PRECTR-V2:Unified Relevance-CTR Framework with Cross-User Preference Mining, Exposure Bias Correction, and LLM-Distilled Encoder Optimization
作者: Shuzhi Cao, Rong Chen, Ailong He, Shuguang Han, Jufeng Chen
分类: cs.IR, cs.AI
发布日期: 2026-02-24
备注: arXiv admin note: text overlap with arXiv:2503.18395
💡 一句话要点
PRECTR-V2:融合用户偏好挖掘、偏差校正和LLM蒸馏的统一相关性-CTR框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 点击率预测 相关性匹配 用户偏好挖掘 曝光偏差校正 知识蒸馏 冷启动 Transformer
📋 核心要点
- 现有方法难以对低活跃用户进行个性化相关性建模,因为他们的搜索行为数据稀疏。
- PRECTR-V2通过挖掘全局相关性偏好,并结合嵌入噪声注入和相关性标签重构来解决上述问题。
- PRECTR-V2通过知识蒸馏预训练轻量级Transformer编码器,提升了模型性能并超越了传统Emb+MLP范式。
📝 摘要(中文)
在搜索系统中,有效协调搜索相关性匹配和点击率(CTR)预测这两个核心目标,对于发现用户兴趣和提高平台收入至关重要。我们之前的工作PRECTR提出了一个统一的框架来整合这两个子任务,从而消除它们的不一致性并实现互利。然而,我们之前的工作仍然面临三个主要挑战。首先,低活跃用户和新用户的搜索行为数据有限,难以实现有效的个性化相关性偏好建模。其次,排序模型的训练数据主要来自高相关性曝光,这导致与粗排中更广泛的候选空间存在分布不匹配,从而产生泛化偏差。第三,由于延迟约束,原始模型采用带有冻结BERT编码器的Emb+MLP架构,这阻碍了联合优化,并在表示学习和CTR微调之间产生错位。为了解决这些问题,我们进一步加强了我们的方法,并提出了PRECTR-V2。具体来说,我们通过挖掘特定查询下的全局相关性偏好来缓解低活跃用户的稀疏行为问题,这有助于冷启动场景下的有效个性化相关性建模。随后,我们通过嵌入噪声注入和相关性标签重构来构建困难负样本,并通过pairwise loss优化它们相对于正样本的相对排序,从而纠正曝光偏差。最后,我们通过LLM的知识蒸馏和文本相关性分类任务的SFT预训练一个轻量级的基于transformer的编码器。这个编码器取代了冻结的BERT模块,使其更好地适应CTR微调,并超越了传统的Emb+MLP范式。
🔬 方法详解
问题定义:论文旨在解决搜索系统中相关性匹配和点击率(CTR)预测两个子任务不一致,以及低活跃用户个性化建模困难、曝光偏差和表示学习与CTR微调错位等问题。现有方法在处理低活跃用户时,由于数据稀疏,无法有效进行个性化相关性建模。此外,训练数据中的曝光偏差导致模型泛化能力下降。最后,传统Emb+MLP架构的表示学习与CTR微调存在错位,限制了模型性能。
核心思路:PRECTR-V2的核心思路是通过挖掘全局相关性偏好来缓解低活跃用户的数据稀疏问题,利用噪声注入和标签重构来纠正曝光偏差,并通过知识蒸馏预训练轻量级Transformer编码器来提升模型性能并实现表示学习与CTR微调的对齐。
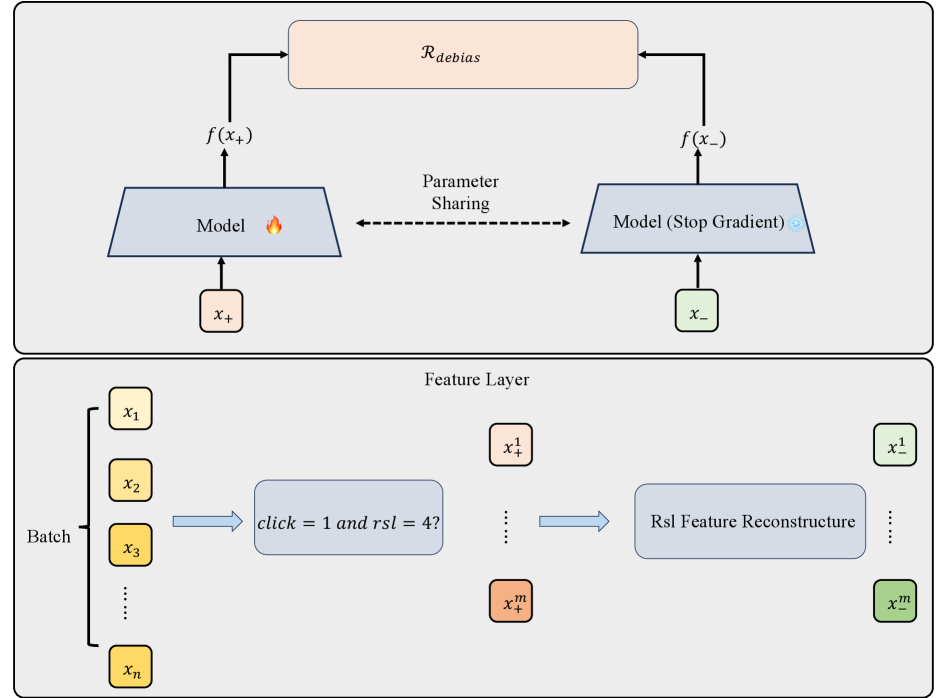
技术框架:PRECTR-V2的整体框架包括以下几个主要模块:1) 全局相关性偏好挖掘模块,用于挖掘特定查询下的全局相关性偏好;2) 曝光偏差校正模块,通过嵌入噪声注入和相关性标签重构来构建困难负样本,并使用pairwise loss进行优化;3) LLM蒸馏的轻量级Transformer编码器,用于替换冻结的BERT模块,实现更好的CTR微调适应性。
关键创新:PRECTR-V2的关键创新在于:1) 提出了全局相关性偏好挖掘方法,有效缓解了低活跃用户的数据稀疏问题;2) 引入了嵌入噪声注入和相关性标签重构,有效纠正了曝光偏差;3) 使用LLM蒸馏预训练轻量级Transformer编码器,提升了模型性能并实现了表示学习与CTR微调的对齐。
关键设计:在全局相关性偏好挖掘模块中,具体方法未知。在曝光偏差校正模块中,通过嵌入噪声注入生成困难负样本,并使用pairwise loss(如BPR loss)优化正负样本对的排序。轻量级Transformer编码器通过LLM知识蒸馏和SFT进行预训练,具体蒸馏方法和SFT数据集细节未知。
🖼️ 关键图片

📊 实验亮点
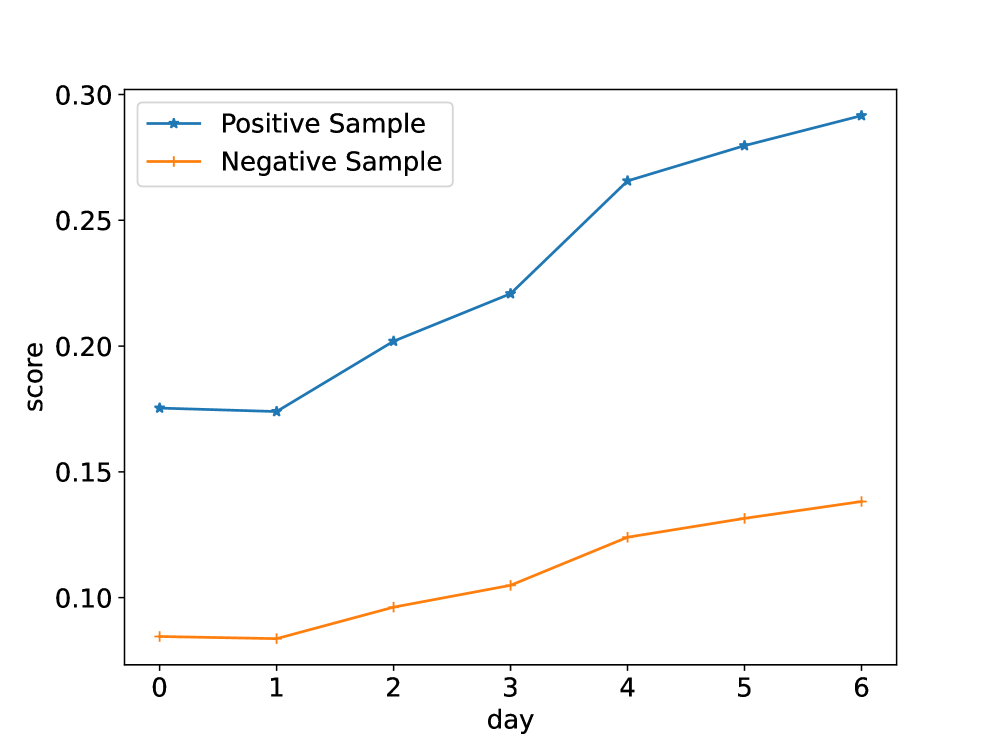
