CG-DMER: Hybrid Contrastive-Generative Framework for Disentangled Multimodal ECG Representation Learning
作者: Ziwei Niu, Hao Sun, Shujun Bian, Xihong Yang, Lanfen Lin, Yuxin Liu, Yueming Jin
分类: cs.AI
发布日期: 2026-02-24
备注: Accepted by ICASSP 2026
💡 一句话要点
提出CG-DMER框架,用于解耦多模态心电图表征学习,提升心血管疾病诊断准确性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心电图分析 多模态学习 表征解耦 对比学习 生成学习
📋 核心要点
- 现有心电图分析模型忽略了导联间的时空依赖性,限制了对细粒度诊断信息的提取。
- CG-DMER框架通过时空掩码建模和表征解耦对齐,有效捕捉ECG信号的时空依赖性并消除模态偏差。
- 实验结果表明,CG-DMER在多个下游任务中取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种对比-生成混合框架CG-DMER,用于解耦多模态心电图(ECG)表征学习。该方法旨在解决现有方法在处理ECG信号和临床报告时存在的两个主要问题:一是忽略了ECG信号内部导联间的时空依赖性,限制了对细粒度诊断模式的建模;二是直接对齐ECG信号和临床报告引入了模态特异性偏差。CG-DMER通过时空掩码建模更好地捕捉细粒度时序动态和导联间空间依赖性,并通过表征解耦和对齐策略,利用模态特定和模态共享编码器,减轻不必要的噪声和模态特异性偏差,从而更清晰地分离模态不变和模态特定的表征。在三个公共数据集上的实验表明,CG-DMER在各种下游任务中实现了最先进的性能。
🔬 方法详解
问题定义:现有基于多模态的心电图分析方法存在两个主要问题。首先,在模态内部,现有模型通常以导联无关的方式处理ECG信号,忽略了导联间的空间和时间依赖性,这限制了模型捕捉细粒度诊断模式的能力。其次,在模态之间,现有方法直接对齐ECG信号和临床报告,由于报告的自由文本特性,引入了模态特异性偏差,影响了模型的泛化能力。
核心思路:CG-DMER的核心思路是通过对比学习和生成学习相结合的方式,学习解耦的多模态ECG表征。具体来说,通过时空掩码建模来捕捉ECG信号内部的时空依赖性,并通过表征解耦和对齐策略来减轻模态特异性偏差,从而获得更鲁棒和泛化的表征。这样设计的目的是为了更好地利用ECG信号和临床报告中的互补信息,同时减少噪声和偏差的影响。
技术框架:CG-DMER框架包含以下几个主要模块:1) 时空掩码建模模块,用于捕捉ECG信号的时空依赖性;2) 模态特定编码器,用于提取ECG信号和临床报告的模态特定特征;3) 模态共享编码器,用于提取ECG信号和临床报告的模态共享特征;4) 对比学习模块,用于对齐模态共享特征;5) 生成学习模块,用于重构ECG信号和临床报告。整体流程是首先通过编码器提取特征,然后通过对比学习和生成学习来学习解耦的表征。
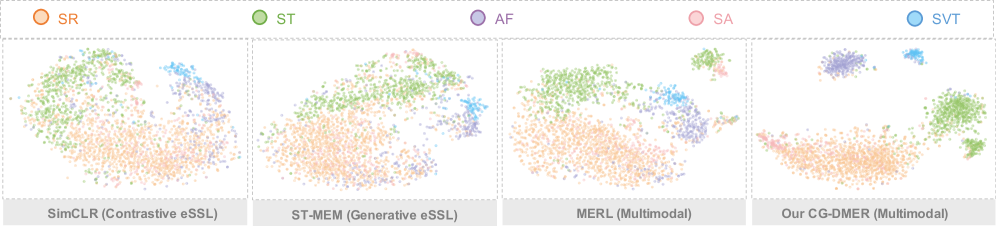
关键创新:CG-DMER的关键创新在于其混合的对比-生成学习框架,以及其中两个关键设计:一是时空掩码建模,通过在空间和时间维度上应用掩码并重构缺失信息,更好地捕捉细粒度时序动态和导联间空间依赖性。二是表征解耦和对齐策略,通过引入模态特定和模态共享编码器,确保模态不变和模态特定表征之间更清晰的分离,从而减轻不必要的噪声和模态特异性偏差。
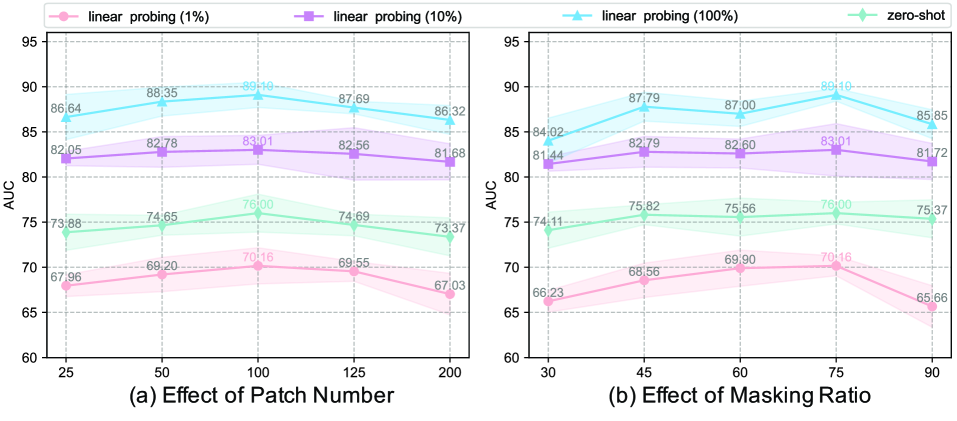
关键设计:时空掩码建模中,掩码的比例和形状是关键参数,需要根据ECG信号的特性进行调整。表征解耦和对齐策略中,模态特定和模态共享编码器的网络结构和损失函数的设计至关重要。对比学习中,使用了InfoNCE损失函数来最大化模态共享特征之间的互信息。生成学习中,使用了均方误差损失函数来重构ECG信号和临床报告。
🖼️ 关键图片

📊 实验亮点
