Unmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
作者: Xiang Zheng, Weiqi Zhai, Wei Wang, Boyu Yang, Wenbo Li, Ruixiang Luo, Haoxiang Sun, Yucheng Wang, Zhengze Li, Meng Wang, Yuetian Du, Guojie Lin, Yaxuan Wang, Xiaoxiao Xu, Yanhu Mo, Xuan Ren, Hu Wei, Bing Zhao
分类: cs.AI, cs.CL
发布日期: 2026-02-28
💡 一句话要点
提出 ReasoningMath-Plus 基准,用于评估LLM在结构化数学推理中的过程能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 结构化推理 基准数据集 过程评估
📋 核心要点
- 现有数学推理基准过度依赖模板计算,无法有效评估LLM的结构化推理能力。
- 提出 ReasoningMath-Plus,包含强调多约束协调、逻辑综合和空间推理等结构化推理问题。
- 引入 HCRS 评分函数和 PRM 模型,用于细粒度的过程级评估,揭示答案正确但推理过程不佳的问题。
📝 摘要(中文)
现有大型语言模型(LLMs)在许多已建立的数学推理基准上取得了接近饱和的准确率,引发了对其诊断真正推理能力能力的担忧。这种饱和主要源于现有数据集中基于模板的计算和浅层算术分解的优势,这些数据集低估了诸如多约束协调、建设性逻辑综合和空间推理等推理技能。为了解决这个差距,我们引入了 ReasoningMath-Plus,这是一个由150个精心策划的问题组成的基准,专门用于评估结构化推理。每个问题都强调在交互约束下的推理、建设性解决方案的形成或非平凡的结构洞察力,并用最小的推理骨架进行注释,以支持细粒度的过程级评估。与数据集一起,我们引入了HCRS(Hazard-aware Chain-based Rule Score),一种确定性的步骤级评分函数,并在带注释的推理轨迹上训练过程奖励模型(PRM)。经验表明,虽然领先的模型获得了相对较高的最终答案准确率(高达5.8/10),但基于HCRS的整体评估产生了明显较低的分数(平均4.36/10,最佳5.14/10),表明仅答案指标可能会高估推理的鲁棒性。
🔬 方法详解
问题定义:现有数学推理基准存在过度依赖模板计算和浅层算术分解的问题,导致LLM在这些基准上表现出虚高的准确率,无法真实反映其结构化推理能力。这些基准缺乏对多约束协调、建设性逻辑综合和空间推理等复杂推理技能的有效评估,使得LLM可以通过简单的模式匹配和记忆来解决问题,而无需进行真正的推理。
核心思路:为了解决现有基准的不足,论文提出了 ReasoningMath-Plus 基准,该基准包含精心设计的结构化推理问题,旨在更全面地评估LLM的推理能力。核心思路是通过引入更复杂、更具挑战性的问题,迫使LLM进行真正的推理,而不是简单地依赖模板或记忆。同时,论文还提出了 HCRS 评分函数和 PRM 模型,用于细粒度的过程级评估,从而更准确地衡量LLM的推理过程质量。
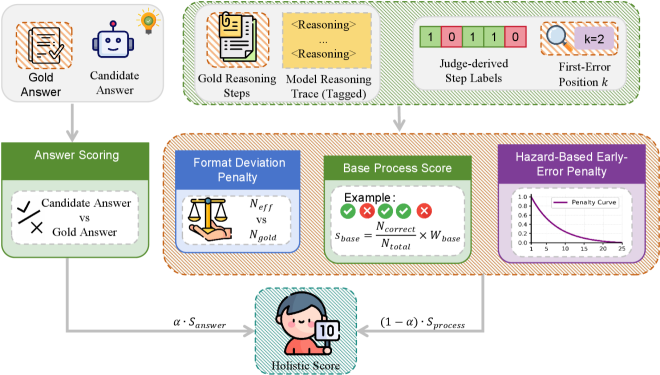
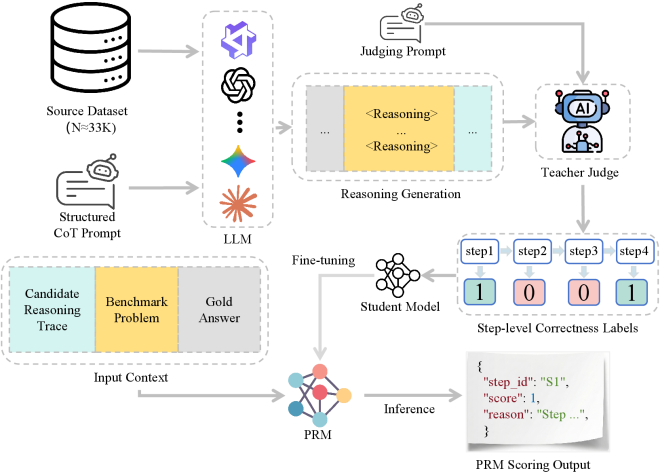
技术框架:该研究的技术框架主要包含三个部分:ReasoningMath-Plus 基准数据集的构建、HCRS 评分函数的定义和 PRM 模型的训练。首先,人工设计并收集了150个强调结构化推理的问题,并对每个问题进行了推理骨架的标注。然后,定义了 HCRS 评分函数,用于评估LLM推理过程的每一步是否合理。最后,利用标注的推理轨迹训练了一个过程奖励模型(PRM),用于指导LLM生成更合理的推理过程。
关键创新:该论文的关键创新在于提出了 ReasoningMath-Plus 基准,该基准更有效地评估了LLM的结构化推理能力。与现有基准相比,ReasoningMath-Plus 包含的问题更复杂、更具挑战性,能够更好地区分具有真正推理能力的LLM和仅仅依赖模板或记忆的LLM。此外,HCRS 评分函数和 PRM 模型的引入,使得可以对LLM的推理过程进行细粒度的评估,从而更准确地衡量其推理质量。
