A Benchmark for Deep Information Synthesis
作者: Debjit Paul, Daniel Murphy, Milan Gritta, Ronald Cardenas, Victor Prokhorov, Lena Sophia Bolliger, Aysim Toker, Roy Miles, Andreea-Maria Oncescu, Jasivan Alex Sivakumar, Philipp Borchert, Ismail Elezi, Meiru Zhang, Ka Yiu Lee, Guchun Zhang, Jun Wang, Gerasimos Lampouras
分类: cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2026-02-24
备注: Accepted at ICLR 2026
💡 一句话要点
提出DEEPSYNTH基准,评估LLM智能体在复杂信息合成与推理任务中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息合成 大型语言模型 智能体 基准测试 推理 多源信息 真实世界任务
📋 核心要点
- 现有评估基准不足以评估LLM智能体在真实世界复杂任务中信息合成和推理的能力。
- DEEPSYNTH基准通过模拟真实场景,要求智能体从多源信息中提取、整合并推理出洞见。
- 实验结果表明,现有LLM智能体在DEEPSYNTH上表现不佳,突显了其在信息合成和推理方面的局限性。
📝 摘要(中文)
本文提出了DEEPSYNTH,一个用于评估基于大型语言模型(LLM)的智能体在解决复杂任务时信息合成能力的基准。这些任务需要智能体进行网络浏览、代码执行和数据分析等工具使用。DEEPSYNTH旨在弥补现有基准在评估智能体处理真实世界问题方面的不足,这些问题需要从多个来源收集信息、综合信息并进行结构化推理以产生洞见。DEEPSYNTH包含120个任务,涵盖7个领域和数据源,涉及67个国家。该基准通过多阶段数据收集流程构建,要求标注者收集官方数据源、创建假设、执行手动分析并设计具有可验证答案的任务。在DEEPSYNTH上的评估结果表明,现有最先进的LLM和深度研究智能体在F1 score上分别达到最高8.97和17.5(使用LLM-judge指标),突显了该基准的难度。分析表明,当前智能体在处理幻觉和大型信息空间推理方面存在困难,这使得DEEPSYNTH成为指导未来研究的关键基准。
🔬 方法详解
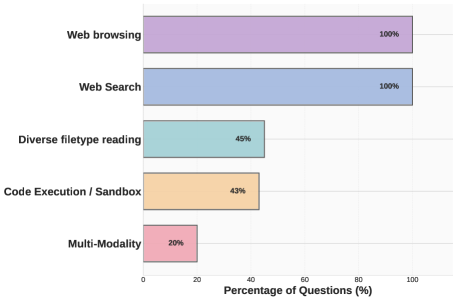
问题定义:现有的大型语言模型(LLM)智能体在解决需要工具使用(如网络浏览、代码执行和数据分析)的复杂任务中表现出潜力。然而,现有的评估基准未能充分评估它们在真实世界任务中综合信息和推理的能力。这些任务需要从多个来源收集信息,进行信息合成,并进行结构化推理以产生洞见。现有基准主要侧重于事实检索,而忽略了更高级的信息处理能力。
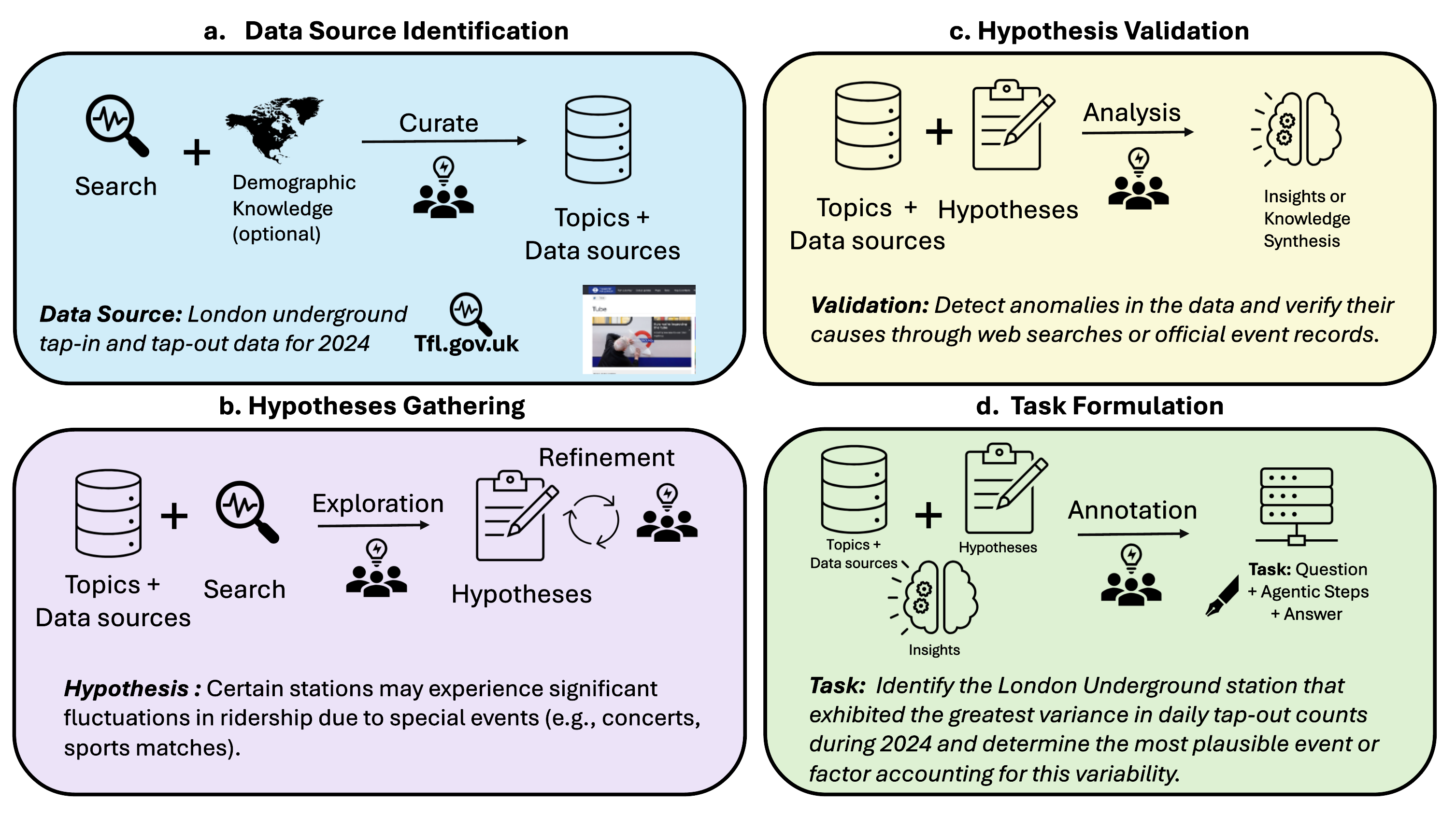
核心思路:DEEPSYNTH的核心思路是创建一个更具挑战性和现实性的基准,以评估LLM智能体在信息合成和推理方面的能力。它通过设计需要从多个来源收集信息、综合信息并进行结构化推理的任务来实现这一点。这种设计旨在模拟真实世界中复杂的问题解决场景,从而更全面地评估智能体的能力。
技术框架:DEEPSYNTH的构建采用多阶段数据收集流程。首先,标注者需要收集官方数据源,这些数据源涵盖多个领域和国家。然后,标注者基于这些数据源创建假设,并进行手动分析以验证这些假设。最后,标注者设计具有可验证答案的任务,这些任务需要智能体综合来自多个来源的信息并进行推理。整个流程确保了任务的真实性、复杂性和可评估性。
关键创新:DEEPSYNTH的关键创新在于其任务设计的复杂性和真实性。与现有基准相比,DEEPSYNTH的任务需要智能体进行更高级的信息处理,包括信息收集、信息合成和结构化推理。此外,DEEPSYNTH还涵盖了更广泛的领域和数据源,使其更具代表性和通用性。
