Intelligence per Watt: Measuring Intelligence Efficiency of Local AI
作者: Jon Saad-Falcon, Avanika Narayan, Hakki Orhun Akengin, J. Wes Griffin, Herumb Shandilya, Adrian Gamarra Lafuente, Medhya Goel, Rebecca Joseph, Shlok Natarajan, Etash Kumar Guha, Shang Zhu, Ben Athiwaratkun, John Hennessy, Azalia Mirhoseini, Christopher Ré
分类: cs.DC, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-28
💡 一句话要点
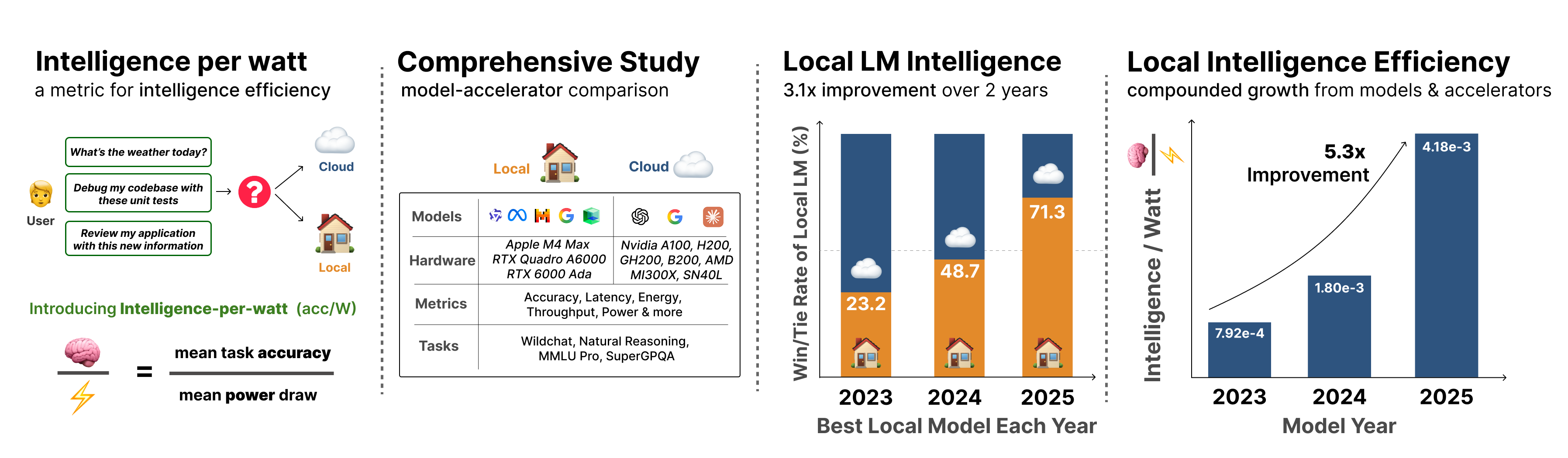
提出每瓦特智能(IPW)指标,评估本地AI的能效,推动云端负载向本地设备转移。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本地AI 能效评估 每瓦特智能 LLM推理 边缘计算
📋 核心要点
- 现有LLM推理主要依赖集中式云基础设施,面临日益增长的需求压力和扩展瓶颈。
- 提出每瓦特智能(IPW)指标,用于评估本地LLM在功率受限设备上的推理能力和效率。
- 实验表明,本地LLM在准确率和能效方面均有显著提升,具备分流云端负载的潜力。
📝 摘要(中文)
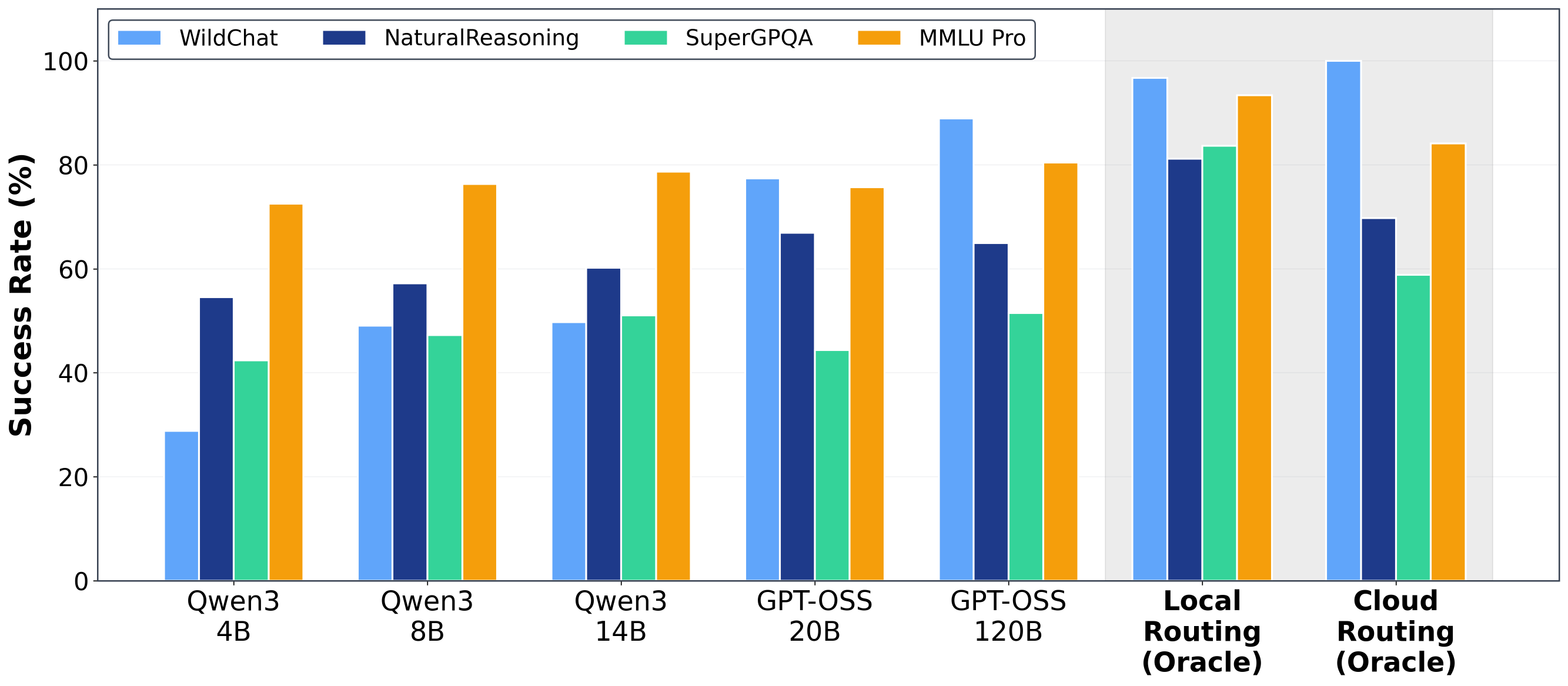
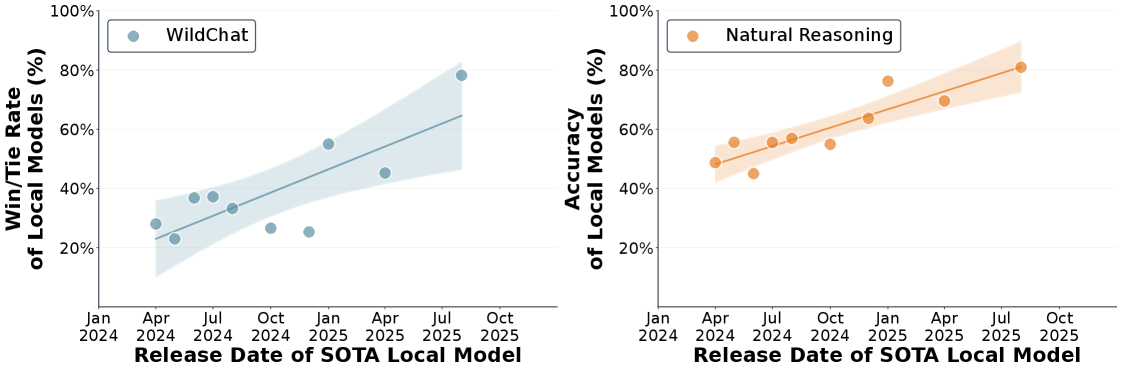
大型语言模型(LLM)的查询主要由集中式云基础设施中的前沿模型处理。快速增长的需求使这种模式紧张,云提供商难以跟上基础设施的扩展速度。小型LLM(<=20B活跃参数)在许多任务上实现了与前沿模型相当的性能,并且本地加速器(例如,Apple M4 Max)以交互式延迟运行这些模型。这引发了一个问题:本地推理是否可以有效地重新分配来自集中式基础设施的需求?为了回答这个问题,需要衡量本地LLM是否可以准确地回答真实世界的查询,以及它们是否能够以足够的效率在功率受限的设备(即笔记本电脑)上运行。我们提出了每瓦特智能(IPW),即任务准确率除以单位功率,作为评估模型-加速器对的本地推理能力和效率的指标。我们对20多个最先进的本地LLM、8个加速器以及LLM流量的代表性子集:100万个真实世界的单轮聊天和推理查询进行了大规模的实证研究。对于每个查询,我们测量了准确率、能量、延迟和功率。我们的分析揭示了三个发现。首先,本地LLM可以准确地回答88.7%的单轮聊天和推理查询,准确率因领域而异。其次,从2023年到2025年,IPW提高了5.3倍,本地查询覆盖率从23.2%上升到71.3%。第三,本地加速器运行相同模型时,IPW至少比云加速器低1.4倍,表明存在很大的优化空间。这些发现表明,本地推理可以有意义地重新分配来自集中式基础设施的需求,IPW是跟踪这种转变的关键指标。我们在此发布我们的IPW分析工具。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理对集中式云基础设施的过度依赖问题。现有方法主要依赖云端服务器进行推理,导致高延迟、高能耗和潜在的隐私问题。此外,云服务提供商难以快速扩展基础设施以满足不断增长的需求,造成了瓶颈。
