Meta-Learning and Meta-Reinforcement Learning - Tracing the Path towards DeepMind's Adaptive Agent
作者: Björn Hoppmann, Christoph Scholz
分类: cs.AI, cs.LG
发布日期: 2026-02-23
💡 一句话要点
综述元学习与元强化学习,追溯DeepMind自适应Agent的技术演进路径
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元学习 元强化学习 自适应Agent 迁移学习 小样本学习
📋 核心要点
- 传统机器学习模型在适应新任务时面临挑战,因为它们通常需要大量特定任务的数据进行训练,缺乏利用先验知识的能力。
- 元学习通过学习跨任务的可迁移知识,使模型能够快速适应新任务,仅需少量数据即可实现高效学习。
- 本综述系统地整理了元学习和元强化学习的关键算法,并追溯了DeepMind自适应Agent的技术发展历程。
📝 摘要(中文)
人类能够高效地利用先验知识来适应新任务,而标准的机器学习模型由于依赖于特定任务的训练,难以复制这种能力。元学习通过允许模型从各种任务中获取可迁移的知识来克服这一限制,从而能够以最少的数据快速适应新的挑战。本综述对元学习和元强化学习进行了严格的、基于任务的形式化,并以此范式记录了为DeepMind自适应Agent铺平道路的里程碑式算法,整合了理解自适应Agent和其他通用方法所需的基本概念。
🔬 方法详解
问题定义:现有机器学习模型在面对新任务时,通常需要从头开始训练,无法有效利用以往学习的经验。这导致了对大量标注数据的依赖,以及在新任务上的泛化能力不足。元学习旨在解决这一问题,使模型能够像人类一样,通过少量样本快速适应新任务。
