Large-scale online deanonymization with LLMs
作者: Simon Lermen, Daniel Paleka, Joshua Swanson, Michael Aerni, Nicholas Carlini, Florian Tramèr
分类: cs.CR, cs.AI, cs.LG
发布日期: 2026-02-28
💡 一句话要点
利用大型语言模型实现大规模在线去匿名化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 去匿名化 大型语言模型 自然语言处理 在线隐私 非结构化数据
📋 核心要点
- 现有去匿名化方法依赖结构化数据,难以处理互联网上大量的非结构化用户内容,限制了其应用范围。
- 利用大型语言模型强大的语义理解和推理能力,从非结构化文本中提取身份特征,进行跨平台用户匹配。
- 实验表明,基于LLM的方法在多个数据集上显著优于传统方法,去匿名化效果大幅提升,对在线隐私构成威胁。
📝 摘要(中文)
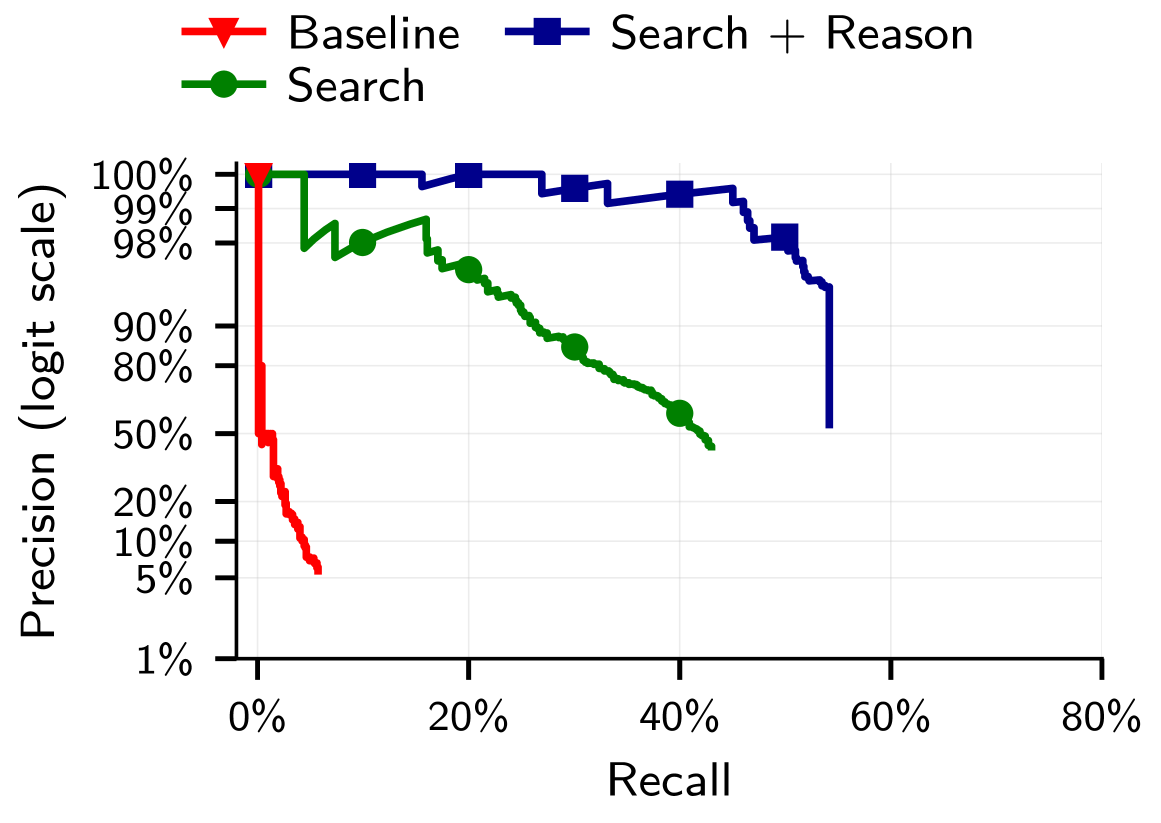
本文展示了大型语言模型可用于执行大规模去匿名化。通过完全的互联网访问,我们的代理能够以高精度重新识别Hacker News用户和Anthropic Interviewer参与者,仅需使用假名在线个人资料和对话,这与人类调查员花费数小时才能完成的工作相匹配。然后,我们设计了封闭世界的攻击。给定两个假名个人数据库,每个数据库都包含由该个人撰写或关于该个人的非结构化文本,我们实现了一个可扩展的攻击管道,该管道使用LLM来:(1)提取身份相关特征,(2)通过语义嵌入搜索候选匹配项,以及(3)推理最佳候选匹配项以验证匹配项并减少误报。与需要结构化数据的经典去匿名化工作(例如,Netflix奖)相比,我们的方法直接在任意平台上的原始用户内容上工作。我们构建了三个具有已知真实数据的数据集来评估我们的攻击。第一个将Hacker News链接到LinkedIn个人资料,使用个人资料中出现的跨平台引用。我们的第二个数据集匹配Reddit电影讨论社区中的用户;第三个数据集按时间分割单个用户的Reddit历史记录,以创建两个要匹配的假名个人资料。在每种情况下,基于LLM的方法都大大优于经典基线,在90%的精度下实现了高达68%的召回率,而最佳非LLM方法的召回率接近0%。我们的结果表明,保护在线假名用户的实际模糊性不再成立,并且需要重新考虑在线隐私的威胁模型。
🔬 方法详解
问题定义:论文旨在解决大规模在线环境中,利用非结构化文本数据对匿名用户进行身份识别的问题。现有方法,如传统的去匿名化技术,通常依赖于结构化数据,例如用户评分或购买记录。然而,互联网上的大量用户数据是非结构化的,例如论坛帖子、社交媒体发言等。这些数据包含丰富的个人信息,但难以被传统方法有效利用。因此,如何从非结构化文本中提取身份相关信息,并实现准确的用户匹配,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的自然语言处理能力,从非结构化文本中提取身份相关的特征,并进行跨平台的用户匹配。LLM能够理解文本的语义信息,识别出用户在不同平台上的行为模式和个人偏好,从而实现高精度的去匿名化。这种方法无需依赖结构化数据,可以直接处理原始用户内容,具有更广泛的适用性。
技术框架:论文提出的去匿名化框架主要包含以下几个阶段:1) 特征提取:利用LLM从用户的文本数据中提取身份相关的特征,例如兴趣爱好、写作风格、个人经历等。2) 候选匹配:使用语义嵌入技术,在目标数据库中搜索与源用户特征相似的候选匹配项。3) 匹配验证:利用LLM对候选匹配项进行推理和验证,判断其是否与源用户为同一人。该阶段旨在减少误报,提高去匿名化的准确率。
关键创新:论文最重要的技术创新在于将大型语言模型应用于去匿名化任务,并成功地处理了非结构化文本数据。与传统的去匿名化方法相比,该方法无需依赖结构化数据,可以直接处理原始用户内容,具有更广泛的适用性。此外,论文还提出了一种可扩展的攻击管道,能够高效地处理大规模数据集。
关键设计:论文的关键设计包括:1) 使用预训练的LLM模型,例如BERT或GPT系列,进行特征提取。2) 使用语义嵌入技术,例如Sentence-BERT,将文本数据转换为向量表示,以便进行相似度计算。3) 设计合适的提示工程(Prompt Engineering),引导LLM进行推理和验证。4) 针对不同的数据集,调整LLM的参数和训练策略,以获得最佳的去匿名化效果。
🖼️ 关键图片

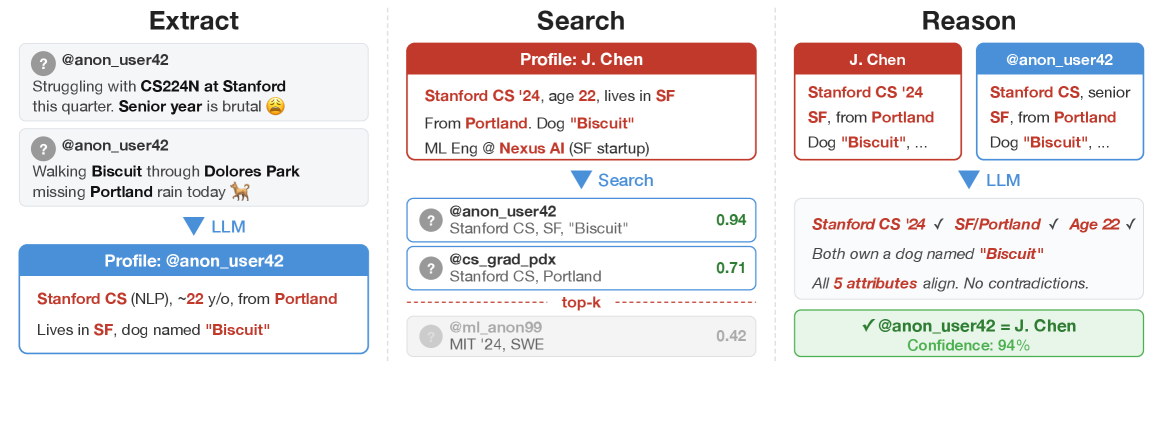