关键设计:HCRS 评分函数的设计考虑了推理过程中的潜在风险(Hazard),并基于链式规则进行评分。PRM 模型的训练使用了标注的推理轨迹作为监督信号,并通过奖励机制鼓励LLM生成更合理的推理过程。具体的技术细节包括 HCRS 评分函数的具体计算公式、PRM 模型的网络结构和训练参数等,但论文摘要中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,尽管领先的LLM在 ReasoningMath-Plus 基准上获得了相对较高的最终答案准确率(高达5.8/10),但基于 HCRS 的整体评估分数明显较低(平均4.36/10,最佳5.14/10)。这表明,仅依赖答案准确率可能会高估LLM的推理能力,而 HCRS 评分函数能够更准确地反映其推理过程的质量。该结果突出了 ReasoningMath-Plus 基准和 HCRS 评分函数在评估LLM结构化推理能力方面的价值。
🎯 应用场景
该研究成果可应用于开发更可靠、更智能的AI系统,尤其是在需要复杂推理的领域,如科学发现、工程设计、金融分析等。通过更准确地评估LLM的推理能力,可以更好地选择和优化模型,从而提高AI系统在这些领域的性能和可靠性。此外,该研究还可以促进对LLM推理机制的深入理解,为开发更具通用性和可解释性的AI系统奠定基础。
📄 摘要(原文)
Recent large language models (LLMs) achieve near-saturation accuracy on many established mathematical reasoning benchmarks, raising concerns about their ability to diagnose genuine reasoning competence. This saturation largely stems from the dominance of template-based computation and shallow arithmetic decomposition in existing datasets, which underrepresent reasoning skills such as multi-constraint coordination, constructive logical synthesis, and spatial inference. To address this gap, we introduce ReasoningMath-Plus, a benchmark of 150 carefully curated problems explicitly designed to evaluate structural reasoning. Each problem emphasizes reasoning under interacting constraints, constructive solution formation, or non-trivial structural insight, and is annotated with a minimal reasoning skeleton to support fine-grained process-level evaluation. Alongside the dataset, we introduce HCRS (Hazard-aware Chain-based Rule Score), a deterministic step-level scoring function, and train a Process Reward Model (PRM) on the annotated reasoning traces. Empirically, while leading models attain relatively high final-answer accuracy (up to 5.8/10), HCRS-based holistic evaluation yields substantially lower scores (average 4.36/10, best 5.14/10), showing that answer-only metrics can overestimate reasoning robustness.