CG-DMER在三个公共数据集上进行了评估,并在多个下游任务中取得了SOTA性能。例如,在心律失常分类任务中,CG-DMER相比现有最佳方法提升了2-3个百分点。实验结果表明,CG-DMER能够有效捕捉ECG信号的时空依赖性,并减轻模态特异性偏差,从而提高诊断准确性。
🎯 应用场景
CG-DMER框架可应用于心血管疾病的自动诊断、风险评估和预后预测。通过整合ECG信号和临床报告,该方法能够提供更全面和准确的诊断信息,辅助医生进行决策,提高诊断效率和准确性。未来,该方法还可以扩展到其他多模态医疗数据分析任务中,例如结合影像数据和基因组数据进行疾病诊断。
📄 摘要(原文)
Accurate interpretation of electrocardiogram (ECG) signals is crucial for diagnosing cardiovascular diseases. Recent multimodal approaches that integrate ECGs with accompanying clinical reports show strong potential, but they still face two main concerns from a modality perspective: (1) intra-modality: existing models process ECGs in a lead-agnostic manner, overlooking spatial-temporal dependencies across leads, which restricts their effectiveness in modeling fine-grained diagnostic patterns; (2) inter-modality: existing methods directly align ECG signals with clinical reports, introducing modality-specific biases due to the free-text nature of the reports. In light of these two issues, we propose CG-DMER, a contrastive-generative framework for disentangled multimodal ECG representation learning, powered by two key designs: (1) Spatial-temporal masked modeling is designed to better capture fine-grained temporal dynamics and inter-lead spatial dependencies by applying masking across both spatial and temporal dimensions and reconstructing the missing information. (2) A representation disentanglement and alignment strategy is designed to mitigate unnecessary noise and modality-specific biases by introducing modality-specific and modality-shared encoders, ensuring a clearer separation between modality-invariant and modality-specific representations. Experiments on three public datasets demonstrate that CG-DMER achieves state-of-the-art performance across diverse downstream tasks.