Towards Small Language Models for Security Query Generation in SOC Workflows
作者: Saleha Muzammil, Rahul Reddy, Vishal Kamalakrishnan, Hadi Ahmadi, Wajih Ul Hassan
分类: cs.CR, cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出面向安全运营中心工作流的小型语言模型,用于安全查询生成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言查询 小型语言模型 安全运营中心 Kusto查询语言 提示工程 微调 两阶段架构
📋 核心要点
- 安全运营中心分析师依赖KQL查询,但KQL专业知识的缺乏限制了团队扩展。
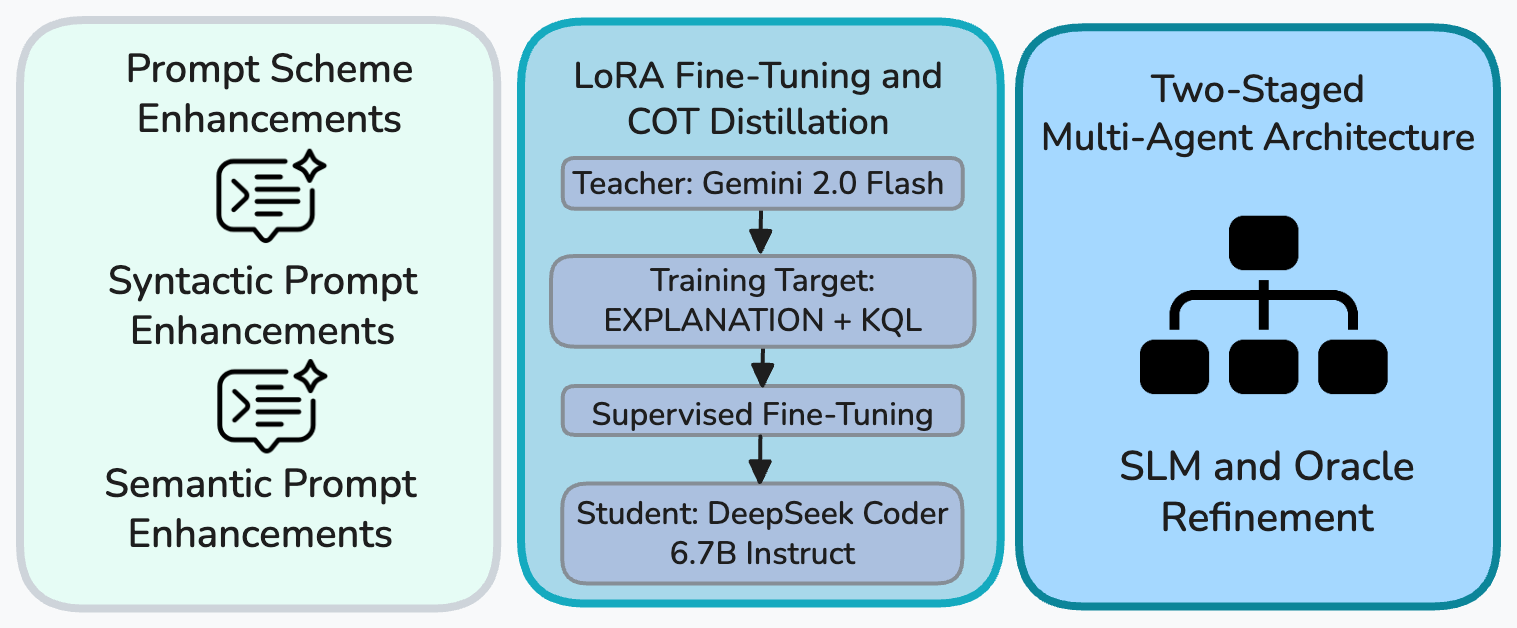
- 论文提出三旋钮框架,包括提示工程、微调和两阶段架构,优化SLM的NL2KQL翻译。
- 实验表明,该方法在语法和语义准确性上表现出色,且token成本远低于GPT-5。
📝 摘要(中文)
安全运营中心(SOC)的分析师通常使用Kusto查询语言(KQL)查询海量遥测数据流。编写正确的KQL需要专业的知识,这种依赖性在安全团队扩展时会造成瓶颈。本文研究了小型语言模型(SLM)是否能够为企业安全实现准确、经济高效的自然语言到KQL的翻译。我们提出了一个三旋钮框架,针对提示工程、微调和架构设计。首先,我们采用现有的NL2KQL框架用于SLM,通过轻量级检索并引入错误感知提示,解决常见的解析器故障,而不增加token数量。其次,我们应用LoRA微调与理由蒸馏,通过简短的链式思考解释来增强每个NLQ-KQL对,从而从教师模型传递推理能力,同时保持SLM的紧凑性。第三,我们提出了一种两阶段架构,使用SLM进行候选生成,并使用低成本LLM判断器进行模式感知细化和选择。我们评估了九个模型(五个SLM和四个LLM)在语法正确性、语义准确性、表选择和过滤器精度方面的性能,以及延迟和token成本。在微软的NL2KQL Defender Evaluation数据集上,我们的两阶段方法实现了0.987的语法准确率和0.906的语义准确率。我们进一步证明了在Microsoft Sentinel数据上的泛化能力,达到了0.964的语法准确率和0.831的语义准确率。这些结果表明,与GPT-5相比,token成本降低了高达10倍,从而确立了SLM作为安全运营中自然语言查询的实用、可扩展的基础。
🔬 方法详解
问题定义:论文旨在解决安全运营中心(SOC)分析师在编写Kusto查询语言(KQL)时面临的专业知识瓶颈问题。现有方法依赖于大型语言模型(LLM),成本高昂且效率较低,而直接使用小型语言模型(SLM)则面临准确率不足的挑战。
