CausalFlip: A Benchmark for LLM Causal Judgment Beyond Semantic Matching
作者: Yuzhe Wang, Yaochen Zhu, Jundong Li
分类: cs.AI
发布日期: 2026-02-23
备注: 8 pages plus references, 3 figures, 3 tables. Under review
💡 一句话要点
CausalFlip:提出因果判断基准,评估LLM在语义匹配之外的因果推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推理 大型语言模型 基准测试 语义匹配 思维链 内部化推理 因果判断 噪声前缀
📋 核心要点
- 现有LLM推理易受语义相关性误导,无法保证在高风险决策场景中的可靠性。
- CausalFlip基准通过构造语义相似但因果关系相反的问题对,挑战LLM的语义匹配能力。
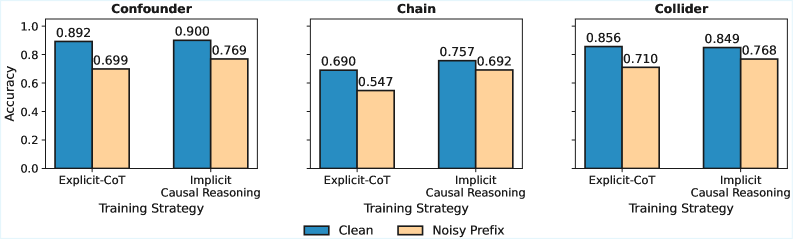
- 实验表明,内部化因果推理方法能有效提升LLM的因果判断能力,优于显式CoT。
📝 摘要(中文)
随着大型语言模型(LLMs)在复杂、高风险的决策场景中日益普及,确保其推理基于因果关系而非虚假相关性至关重要。然而,在传统推理基准上的出色表现并不能保证LLMs真正的因果推理能力,因为高准确率可能源于记忆语义模式而非分析潜在的真实因果结构。为了弥合这一关键差距,我们提出了一个新的因果推理基准CausalFlip,旨在鼓励开发新的LLM范式或训练算法,使LLM推理基于因果关系而非语义相关性。CausalFlip由基于事件三元组构建的因果判断问题组成,这些事件三元组可以形成不同的混淆因子、链和碰撞关系。在此基础上,对于每个事件三元组,我们构建了语义相似的问题对,这些问题对重用相同的事件但产生相反的因果答案,从而系统地将严重依赖语义匹配的模型推向不正确的预测。为了进一步探究模型对语义模式的依赖,我们引入了一种噪声前缀评估方法,在中间因果推理步骤之前添加因果无关的文本,而不改变潜在的因果关系或推理过程的逻辑。我们评估了多种训练范式下的LLMs,包括仅答案训练、显式思维链(CoT)监督以及一种旨在减轻对推理过程中相关性的显式依赖的内部化因果推理方法。我们的结果表明,显式CoT仍然可能被虚假的语义相关性所误导,而内部化推理步骤可以显著提高因果基础,这表明更好地激发基础LLMs的潜在因果推理能力是有希望的。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在因果推理方面存在不足。尽管它们在许多推理基准测试中表现出色,但这种性能可能仅仅是由于模型记忆了语义模式,而不是真正理解了因果关系。这导致LLMs在需要区分因果关系和虚假相关性的场景中容易出错,尤其是在高风险决策环境中。因此,需要一种新的方法来评估和提升LLMs的因果推理能力,使其能够基于真实的因果结构进行判断。
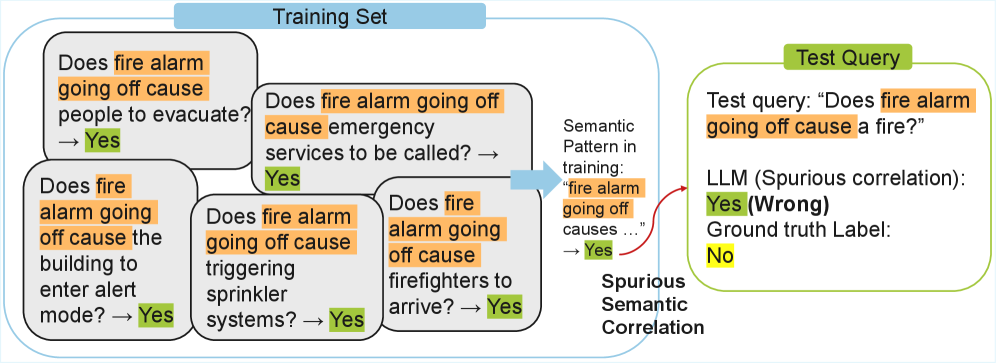
核心思路:CausalFlip的核心思路是创建一个基准测试,该测试能够区分LLMs是基于语义匹配还是真正的因果推理进行判断。通过构建语义相似但因果关系相反的问题对,CausalFlip可以有效地“欺骗”那些依赖语义匹配的模型,迫使它们做出错误的预测。这种设计旨在暴露LLMs对虚假相关性的依赖,并鼓励开发更强大的因果推理方法。
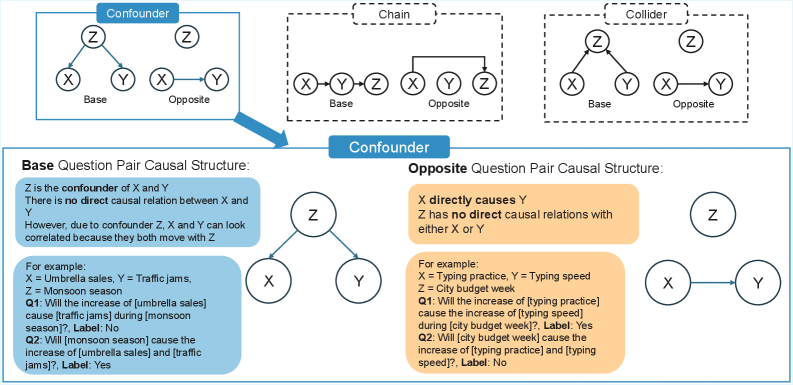
技术框架:CausalFlip基准测试由以下几个主要组成部分构成:1) 事件三元组构建:选择或生成包含三个事件的集合,这些事件之间可以构成不同的因果关系,如混淆因子、链和碰撞关系。2) 问题对生成:对于每个事件三元组,生成一对语义相似的问题,但这两个问题具有相反的因果答案。这两个问题使用相同的事件,但通过改变问题的措辞或上下文,使得正确的因果推断结果不同。3) 噪声前缀评估:在推理步骤之前添加因果无关的文本,以进一步测试模型对语义模式的依赖程度。4) 模型评估:使用不同的训练范式(如仅答案训练、显式CoT监督和内部化因果推理)训练LLMs,并在CausalFlip基准上评估它们的性能。
关键创新:CausalFlip的关键创新在于其问题对的设计,这些问题对具有语义相似性,但因果关系相反。这种设计能够有效地暴露LLMs对语义匹配的依赖,并促使模型学习真正的因果关系。此外,噪声前缀评估进一步增强了对模型语义依赖的测试。内部化因果推理方法也是一个创新点,它旨在减少模型对显式相关性的依赖,从而提高因果推理能力。
关键设计:CausalFlip的关键设计包括:1) 事件三元组的选择:选择具有明确因果关系的事件三元组,以确保问题对的因果答案是明确的。2) 问题对的语义相似性:确保问题对在语义上尽可能相似,以最大程度地减少语义匹配对模型性能的影响。3) 噪声前缀的长度和内容:选择适当长度和内容的噪声前缀,以干扰模型的语义匹配,同时不改变问题的因果关系。4) 内部化因果推理的实现:通过特定的训练策略,鼓励模型在内部进行因果推理,而不是依赖显式的思维链。
