LogicGraph : Benchmarking Multi-Path Logical Reasoning via Neuro-Symbolic Generation and Verification
作者: Yanrui Wu, Lingling Zhang, Xinyu Zhang, Jiayu Chang, Pengyu Li, Xu Jiang, Jingtao Hu, Jun Liu
分类: cs.AI
发布日期: 2026-02-24
备注: 24 pages, 17 figures
🔗 代码/项目: GITHUB
💡 一句话要点
LogicGraph:提出神经符号生成与验证框架,用于评估多路径逻辑推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逻辑推理 多路径推理 神经符号推理 基准数据集 大语言模型评估
📋 核心要点
- 现有大语言模型在逻辑推理评估中,侧重于寻找单一正确的证明路径,忽略了现实世界中多路径推理的普遍性。
- LogicGraph通过神经符号框架,结合后向逻辑生成和语义实例化,构建了包含多条有效推理路径的基准数据集。
- 实验表明,现有模型倾向于过早地选择单一路径,无法有效探索其他可能性,且随着推理深度增加,覆盖率差距显著增大。
📝 摘要(中文)
大型语言模型(LLMs)的评估主要侧重于收敛性逻辑推理,即通过产生单一正确的证明来定义成功。然而,许多现实世界的推理问题允许多种有效的推导,要求模型探索不同的逻辑路径,而不是只专注于一条路径。为了解决这个局限性,我们引入了LogicGraph,这是第一个旨在系统评估多路径逻辑推理的基准,它通过神经符号框架构建,该框架利用了后向逻辑生成和语义实例化。该流程产生由高深度多路径推理和内在逻辑干扰形式化的、经过求解器验证的推理问题,其中每个实例都与一组详尽的最小证明相关联。我们进一步提出了一个无参考的评估框架,以严格评估模型在收敛和发散状态下的性能。对最先进的语言模型的实验表明,一个普遍的局限性是:模型倾向于过早地专注于单一路径,而未能探索替代方案,并且覆盖率差距随着推理深度的增加而显著增长。LogicGraph揭示了这种发散差距,并提供了可操作的见解,以推动未来的改进。我们的代码和数据将在https://github.com/kkkkarry/LogicGraph上发布。
🔬 方法详解
问题定义:现有的大语言模型评估侧重于收敛性逻辑推理,即模型只需要找到一个正确的证明路径即可。然而,现实世界中的许多逻辑推理问题往往存在多条不同的有效路径,模型需要具备探索和利用这些不同路径的能力。现有评估方法无法有效衡量模型在多路径逻辑推理方面的能力,也无法识别模型在探索不同推理路径时的不足。
核心思路:LogicGraph的核心思路是通过构建一个包含多条有效推理路径的基准数据集,来系统地评估模型在多路径逻辑推理方面的能力。该数据集的设计目标是模拟现实世界中复杂逻辑推理场景,其中每个问题都存在多个可能的解决方案,并且模型需要探索不同的推理路径才能找到这些解决方案。
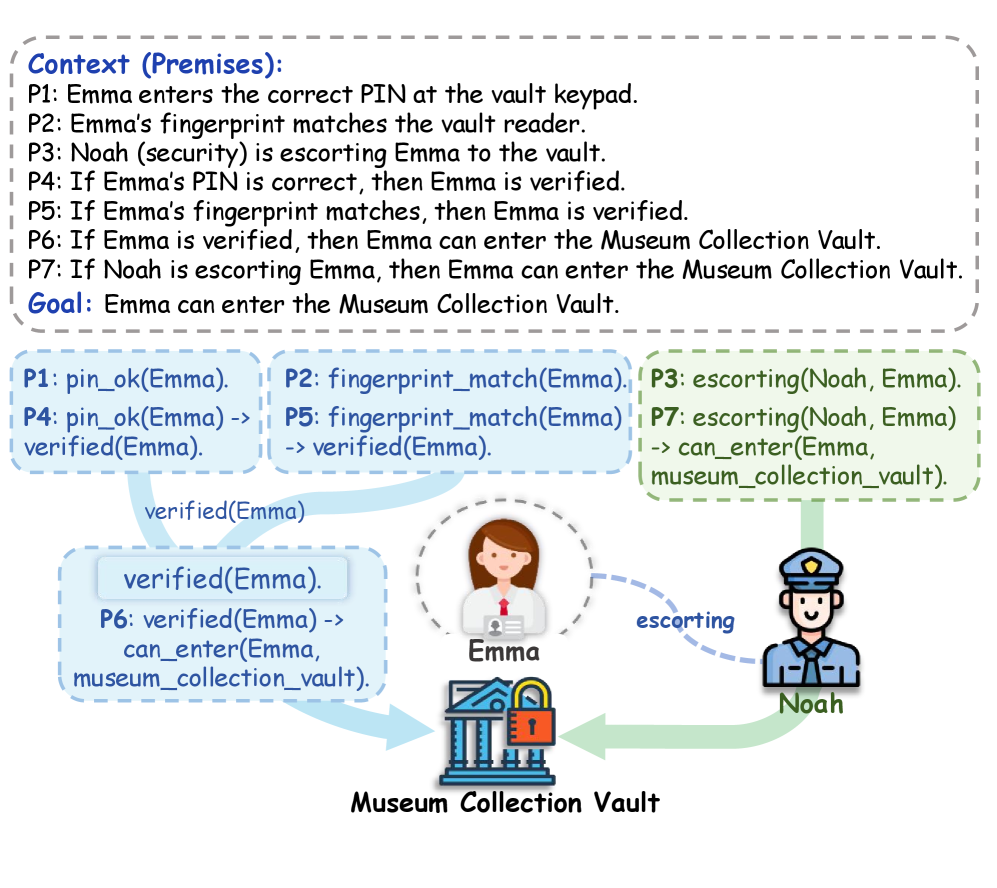
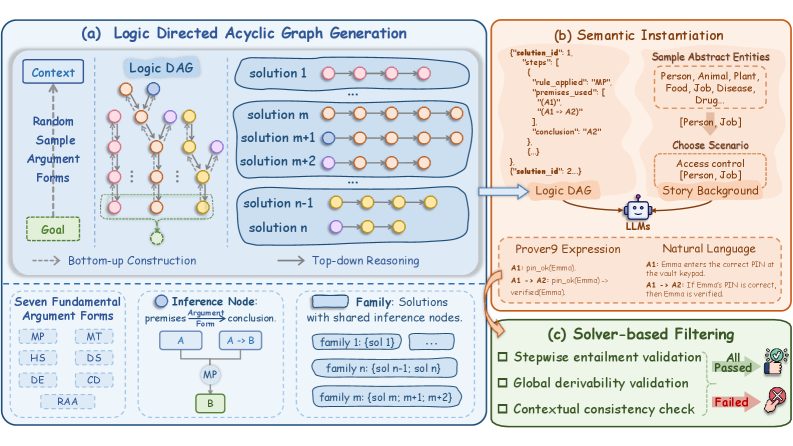
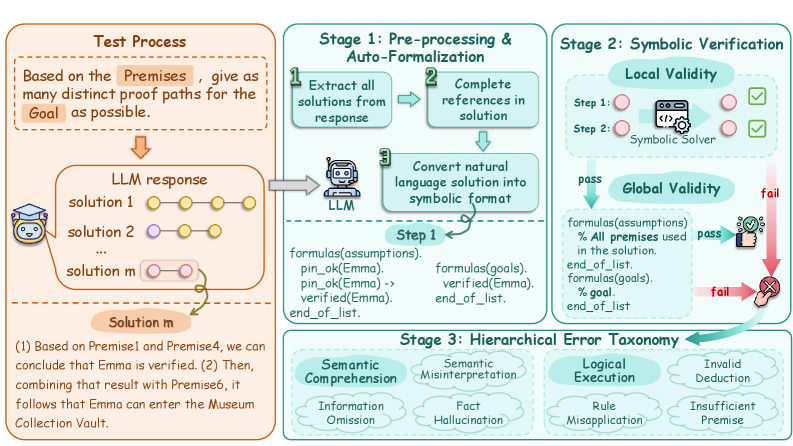
技术框架:LogicGraph的构建主要包含以下几个阶段:1) 后向逻辑生成:从目标结论出发,反向生成一系列逻辑规则和事实,构建一个逻辑图。2) 语义实例化:将抽象的逻辑规则和事实实例化为具体的语义内容,生成具体的推理问题。3) 求解器验证:使用逻辑求解器验证生成的推理问题是否有效,并确保每个问题都存在多个有效的解决方案。4) 最小证明集生成:为每个推理问题生成一个详尽的最小证明集,用于评估模型的推理覆盖率。
关键创新:LogicGraph的关键创新在于其神经符号构建框架,该框架结合了神经生成模型和符号逻辑推理,能够自动生成包含多条有效推理路径的复杂逻辑推理问题。与以往的人工构建数据集相比,LogicGraph能够更高效、更系统地生成大规模、多样化的推理问题。此外,该框架还能够确保生成的问题具有逻辑一致性和可解性。
