A Multimodal Framework for Aligning Human Linguistic Descriptions with Visual Perceptual Data
作者: Joseph Bingham
分类: cs.AI, cs.CV
发布日期: 2026-02-23
备注: 19 Pages, 6 figures, preprint
💡 一句话要点
提出多模态框架,对齐人类语言描述与视觉感知数据,解决跨模态参照理解问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 参照理解 视觉感知 自然语言处理 人机交互
📋 核心要点
- 现有方法在处理自然语言和视觉感知之间的映射关系时,难以应对感知环境的噪声和模糊性。
- 该论文提出一种多模态框架,通过整合语言表达和视觉表征,模拟人类参照解释过程,实现跨模态对齐。
- 实验结果表明,该框架在参照理解任务中表现出色,所需话语更少,目标对象识别准确率高于人类。
📝 摘要(中文)
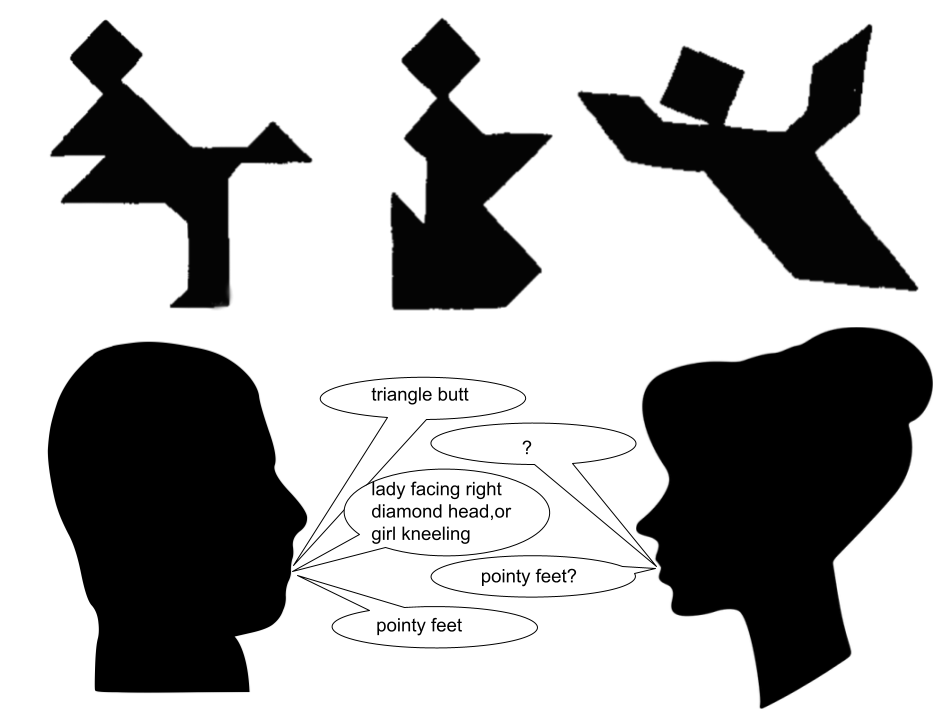
建立自然语言表达和视觉感知之间稳定的映射关系是认知科学和人工智能的基础问题。人类通常能在嘈杂、模糊的感知环境中进行语言参照,但支持这种跨模态对齐的机制仍然知之甚少。本文介绍了一个计算框架,旨在通过整合语言表达和从大规模众包图像中提取的感知表征来模拟人类参照解释的核心方面。该系统通过结合尺度不变特征变换(SIFT)对齐和通用质量指标(UQI)来量化认知上合理的特征空间中的相似性,从而近似人类的感知分类,同时一组语言预处理和查询转换操作捕获了指称表达中的语用变异性。