核心思路:论文的核心思路是利用小型语言模型(SLM)的低成本和高效率优势,并通过一系列优化技术,使其在自然语言到KQL的翻译任务中达到与大型语言模型相媲美的准确率。通过提示工程、微调和两阶段架构,提升SLM的性能。
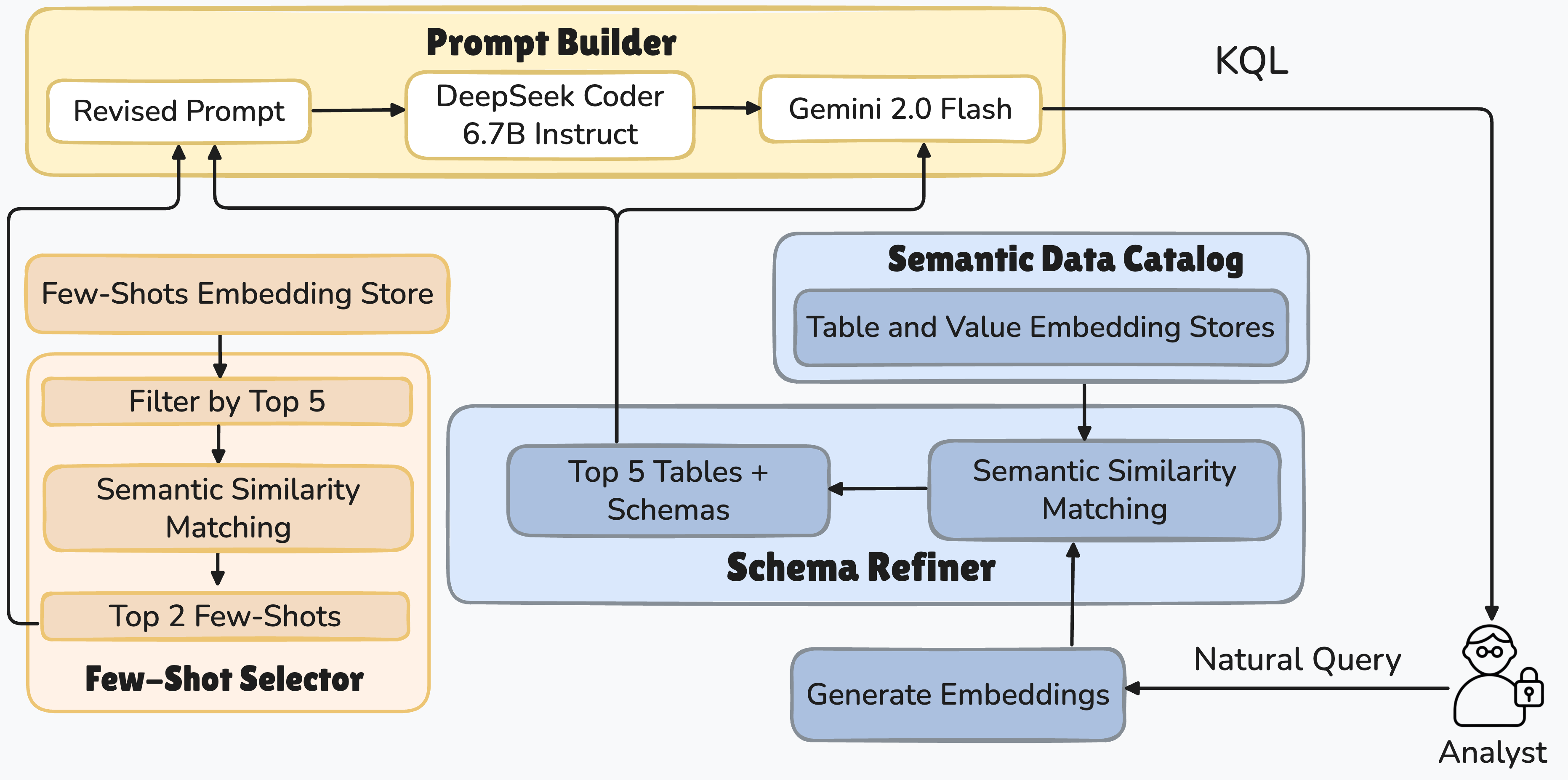
技术框架:论文提出了一个三旋钮框架,包含以下几个主要模块: 1. 提示工程:采用轻量级检索和错误感知提示,解决解析器故障。 2. 微调:使用LoRA微调和理由蒸馏,从教师模型传递推理能力。 3. 两阶段架构:第一阶段使用SLM生成候选KQL查询,第二阶段使用低成本LLM判断器进行模式感知细化和选择。
关键创新:论文的关键创新在于: 1. 针对SLM的NL2KQL框架优化,包括轻量级检索和错误感知提示。 2. 结合LoRA微调和理由蒸馏,提升SLM的推理能力。 3. 提出两阶段架构,利用SLM和LLM的优势,实现准确和高效的NL2KQL翻译。
关键设计: 1. 错误感知提示:针对常见的解析器错误,设计特定的提示,引导SLM生成正确的KQL查询。 2. 理由蒸馏:使用大型语言模型生成NLQ-KQL对的链式思考解释,作为微调SLM的额外信息。 3. LLM判断器:使用低成本LLM,根据KQL的模式信息,对SLM生成的候选查询进行细化和选择。
🖼️ 关键图片
📊 实验亮点
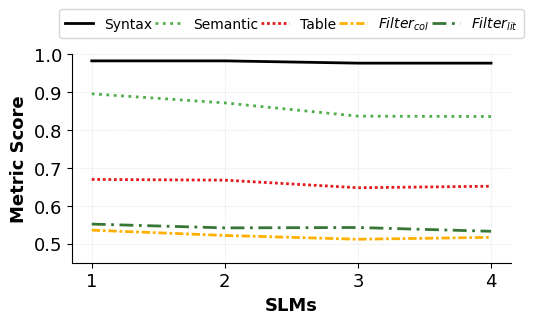
实验结果表明,该方法在Microsoft的NL2KQL Defender Evaluation数据集上实现了0.987的语法准确率和0.906的语义准确率,在Microsoft Sentinel数据上达到了0.964的语法准确率和0.831的语义准确率。与GPT-5相比,token成本降低了高达10倍。
🎯 应用场景
该研究成果可应用于安全运营中心,帮助分析师更高效地进行安全事件调查和威胁检测。通过自然语言查询,降低KQL的使用门槛,提高安全团队的工作效率。未来,该技术可扩展到其他领域的数据库查询和数据分析任务中。
📄 摘要(原文)
Analysts in Security Operations Centers routinely query massive telemetry streams using Kusto Query Language (KQL). Writing correct KQL requires specialized expertise, and this dependency creates a bottleneck as security teams scale. This paper investigates whether Small Language Models (SLMs) can enable accurate, cost-effective natural-language-to-KQL translation for enterprise security. We propose a three-knob framework targeting prompting, fine-tuning, and architecture design. First, we adapt existing NL2KQL framework for SLMs with lightweight retrieval and introduce error-aware prompting that addresses common parser failures without increasing token count. Second, we apply LoRA fine-tuning with rationale distillation, augmenting each NLQ-KQL pair with a brief chain-of-thought explanation to transfer reasoning from a teacher model while keeping the SLM compact. Third, we propose a two-stage architecture that uses an SLM for candidate generation and a low-cost LLM judge for schema-aware refinement and selection. We evaluate nine models (five SLMs and four LLMs) across syntax correctness, semantic accuracy, table selection, and filter precision, alongside latency and token cost. On Microsoft's NL2KQL Defender Evaluation dataset, our two-stage approach achieves 0.987 syntax and 0.906 semantic accuracy. We further demonstrate generalizability on Microsoft Sentinel data, reaching 0.964 syntax and 0.831 semantic accuracy. These results come at up to 10x lower token cost than GPT-5, establishing SLMs as a practical, scalable foundation for natural-language querying in security operations.