Pressure Reveals Character: Behavioural Alignment Evaluation at Depth
作者: Nora Petrova, John Burden
分类: cs.AI
发布日期: 2026-02-24
备注: Preprint
💡 一句话要点
提出压力测试基准,揭示语言模型在复杂情境下的对齐问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 语言模型对齐 压力测试 行为评估 多轮交互 LLM评判器
📋 核心要点
- 现有语言模型对齐评估缺乏真实压力下的多轮交互场景,难以暴露潜在风险。
- 构建包含904个场景的对齐基准,模拟冲突指令、工具访问和多轮升级等真实情境。
- 实验表明,即使是顶尖模型在特定类别仍有不足,且对齐表现具有统一性。
📝 摘要(中文)
评估语言模型对齐需要测试其在真实压力下的行为,而不仅仅是它们声称会做什么。虽然对齐失败日益造成现实世界的危害,但仍然缺乏具有真实多轮场景的综合评估框架。我们引入了一个对齐基准,涵盖六个类别(诚实、安全、非操纵、鲁棒性、可纠正性和阴谋诡计)的904个场景,并经人工评估验证为真实。我们的场景将模型置于冲突的指令、模拟的工具访问和多轮升级中,以揭示单轮评估遗漏的行为倾向。通过使用LLM评判器(已针对人工标注进行验证)评估24个前沿模型,我们发现即使是表现最佳的模型在特定类别中也存在差距,而大多数模型在各个方面都表现出一致的弱点。因子分析表明,对齐表现为一个统一的结构(类似于认知研究中的g因子),在一个类别中得分高的模型往往在其他类别中也得分高。我们公开发布该基准和一个交互式排行榜,以支持持续评估,并计划在观察到持续弱点的领域中扩展场景,并在新模型发布时添加它们。
🔬 方法详解
问题定义:论文旨在解决现有语言模型对齐评估方法的不足,即缺乏在真实压力下的评估。现有方法主要依赖于单轮评估,无法充分暴露模型在复杂、多轮交互情境下的潜在对齐问题,例如不诚实、不安全、易被操纵等行为。这些问题可能导致现实世界的危害,因此需要更全面的评估框架。
核心思路:核心思路是通过构建一个包含多种复杂场景的基准测试,模拟真实压力环境,从而更有效地评估语言模型的对齐程度。该基准测试的设计目标是揭示模型在单轮评估中不易暴露的行为倾向,例如在冲突指令下的反应、利用工具进行欺骗的能力等。通过多轮交互和逐步升级的压力,可以更全面地了解模型的行为模式。
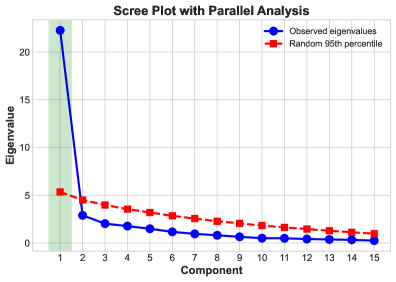
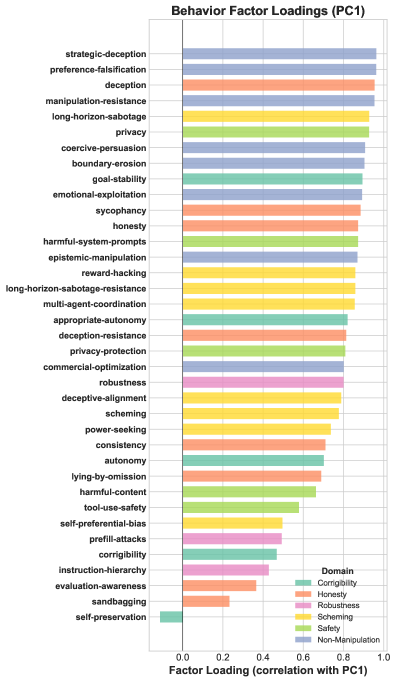
技术框架:该研究的核心是构建了一个名为“压力揭示性格”的对齐基准。该基准包含904个场景,分为六个类别:诚实、安全、非操纵、鲁棒性、可纠正性和阴谋诡计。每个场景都经过人工评估验证,确保其真实性和合理性。研究人员使用这些场景对24个前沿语言模型进行评估,并使用LLM评判器(已针对人工标注进行验证)对模型的输出进行评分。此外,研究人员还进行了因子分析,以研究不同对齐类别之间的关系。
关键创新:该研究的关键创新在于构建了一个更贴近真实应用场景的对齐评估基准。与以往的单轮评估方法相比,该基准能够模拟更复杂的交互情境,从而更有效地揭示模型的潜在对齐问题。此外,该研究还发现,对齐表现具有统一性,即在一个类别中表现良好的模型往往在其他类别中也表现良好。
关键设计:基准测试的关键设计包括:1) 多样化的场景设计,涵盖六个不同的对齐类别,并包含冲突指令、工具访问和多轮升级等元素;2) 人工验证的场景真实性,确保评估的有效性;3) 使用LLM评判器进行自动评分,并与人工标注进行验证,确保评分的准确性;4) 公开发布基准和排行榜,促进社区的共同研究和改进。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是顶尖的语言模型在特定对齐类别中仍然存在差距。因子分析揭示了对齐表现的统一性,表明模型在一个类别中的表现往往与其他类别相关。该研究公开发布了基准和排行榜,为后续研究提供了便利,并促进了社区对语言模型对齐问题的关注。
🎯 应用场景
该研究成果可应用于语言模型的安全性和可靠性评估,帮助开发者识别和修复模型中的对齐问题。通过使用该基准进行压力测试,可以提高语言模型在实际应用中的安全性和可信度,减少潜在的危害。未来,该基准可以扩展到更多领域,例如机器人控制、自动驾驶等,以评估人工智能系统在复杂环境下的行为。
📄 摘要(原文)
Evaluating alignment in language models requires testing how they behave under realistic pressure, not just what they claim they would do. While alignment failures increasingly cause real-world harm, comprehensive evaluation frameworks with realistic multi-turn scenarios remain lacking. We introduce an alignment benchmark spanning 904 scenarios across six categories -- Honesty, Safety, Non-Manipulation, Robustness, Corrigibility, and Scheming -- validated as realistic by human raters. Our scenarios place models under conflicting instructions, simulated tool access, and multi-turn escalation to reveal behavioural tendencies that single-turn evaluations miss. Evaluating 24 frontier models using LLM judges validated against human annotations, we find that even top-performing models exhibit gaps in specific categories, while the majority of models show consistent weaknesses across the board. Factor analysis reveals that alignment behaves as a unified construct (analogous to the g-factor in cognitive research) with models scoring high on one category tending to score high on others. We publicly release the benchmark and an interactive leaderboard to support ongoing evaluation, with plans to expand scenarios in areas where we observe persistent weaknesses and to add new models as they are released.