🖼️ 关键图片
📊 实验亮点
实验结果表明,显式思维链(CoT)方法容易被虚假的语义相关性误导。相比之下,内部化因果推理方法能够显著提高LLM的因果判断能力,表明其能够更好地利用潜在的因果推理能力。该方法在CausalFlip基准上取得了显著的性能提升,为未来的研究提供了新的方向。
🎯 应用场景
CausalFlip的研究成果可应用于提升LLM在医疗诊断、金融风险评估、自动驾驶等高风险决策场景中的可靠性。通过提高LLM的因果推理能力,可以减少因果谬误导致的错误决策,从而提高系统的安全性和效率。此外,该基准可以促进因果推理算法的开发,推动人工智能领域的发展。
📄 摘要(原文)
As large language models (LLMs) witness increasing deployment in complex, high-stakes decision-making scenarios, it becomes imperative to ground their reasoning in causality rather than spurious correlations. However, strong performance on traditional reasoning benchmarks does not guarantee true causal reasoning ability of LLMs, as high accuracy may still arise from memorizing semantic patterns instead of analyzing the underlying true causal structures. To bridge this critical gap, we propose a new causal reasoning benchmark, CausalFlip, designed to encourage the development of new LLM paradigm or training algorithms that ground LLM reasoning in causality rather than semantic correlation. CausalFlip consists of causal judgment questions built over event triples that could form different confounder, chain, and collider relations. Based on this, for each event triple, we construct pairs of semantically similar questions that reuse the same events but yield opposite causal answers, where models that rely heavily on semantic matching are systematically driven toward incorrect predictions. To further probe models' reliance on semantic patterns, we introduce a noisy-prefix evaluation that prepends causally irrelevant text before intermediate causal reasoning steps without altering the underlying causal relations or the logic of the reasoning process. We evaluate LLMs under multiple training paradigms, including answer-only training, explicit Chain-of-Thought (CoT) supervision, and a proposed internalized causal reasoning approach that aims to mitigate explicit reliance on correlation in the reasoning process. Our results show that explicit CoT can still be misled by spurious semantic correlations, where internalizing reasoning steps yields substantially improved causal grounding, suggesting that it is promising to better elicit the latent causal reasoning capabilities of base LLMs.