关键设计:在后向逻辑生成阶段,使用了基于Transformer的序列生成模型,该模型以目标结论为输入,生成一系列逻辑规则和事实。在语义实例化阶段,使用了预训练语言模型来将抽象的逻辑规则和事实映射到具体的语义内容。在求解器验证阶段,使用了SMT求解器来验证生成的推理问题是否有效。此外,还设计了一种无参考的评估框架,用于评估模型在收敛和发散状态下的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有的大语言模型在LogicGraph数据集上的表现远低于人类水平,尤其是在探索多条推理路径方面存在明显不足。模型倾向于过早地选择单一路径,无法有效探索其他可能性,并且随着推理深度增加,覆盖率差距显著增大。例如,在深度为3的推理问题上,模型的平均覆盖率仅为20%左右,而人类可以达到80%以上。
🎯 应用场景
LogicGraph的研究成果可应用于提升大语言模型在复杂逻辑推理场景下的表现,例如智能问答、知识图谱推理、规划与决策等领域。通过使用LogicGraph进行训练和评估,可以帮助模型更好地理解和利用多条推理路径,从而提高解决实际问题的能力。此外,该研究还可以促进神经符号推理领域的发展,探索更有效的神经符号结合方法。
📄 摘要(原文)
Evaluations of large language models (LLMs) primarily emphasize convergent logical reasoning, where success is defined by producing a single correct proof. However, many real-world reasoning problems admit multiple valid derivations, requiring models to explore diverse logical paths rather than committing to one route. To address this limitation, we introduce LogicGraph, the first benchmark aimed to systematically evaluate multi-path logical reasoning, constructed via a neuro-symbolic framework that leverages backward logic generation and semantic instantiation. This pipeline yields solver-verified reasoning problems formalized by high-depth multi-path reasoning and inherent logical distractions, where each instance is associated with an exhaustive set of minimal proofs. We further propose a reference-free evaluation framework to rigorously assess model performance in both convergent and divergent regimes. Experiments on state-of-the-art language models reveal a common limitation: models tend to commit early to a single route and fail to explore alternatives, and the coverage gap grows substantially with reasoning depth. LogicGraph exposes this divergence gap and provides actionable insights to motivate future improvements. Our code and data will be released at https://github.com/kkkkarry/LogicGraph.