核心思路:元学习的核心思想是“学会学习”。它不是直接学习解决特定任务,而是学习如何快速适应新任务。通过在多个相关任务上进行训练,模型能够学习到任务之间的共性,从而获得一种“元知识”,用于指导新任务的学习。
技术框架:元学习通常包含两个循环:内部循环和外部循环。内部循环负责在单个任务上进行学习,利用少量数据进行快速适应。外部循环则负责在多个任务上进行训练,更新模型的元参数,使其能够更好地适应新任务。常见的元学习框架包括基于模型的方法(如LSTM元学习器)、基于度量的方法(如孪生网络)和基于优化的方法(如Model-Agnostic Meta-Learning,MAML)。
关键创新:本综述的关键创新在于对元学习和元强化学习算法进行了系统性的整理和分类,并将其与DeepMind的自适应Agent联系起来,揭示了通用人工智能的发展路径。通过对里程碑式算法的回顾,该综述为理解自适应Agent和其他通用方法提供了必要的背景知识。
关键设计:不同的元学习算法在关键设计上有所不同。例如,MAML通过学习一个对任务初始化敏感的参数,使得在少量梯度更新后就能快速适应新任务。LSTM元学习器则利用LSTM网络来学习任务的更新规则。损失函数的设计也至关重要,通常需要考虑任务之间的相似性和差异性,以促进知识的迁移。
🖼️ 关键图片
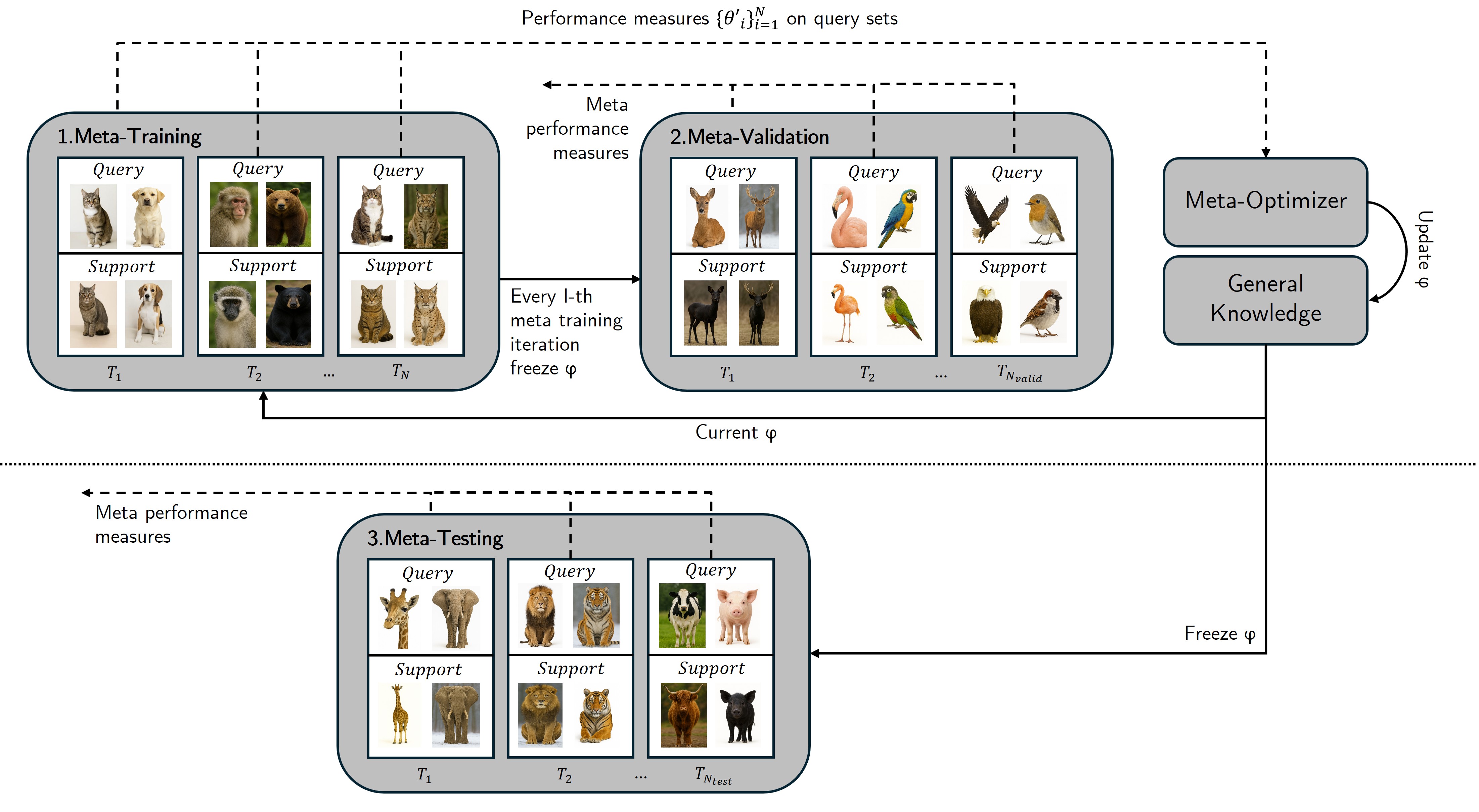
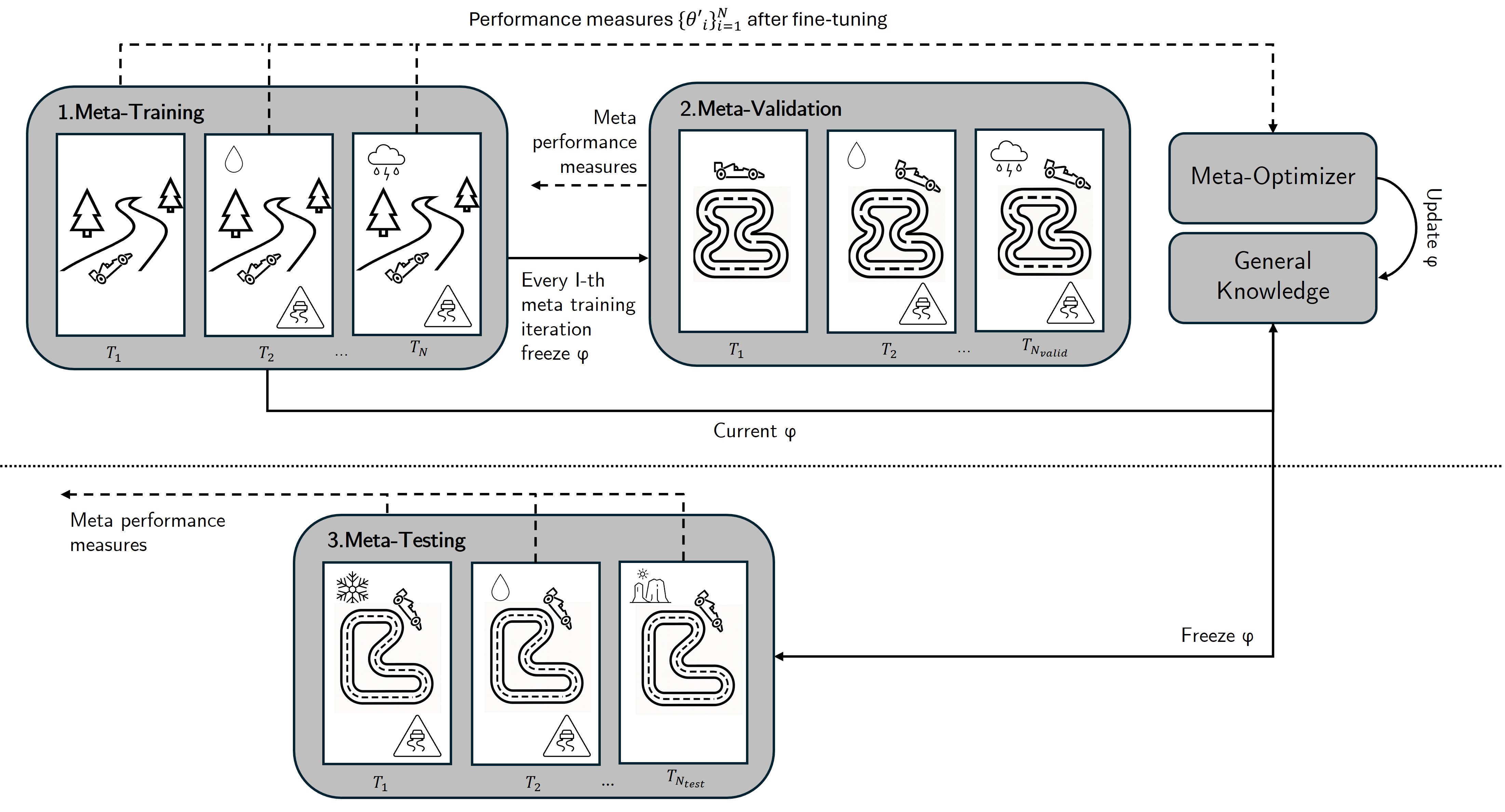
📊 实验亮点
该综述系统地回顾了元学习和元强化学习领域的重要算法,并将其与DeepMind的自适应Agent联系起来,为理解通用人工智能的发展提供了重要的视角。通过对不同算法的比较和分析,该综述揭示了元学习在解决数据稀缺和快速适应新任务方面的优势。
🎯 应用场景
元学习具有广泛的应用前景,包括机器人控制、图像识别、自然语言处理等领域。它可以用于解决数据稀缺问题,例如在医疗诊断中,罕见疾病的数据往往非常有限,元学习可以帮助模型利用其他相关疾病的数据进行学习。此外,元学习还可以用于个性化推荐,根据用户的历史行为快速适应其新的偏好。
📄 摘要(原文)
Humans are highly effective at utilizing prior knowledge to adapt to novel tasks, a capability that standard machine learning models struggle to replicate due to their reliance on task-specific training. Meta-learning overcomes this limitation by allowing models to acquire transferable knowledge from various tasks, enabling rapid adaptation to new challenges with minimal data. This survey provides a rigorous, task-based formalization of meta-learning and meta-reinforcement learning and uses that paradigm to chronicle the landmark algorithms that paved the way for DeepMind's Adaptive Agent, consolidating the essential concepts needed to understand the Adaptive Agent and other generalist approaches.