📊 实验亮点
实验结果表明,基于LLM的方法在三个数据集上均显著优于传统基线方法。在Hacker News到LinkedIn的匹配任务中,基于LLM的方法在90%精度下实现了高达68%的召回率,而最佳非LLM方法的召回率接近0%。在Reddit电影讨论社区的用户匹配任务中,基于LLM的方法也取得了显著的性能提升。这些结果表明,LLM在去匿名化任务中具有强大的能力。
🎯 应用场景
该研究成果可应用于网络安全、情报分析、用户画像等领域。例如,可以帮助识别恶意网络行为者,追踪网络犯罪,或者为企业提供更精准的用户画像服务。然而,该研究也揭示了在线隐私面临的严峻挑战,提醒人们需要重新审视在线隐私保护策略,并采取更有效的措施来保护个人信息。
📄 摘要(原文)
We show that large language models can be used to perform at-scale deanonymization. With full Internet access, our agent can re-identify Hacker News users and Anthropic Interviewer participants at high precision, given pseudonymous online profiles and conversations alone, matching what would take hours for a dedicated human investigator. We then design attacks for the closed-world setting. Given two databases of pseudonymous individuals, each containing unstructured text written by or about that individual, we implement a scalable attack pipeline that uses LLMs to: (1) extract identity-relevant features, (2) search for candidate matches via semantic embeddings, and (3) reason over top candidates to verify matches and reduce false positives. Compared to classical deanonymization work (e.g., on the Netflix prize) that required structured data, our approach works directly on raw user content across arbitrary platforms. We construct three datasets with known ground-truth data to evaluate our attacks. The first links Hacker News to LinkedIn profiles, using cross-platform references that appear in the profiles. Our second dataset matches users across Reddit movie discussion communities; and the third splits a single user's Reddit history in time to create two pseudonymous profiles to be matched. In each setting, LLM-based methods substantially outperform classical baselines, achieving up to 68% recall at 90% precision compared to near 0% for the best non-LLM method. Our results show that the practical obscurity protecting pseudonymous users online no longer holds and that threat models for online privacy need to be reconsidered.