtain higher recall than prior work by Russell et al. on this dataset when requiring high precision. We also demonstrate on a custom Linux kernel dataset that we are able to find real vulnerabilities in complex code with a low false-positive rate.