NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
作者: Ishaan Rawal, Shubh Gupta, Yihan Hu, Wei Zhan
分类: cs.AI, cs.CV
发布日期: 2026-02-28
💡 一句话要点
提出NoRD,一种数据高效的免推理端到端自动驾驶VLA模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言-动作模型 数据高效 难度偏差 策略优化 Dr. GRPO 端到端学习
📋 核心要点
- 现有VLA模型依赖海量数据和密集推理标注,成本高昂,限制了其在自动驾驶领域的应用。
- NORD通过在少量数据上微调,并去除推理标注,降低了VLA模型的训练成本,提升了效率。
- NORD集成了Dr. GRPO算法,缓解了难度偏差问题,在Waymo和NAVSIM数据集上取得了竞争力的性能。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过用统一的端到端架构取代模块化流程,正在推动自动驾驶的发展。然而,当前的VLA面临两个昂贵的要求:(1)海量数据集的收集,以及(2)密集的推理标注。本文通过NORD(No Reasoning for Driving)来解决这两个挑战。与现有的VLA相比,NORD在不到60%的数据上进行微调,且无需推理标注,就能达到具有竞争力的性能,从而减少了3倍的tokens。我们发现,当应用于在如此小的、无推理数据集上训练的策略时,标准组相对策略优化(GRPO)无法产生显著的改进。我们表明,这种限制源于难度偏差,它不成比例地惩罚了GRPO中产生高方差rollout的场景中的奖励信号。NORD通过结合Dr. GRPO克服了这一点,Dr. GRPO是一种旨在减轻LLM中难度偏差的最新算法。因此,NORD在Waymo和NAVSIM上以一小部分训练数据和零推理开销实现了具有竞争力的性能,从而实现了更高效的自动驾驶系统。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在自动驾驶领域取得了进展,但它们需要大量的数据和密集的推理标注,这使得训练成本很高,并且限制了它们的应用。现有的方法在小数据集上表现不佳,并且难以处理难度偏差问题。
核心思路:NORD的核心思路是通过减少数据需求和去除推理标注来提高VLA模型的效率。它通过使用更小的数据集进行微调,并结合Dr. GRPO算法来缓解难度偏差,从而在不牺牲性能的情况下降低了训练成本。这样设计的目的是使VLA模型更易于训练和部署。
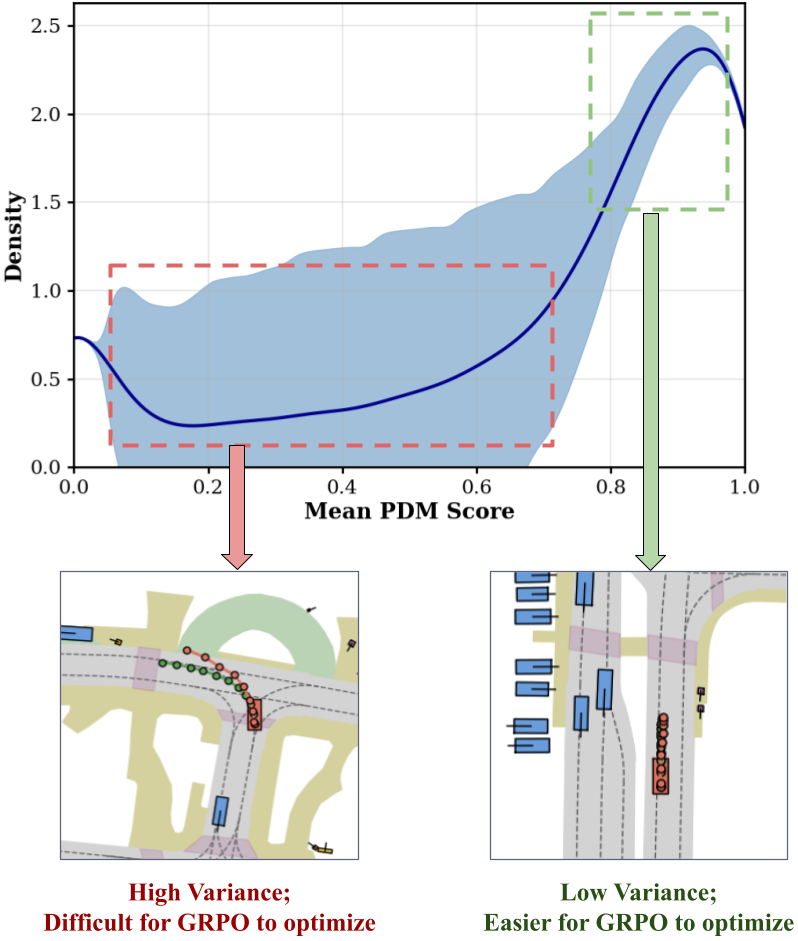
技术框架:NORD的整体框架包括一个视觉编码器、一个语言编码器和一个动作预测器。视觉编码器处理来自摄像头的图像,语言编码器处理导航指令。然后,这两个编码器的输出被融合,并输入到动作预测器中,以生成车辆的控制命令。NORD使用Group Relative Policy Optimization (GRPO)进行训练,并集成了Dr. GRPO算法来缓解难度偏差。
关键创新:NORD的关键创新在于它能够在少量数据和无推理标注的情况下实现具有竞争力的性能。这主要是通过结合Dr. GRPO算法来实现的,该算法能够有效地缓解难度偏差,从而提高模型的训练效率和泛化能力。
关键设计:NORD的关键设计包括使用预训练的视觉和语言编码器来减少训练数据需求,以及使用Dr. GRPO算法来缓解难度偏差。Dr. GRPO算法通过调整奖励信号的权重,来减少对高方差rollout的惩罚,从而提高模型的训练稳定性。
🖼️ 关键图片


📊 实验亮点
NORD在Waymo和NAVSIM数据集上取得了具有竞争力的性能,同时使用了不到60%的训练数据,并且无需推理标注。与现有的VLA模型相比,NORD减少了3倍的tokens。通过集成Dr. GRPO算法,NORD有效地缓解了难度偏差,提高了模型的训练效率和泛化能力。这些实验结果表明,NORD是一种高效且实用的自动驾驶VLA模型。
🎯 应用场景
NORD具有广泛的应用前景,可以应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。它还可以用于训练自动驾驶模拟器,以及开发更高效的自动驾驶算法。该研究的实际价值在于降低了自动驾驶系统的开发成本,并加速了自动驾驶技术的普及。未来,NORD可以进一步扩展到其他机器人领域,例如家庭服务机器人和工业机器人。
📄 摘要(原文)
Vision-Language-Action (VLA) models are advancing autonomous driving by replacing modular pipelines with unified end-to-end architectures. However, current VLAs face two expensive requirements: (1) massive dataset collection, and (2) dense reasoning annotations. In this work, we address both challenges with NORD (No Reasoning for Driving). Compared to existing VLAs, NORD achieves competitive performance while being fine-tuned on <60% of the data and no reasoning annotations, resulting in 3x fewer tokens. We identify that standard Group Relative Policy Optimization (GRPO) fails to yield significant improvements when applied to policies trained on such small, reasoning-free datasets. We show that this limitation stems from difficulty bias, which disproportionately penalizes reward signals from scenarios that produce high-variance rollouts within GRPO. NORD overcomes this by incorporating Dr. GRPO, a recent algorithm designed to mitigate difficulty bias in LLMs. As a result, NORD achieves competitive performance on Waymo and NAVSIM with a fraction of the training data and no reasoning overhead, enabling more efficient autonomous systems. Website:this https URL