OptiLeak: Efficient Prompt Reconstruction via Reinforcement Learning in Multi-tenant LLM Services
作者: Longxiang Wang, Xiang Zheng, Xuhao Zhang, Yao Zhang, Ye Wu, Cong Wang
分类: cs.CR, cs.AI
发布日期: 2026-02-24
💡 一句话要点
OptiLeak:利用强化学习高效重建多租户LLM服务中的泄露提示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 提示泄露 侧信道攻击 强化学习 直接偏好优化 多租户LLM 缓存攻击 隐私安全
📋 核心要点
- 多租户LLM服务中的共享缓存易受侧信道攻击,导致提示泄露,现有方法攻击成本高昂,低估了隐私风险。
- OptiLeak利用强化学习,通过两阶段微调优化提示重建效率,自动识别领域特定的“硬token”用于偏好对齐。
- 实验表明,OptiLeak在医疗和金融领域实现了显著的性能提升,每个token平均请求次数降低高达12.48倍。
📝 摘要(中文)
多租户LLM服务框架广泛采用共享的Key-Value缓存来提高效率。然而,这会产生侧信道漏洞,从而导致提示泄露攻击。先前的研究已经确定了这些攻击面,但侧重于扩展攻击向量,而不是优化攻击性能,报告的攻击成本过高,低估了真正的隐私风险。我们提出了OptiLeak,一个通过强化学习增强的框架,通过两阶段微调最大限度地提高提示重建效率。我们的关键见解是,领域特定的“硬token”(难以预测但携带敏感信息的术语)可以通过似然排序自动识别,并用于构建直接偏好优化(Direct Preference Optimization)的偏好对,从而消除手动注释。这实现了有效的偏好对齐,同时避免了扩展监督微调的过拟合问题。在涵盖医疗和金融领域的三个基准上进行评估,与基线方法相比,OptiLeak实现了每个token平均请求次数高达12.48倍的降低,并且在从3B到14B参数的模型规模上都具有一致的改进。我们的研究结果表明,基于缓存的提示泄露构成的威胁比之前报告的更为严重,突显了在生产部署中进行稳健的缓存隔离的必要性。
🔬 方法详解
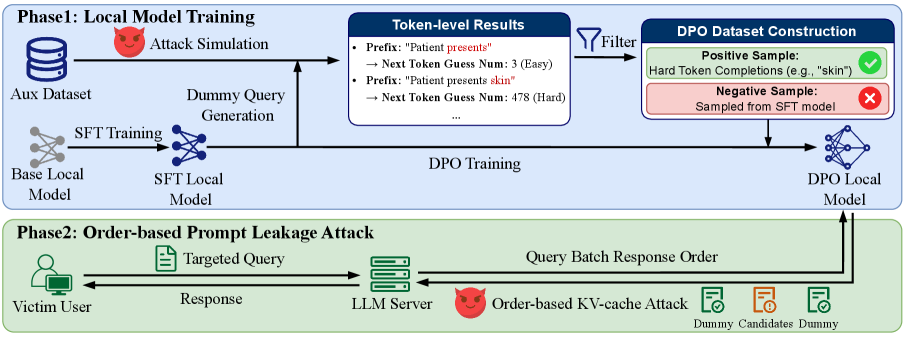
问题定义:论文旨在解决多租户LLM服务中,由于共享Key-Value缓存导致的提示泄露问题。现有攻击方法主要集中于扩展攻击向量,而忽略了攻击效率的优化,导致攻击成本过高,难以在实际场景中应用。因此,如何高效地重建泄露的提示信息,降低攻击成本,是本文要解决的核心问题。
核心思路:OptiLeak的核心思路是利用强化学习,通过两阶段微调来优化提示重建过程。首先,通过似然排序自动识别领域特定的“硬token”,这些token难以预测但携带关键信息。然后,利用这些“硬token”构建偏好对,用于直接偏好优化(DPO),从而引导模型学习更有效的提示重建策略。这种方法避免了手动标注偏好数据,并能有效对齐模型偏好。
技术框架:OptiLeak框架包含两个主要阶段:1) 硬token识别阶段:通过计算每个token的似然性,识别出领域内难以预测但包含重要信息的“硬token”。2) 强化学习微调阶段:利用识别出的硬token构建偏好对,使用直接偏好优化(DPO)算法对LLM进行微调,使其能够更有效地重建提示。整个流程无需人工标注,可以自动化进行。
关键创新:OptiLeak的关键创新在于:1) 提出了一种基于似然排序的硬token自动识别方法,无需人工标注即可获取高质量的偏好数据。2) 将强化学习中的直接偏好优化(DPO)应用于提示重建任务,实现了高效的偏好对齐,避免了传统监督微调的过拟合问题。3) 针对多租户LLM服务的侧信道攻击,提出了一个更高效的攻击框架,揭示了缓存泄露带来的更严重隐私风险。
关键设计:在硬token识别阶段,使用LLM对目标领域的数据进行预测,计算每个token的似然性,并根据似然性排序选择top-k个token作为硬token。在强化学习微调阶段,使用DPO算法,将原始提示和包含硬token的提示作为偏好对,训练LLM使其更倾向于生成包含硬token的提示。DPO的损失函数旨在最大化模型对更优提示的偏好概率,同时避免过度拟合。
🖼️ 关键图片


📊 实验亮点
OptiLeak在三个基准数据集(涵盖医疗和金融领域)上进行了评估,实验结果表明,与基线方法相比,OptiLeak实现了每个token平均请求次数高达12.48倍的降低。此外,OptiLeak在不同模型规模(3B到14B参数)上都表现出一致的性能提升,证明了其有效性和可扩展性。这些结果表明,缓存侧信道攻击的威胁比之前认为的更为严重。
🎯 应用场景
OptiLeak的研究成果可以应用于评估和增强多租户LLM服务的安全性。通过模拟缓存侧信道攻击,可以评估现有缓存机制的安全性,并为设计更安全的缓存隔离策略提供指导。此外,该方法还可以用于开发更有效的隐私保护技术,例如差分隐私和联邦学习,以保护用户数据的隐私。
📄 摘要(原文)
Multi-tenant LLM serving frameworks widely adopt shared Key-Value caches to enhance efficiency. However, this creates side-channel vulnerabilities enabling prompt leakage attacks. Prior studies identified these attack surfaces yet focused on expanding attack vectors rather than optimizing attack performance, reporting impractically high attack costs that underestimate the true privacy risk. We propose OptiLeak, a reinforcement learning-enhanced framework that maximizes prompt reconstruction efficiency through two-stage fine-tuning. Our key insight is that domain-specific ``hard tokens'' -- terms difficult to predict yet carrying sensitive information -- can be automatically identified via likelihood ranking and used to construct preference pairs for Direct Preference Optimization, eliminating manual annotation. This enables effective preference alignment while avoiding the overfitting issues of extended supervised fine-tuning. Evaluated on three benchmarks spanning medical and financial domains, OptiLeak achieves up to $12.48\times$ reduction in average requests per token compared to baseline approaches, with consistent improvements across model scales from 3B to 14B parameters. Our findings demonstrate that cache-based prompt leakage poses a more severe threat than previously reported, underscoring the need for robust cache isolation in production deployments.