Tri-Subspaces Disentanglement for Multimodal Sentiment Analysis
作者: Chunlei Meng, Jiabin Luo, Zhenglin Yan, Zhenyu Yu, Rong Fu, Zhongxue Gan, Chun Ouyang
分类: cs.MM, cs.AI
发布日期: 2026-02-23
备注: This study has been Accepted by CVPR 2026
💡 一句话要点
提出Tri-Subspace Disentanglement框架,解决多模态情感分析中模态间信息融合不充分的问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 跨模态融合 特征解耦 子空间学习 注意力机制
📋 核心要点
- 现有MSA方法忽略了模态对之间的共享信息,导致多模态表示的表达能力受限。
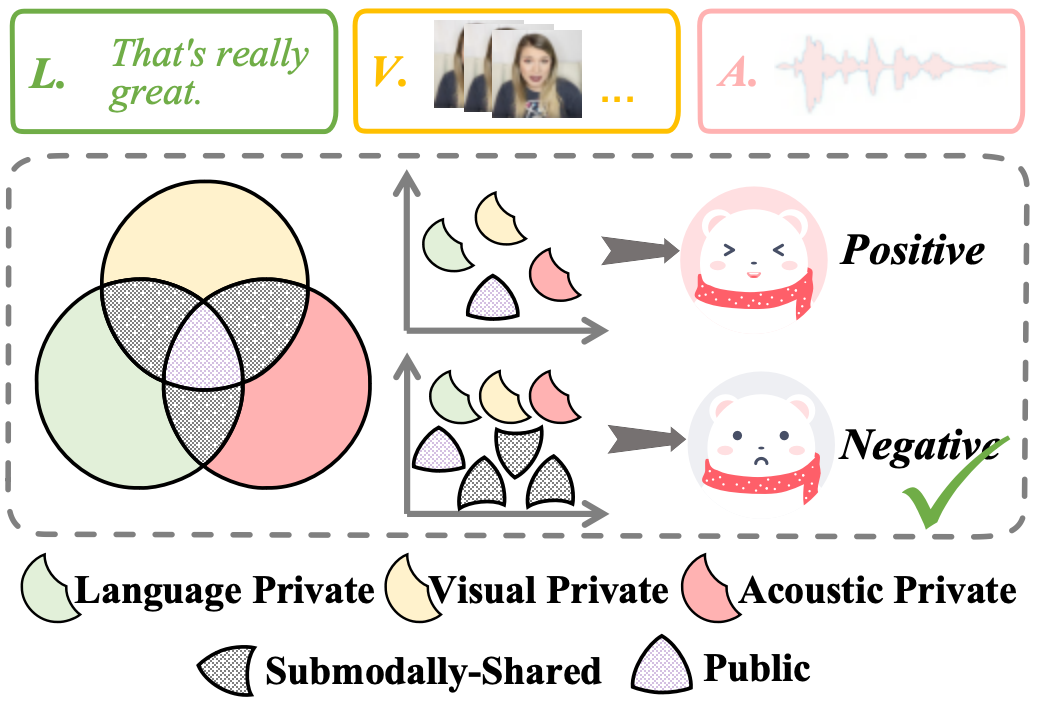
- 提出Tri-Subspace Disentanglement框架,将特征解耦为公共、子模态共享和私有三个子空间。
- 实验表明,该方法在CMU-MOSI和CMU-MOSEI数据集上取得了SOTA性能,并具有良好的迁移性。
📝 摘要(中文)
多模态情感分析(MSA)整合语言、视觉和听觉模态来推断人类情感。现有方法主要关注全局共享表示或模态特定特征,忽略了仅由某些模态对共享的信号,限制了多模态表示的表达能力和判别能力。为解决此问题,我们提出了一种Tri-Subspace Disentanglement (TSD)框架,将特征显式分解为三个互补的子空间:捕获全局一致性的公共子空间、建模成对跨模态协同作用的子模态共享子空间,以及保留模态特定线索的私有子空间。为了保持这些子空间的纯粹性和独立性,我们引入了解耦监督器以及结构化正则化损失。我们进一步设计了一个Subspace-Aware Cross-Attention (SACA)融合模块,自适应地建模和整合来自三个子空间的信息,以获得更丰富和更鲁棒的表示。在CMU-MOSI和CMU-MOSEI上的实验表明,TSD在所有关键指标上都达到了最先进的性能,在CMU-MOSI上达到0.691 MAE,在CMU-MOSEI上达到54.9% ACC-7,并且可以很好地迁移到多模态意图识别任务。消融研究证实,三子空间解耦和SACA共同增强了多粒度跨模态情感线索的建模。
🔬 方法详解
问题定义:多模态情感分析旨在融合来自不同模态(如文本、视觉、听觉)的信息,以准确判断情感。现有方法主要集中于学习全局共享的模态表示或模态特定的特征,忽略了某些模态对之间存在的共享信息,导致跨模态信息的融合不充分,限制了模型性能。
核心思路:论文的核心思路是将多模态特征解耦为三个互补的子空间:公共子空间、子模态共享子空间和私有子空间。公共子空间捕获所有模态的全局一致性信息;子模态共享子空间建模模态对之间的协同作用;私有子空间保留每个模态的独特信息。通过这种解耦,模型可以更全面地捕捉多模态数据中的各种情感线索。
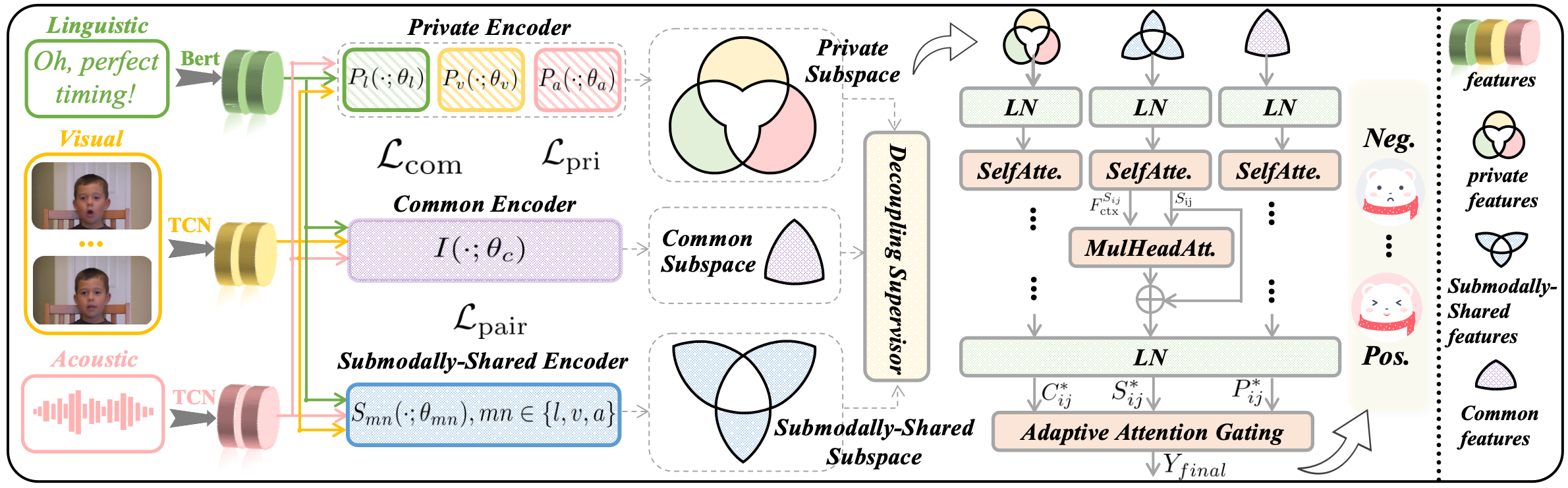
技术框架:TSD框架主要包含三个部分:特征解耦模块、解耦监督模块和Subspace-Aware Cross-Attention (SACA)融合模块。首先,特征解耦模块将多模态特征分解为三个子空间。然后,解耦监督模块通过解耦监督器和结构化正则化损失来保证子空间的纯粹性和独立性。最后,SACA融合模块自适应地整合来自三个子空间的信息,生成最终的多模态情感表示。
关键创新:该论文的关键创新在于提出了Tri-Subspace Disentanglement框架,显式地建模了模态间的多种关系(全局共享、成对共享、模态私有)。与现有方法相比,TSD能够更全面地捕捉多模态数据中的情感信息,从而提升情感分析的准确性。