关键设计:DEEPSYNTH包含120个任务,涵盖7个领域和数据源,涉及67个国家。任务设计注重可验证性,每个任务都有明确的答案。评估指标包括F1 score和LLM-judge指标,用于衡量智能体在信息合成和推理方面的准确性和质量。没有特别提及关键的参数设置、损失函数、网络结构等技术细节,可能因为该论文侧重于基准数据集的构建而非特定模型的训练。
🖼️ 关键图片

📊 实验亮点
在DEEPSYNTH基准上,最先进的LLM和深度研究智能体表现不佳,F1 score最高仅为8.97和17.5(使用LLM-judge指标)。这表明现有智能体在处理幻觉和大型信息空间推理方面存在困难,突显了DEEPSYNTH基准的挑战性和价值。实验结果表明,该基准能够有效区分不同智能体在信息合成和推理方面的能力。
🎯 应用场景
DEEPSYNTH基准的潜在应用领域包括智能助手、决策支持系统、自动化研究和数据分析等。通过提高LLM智能体的信息合成和推理能力,可以使其在这些领域中发挥更大的作用,例如辅助决策者分析复杂数据、帮助研究人员进行文献综述和假设验证等。该基准的未来影响在于推动LLM智能体在解决真实世界复杂问题方面的能力。
📄 摘要(原文)
Large language model (LLM)-based agents are increasingly used to solve complex tasks involving tool use, such as web browsing, code execution, and data analysis. However, current evaluation benchmarks do not adequately assess their ability to solve real-world tasks that require synthesizing information from multiple sources and inferring insights beyond simple fact retrieval. To address this, we introduce DEEPSYNTH, a novel benchmark designed to evaluate agents on realistic, time-consuming problems that combine information gathering, synthesis, and structured reasoning to produce insights. DEEPSYNTH contains 120 tasks collected across 7 domains and data sources covering 67 countries. DEEPSYNTH is constructed using a multi-stage data collection pipeline that requires annotators to collect official data sources, create hypotheses, perform manual analysis, and design tasks with verifiable answers. When evaluated on DEEPSYNTH, 11 state-of-the-art LLMs and deep research agents achieve a maximum F1 score of 8.97 and 17.5 on the LLM-judge metric, underscoring the difficulty of the benchmark. Our analysis reveals that current agents struggle with hallucinations and reasoning over large information spaces, highlighting DEEPSYNTH as a crucial benchmark for guiding future research.