论文通过实验验证了PRECTR-V2的有效性,但具体的性能数据、对比基线和提升幅度未知。实验结果表明,PRECTR-V2能够有效缓解低活跃用户的数据稀疏问题,纠正曝光偏差,并提升模型性能。通过LLM蒸馏预训练的轻量级Transformer编码器,显著优于传统的Emb+MLP架构。
🎯 应用场景
PRECTR-V2可应用于各种搜索和推荐系统,尤其是在用户行为数据稀疏的冷启动场景下。该方法能够提升低活跃用户的个性化推荐效果,纠正曝光偏差,提高模型的泛化能力,从而提升用户体验和平台收益。未来,该研究可以扩展到其他信息检索任务,例如问答系统和对话系统。
📄 摘要(原文)
In search systems, effectively coordinating the two core objectives of search relevance matching and click-through rate (CTR) prediction is crucial for discovering users' interests and enhancing platform revenue. In our prior work PRECTR, we proposed a unified framework to integrate these two subtasks,thereby eliminating their inconsistency and leading to mutual benefit.However, our previous work still faces three main challenges. First, low-active users and new users have limited search behavioral data, making it difficult to achieve effective personalized relevance preference modeling. Second, training data for ranking models predominantly come from high-relevance exposures, creating a distribution mismatch with the broader candidate space in coarse-ranking, leading to generalization bias. Third, due to the latency constraint, the original model employs an Emb+MLP architecture with a frozen BERT encoder, which prevents joint optimization and creates misalignment between representation learning and CTR fine-tuning. To solve these issues, we further reinforce our method and propose PRECTR-V2. Specifically, we mitigate the low-activity users' sparse behavior problem by mining global relevance preferences under the specific query, which facilitates effective personalized relevance modeling for cold-start scenarios. Subsequently, we construct hard negative samples through embedding noise injection and relevance label reconstruction, and optimize their relative ranking against positive samples via pairwise loss, thereby correcting exposure bias. Finally, we pretrain a lightweight transformer-based encoder via knowledge distillation from LLM and SFT on the text relevance classification task. This encoder replaces the frozen BERT module, enabling better adaptation to CTR fine-tuning and advancing beyond the traditional Emb+MLP paradigm.