关键设计:论文设计了解耦监督器,用于约束不同子空间之间的相关性,保证子空间的独立性。此外,论文还设计了结构化正则化损失,用于约束子空间的特征分布,提高子空间的纯粹性。SACA融合模块使用注意力机制,自适应地学习不同子空间的重要性,从而实现更有效的跨模态信息融合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TSD框架在CMU-MOSI和CMU-MOSEI数据集上取得了显著的性能提升。在CMU-MOSI数据集上,TSD的MAE达到了0.691,在CMU-MOSEI数据集上,TSD的ACC-7达到了54.9%,均优于现有SOTA方法。消融实验验证了三子空间解耦和SACA融合模块的有效性。
🎯 应用场景
该研究成果可应用于情感分析、人机交互、智能客服、舆情监控等领域。通过更准确地理解人类情感,可以提升用户体验,优化产品设计,并为决策提供更可靠的依据。未来,该方法可以扩展到更多模态和更复杂的场景,例如视频情感分析、社交媒体情感分析等。
📄 摘要(原文)
Multimodal Sentiment Analysis (MSA) integrates language, visual, and acoustic modalities to infer human sentiment. Most existing methods either focus on globally shared representations or modality-specific features, while overlooking signals that are shared only by certain modality pairs. This limits the expressiveness and discriminative power of multimodal representations. To address this limitation, we propose a Tri-Subspace Disentanglement (TSD) framework that explicitly factorizes features into three complementary subspaces: a common subspace capturing global consistency, submodally-shared subspaces modeling pairwise cross-modal synergies, and private subspaces preserving modality-specific cues. To keep these subspaces pure and independent, we introduce a decoupling supervisor together with structured regularization losses. We further design a Subspace-Aware Cross-Attention (SACA) fusion module that adaptively models and integrates information from the three subspaces to obtain richer and more robust representations. Experiments on CMU-MOSI and CMU-MOSEI demonstrate that TSD achieves state-of-the-art performance across all key metrics, reaching 0.691 MAE on CMU-MOSI and 54.9% ACC-7 on CMU-MOSEI, and also transfers well to multimodal intent recognition tasks. Ablation studies confirm that tri-subspace disentanglement and SACA jointly enhance the modeling of multi-granular cross-modal sentiment cues.