核心思路:论文的核心思路是利用小型本地LLM和本地加速器,将部分推理任务从云端转移到本地设备上执行。通过评估本地LLM的性能和能效,确定其是否能够有效地分流云端负载,并为未来的优化提供指导。
技术框架:论文构建了一个IPW(Intelligence per Watt)评估框架,用于测量不同模型-加速器组合在本地设备上的推理效率。该框架包括以下主要模块:1) 数据收集模块:收集真实世界的单轮聊天和推理查询作为测试数据集。2) 推理执行模块:在不同的本地加速器上运行不同的本地LLM,对测试数据集进行推理。3) 性能测量模块:测量每个查询的准确率、延迟、能量消耗和功率。4) IPW计算模块:根据准确率和功率计算IPW指标,评估模型-加速器组合的能效。
关键创新:论文的关键创新在于提出了IPW指标,该指标综合考虑了LLM的准确率和能耗,能够更全面地评估本地推理的效率。与传统的性能指标(如延迟或吞吐量)相比,IPW更能反映在功率受限设备上运行LLM的实际可行性。
关键设计:论文的关键设计包括:1) 选择了20多个最先进的本地LLM和8个不同的本地加速器进行评估,覆盖了广泛的模型和硬件组合。2) 使用了100万个真实世界的单轮聊天和推理查询作为测试数据集,保证了评估结果的代表性。3) 详细测量了每个查询的准确率、延迟、能量消耗和功率,为IPW的计算提供了准确的数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,本地LLM可以准确地回答88.7%的单轮聊天和推理查询。从2023年到2025年,IPW提高了5.3倍,本地查询覆盖率从23.2%上升到71.3%。本地加速器运行相同模型时,IPW至少比云加速器低1.4倍,表明本地推理在能效方面具有显著优势,并存在进一步优化的空间。
🎯 应用场景
该研究成果可应用于各种需要低延迟、高能效和保护用户隐私的场景,例如:移动设备上的智能助手、离线翻译、边缘计算设备上的实时分析等。通过将部分LLM推理任务转移到本地设备上,可以降低对云端服务器的依赖,提高系统的响应速度和可靠性,并减少数据传输带来的安全风险。
📄 摘要(原文)
Large language model (LLM) queries are predominantly processed by frontier models in centralized cloud infrastructure. Rapidly growing demand strains this paradigm, and cloud providers struggle to scale infrastructure at pace. Two advances enable us to rethink this paradigm: small LMs (<=20B active parameters) now achieve competitive performance to frontier models on many tasks, and local accelerators (e.g., Apple M4 Max) run these models at interactive latencies. This raises the question: can local inference viably redistribute demand from centralized infrastructure? Answering this requires measuring whether local LMs can accurately answer real-world queries and whether they can do so efficiently enough to be practical on power-constrained devices (i.e., laptops). We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a metric for assessing capability and efficiency of local inference across model-accelerator pairs. We conduct a large-scale empirical study across 20+ state-of-the-art local LMs, 8 accelerators, and a representative subset of LLM traffic: 1M real-world single-turn chat and reasoning queries. For each query, we measure accuracy, energy, latency, and power. Our analysis reveals $3$ findings. First, local LMs can accurately answer 88.7% of single-turn chat and reasoning queries with accuracy varying by domain. Second, from 2023-2025, IPW improved 5.3x and local query coverage rose from 23.2% to 71.3%. Third, local accelerators achieve at least 1.4x lower IPW than cloud accelerators running identical models, revealing significant headroom for optimization. These findings demonstrate that local inference can meaningfully redistribute demand from centralized infrastructure, with IPW serving as the critical metric for tracking this transition. We release our IPW profiling harness here:this https URL.