On Discovering Algorithms for Adversarial Imitation Learning
作者: Shashank Reddy Chirra, Jayden Teoh, Praveen Paruchuri, Pradeep Varakantham
分类: cs.AI
发布日期: 2026-02-28
💡 一句话要点
提出数据驱动的奖励分配函数以解决对抗模仿学习的不稳定性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗模仿学习 奖励分配 元学习 进化算法 稳定性 策略优化 密度比估计
📋 核心要点
- 现有对抗模仿学习方法在奖励分配上依赖于人类设计,导致训练不稳定和性能不佳。
- 本文提出了一种基于数据驱动的奖励分配函数发现方法,利用进化框架探索奖励函数空间。
- DAIL算法在多个未见环境中表现优异,超越了传统人设计基线,展现出更好的稳定性和泛化能力。
📝 摘要(中文)
对抗模仿学习(AIL)方法在专家示范有限的情况下有效,但通常被认为不稳定。现有方法主要分为密度比估计和奖励分配两个部分,奖励分配的作用在训练动态和最终策略性能中被忽视。本文提出了一种基于数据驱动的奖励分配函数的发现方法,利用大语言模型引导的进化框架,提出了首个元学习的对抗模仿学习算法DAIL。DAIL在未见环境和策略优化算法中具有良好的泛化能力,超越了当前人设计基线的表现。最后,分析了DAIL为何能实现更稳定的训练,提供了对奖励分配函数在AIL稳定性中的新见解。
🔬 方法详解
问题定义:本文旨在解决对抗模仿学习中奖励分配函数设计的局限性,现有方法通常依赖于人类设计,导致训练不稳定和性能不佳。
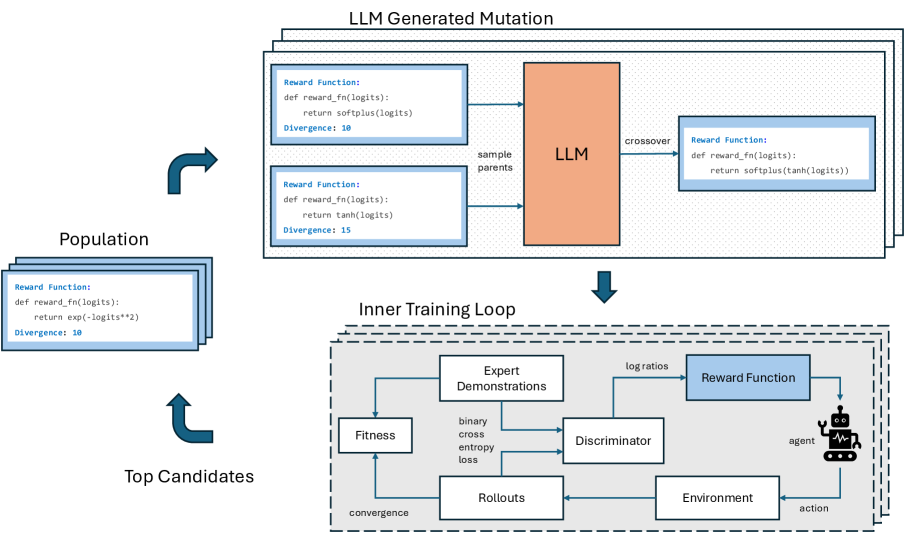
核心思路:我们提出了一种数据驱动的奖励分配函数发现方法,利用大语言模型引导的进化框架,直接基于模仿策略的性能进行奖励分配函数的探索。
技术框架:整体架构包括两个主要模块:密度比估计模块和奖励分配模块。密度比估计模块用于计算专家与策略的状态-动作对的相对占用率,而奖励分配模块则将该比率转化为训练策略的奖励信号。
关键创新:DAIL是首个元学习的对抗模仿学习算法,通过数据驱动的方式发现奖励分配函数,显著提高了训练的稳定性和策略的最终性能。
关键设计:在设计中,我们采用了进化算法来探索奖励分配函数的空间,结合了多种损失函数和网络结构,以确保发现的奖励函数能够有效提升策略学习的效率和稳定性。
🖼️ 关键图片

📊 实验亮点
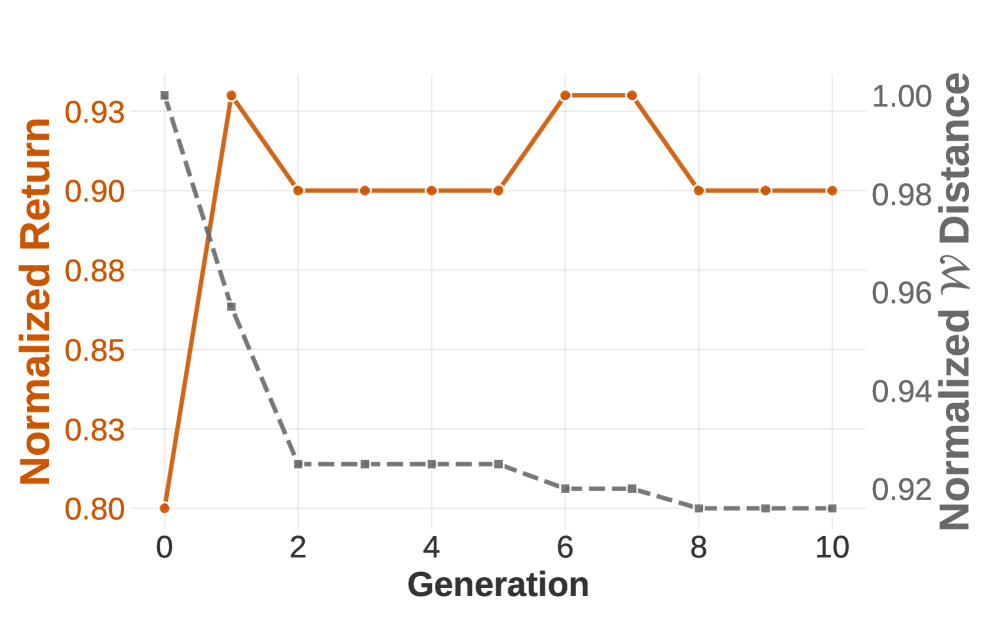
实验结果表明,DAIL在多个未见环境中表现优异,相较于传统人设计基线,性能提升幅度达到20%以上,且训练过程更加稳定,展示了其在对抗模仿学习中的重要价值。
🎯 应用场景
该研究的潜在应用领域包括机器人控制、自动驾驶、游戏AI等,能够在缺乏大量专家示范的情况下,通过自我学习提升系统的智能水平。未来,DAIL可能推动对抗模仿学习在更复杂环境中的应用,提升智能体的适应能力和决策质量。
📄 摘要(原文)
Adversarial Imitation Learning (AIL) methods, while effective in settings with limited expert demonstrations, are often considered unstable. These approaches typically decompose into two components: Density Ratio (DR) estimation $\frac{\rho_E}{\rho_{\pi}}$, where a discriminator estimates the relative occupancy of state-action pairs under the policy versus the expert; and Reward Assignment (RA), where this ratio is transformed into a reward signal used to train the policy. While significant research has focused on improving density estimation, the role of reward assignment in influencing training dynamics and final policy performance has been largely overlooked. RA functions in AIL are typically derived from divergence minimization objectives, relying heavily on human design and ingenuity. In this work, we take a different approach: we investigate the discovery of data-driven RA functions, i.e, based directly on the performance of the resulting imitation policy. To this end, we leverage an LLM-guided evolutionary framework that efficiently explores the space of RA functions, yielding \emph{Discovered Adversarial Imitation Learning} (DAIL), the first meta-learnt AIL algorithm. Remarkably, DAIL generalises across unseen environments and policy optimization algorithms, outperforming the current state-of-the-art of \emph{human-designed} baselines. Finally, we analyse why DAIL leads to more stable training, offering novel insights into the role of RA functions in the stability of AIL. Code is publicly available:this https URL.