我们在斯坦福重复参照游戏语料库(15,000个话语与七巧板刺激配对)上评估了该模型,该范例明确旨在探测人类水平的感知模糊性和协调性。我们的框架实现了强大的参照基础。它比人类对话者需要少65%的话语才能达到稳定的映射,并且可以从单个指称表达中正确识别目标对象,准确率为41.66%(而人类为20%)。这些结果表明,相对简单的感知-语言对齐机制可以在经典的认知基准上产生与人类竞争的行为,并为扎根的交流、感知推理和跨模态概念形成的模型提供见解。
🔬 方法详解
问题定义:论文旨在解决自然语言描述与视觉感知数据对齐的问题,即如何让机器理解人类通过语言描述的视觉对象。现有方法难以有效处理真实世界中视觉感知的噪声和模糊性,以及语言表达的多样性和语用性。
核心思路:论文的核心思路是将语言信息和视觉信息进行有效整合,通过模拟人类的认知过程,建立语言表达和视觉感知之间的稳定映射关系。该方法结合了视觉特征提取、相似度计算和语言处理技术,以实现鲁棒的参照理解。
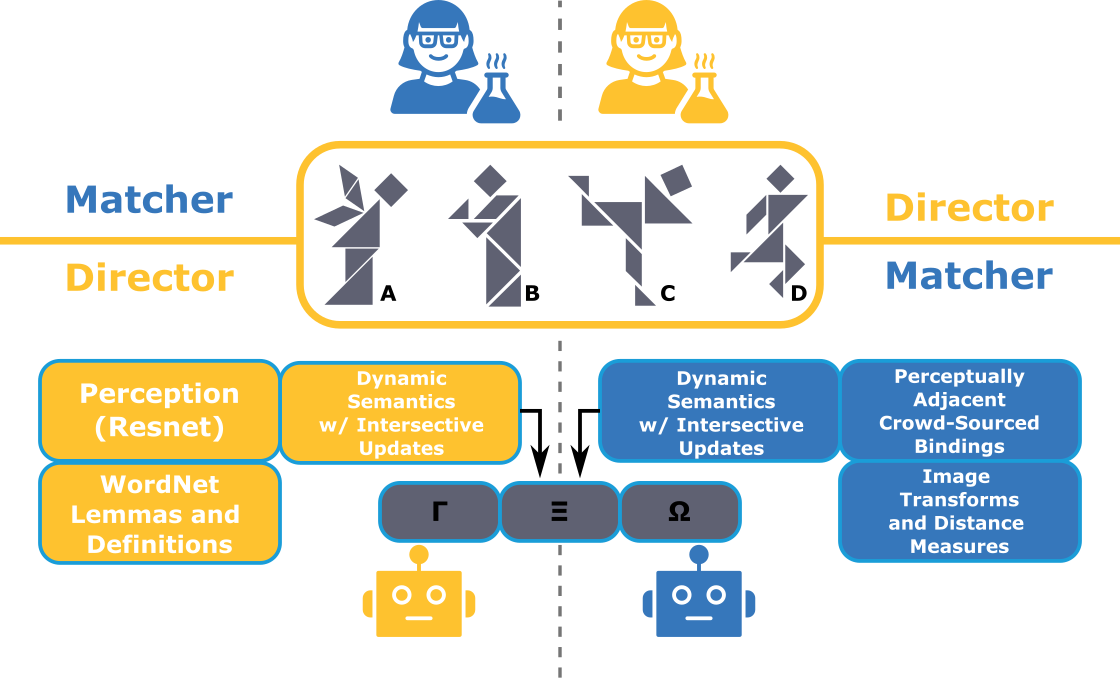
技术框架:该框架包含以下主要模块:1) 视觉感知模块:使用SIFT特征提取器从图像中提取视觉特征,并使用UQI指标计算图像之间的相似度。2) 语言处理模块:对语言表达进行预处理和查询转换,以捕获指称表达中的语用变异性。3) 对齐模块:将视觉特征和语言表达进行对齐,建立语言描述和视觉对象之间的映射关系。整个流程旨在模拟人类在理解语言指称时的认知过程。
关键创新:该论文的关键创新在于将SIFT特征和UQI指标结合,用于量化认知上合理的特征空间中的相似性,从而更准确地模拟人类的感知分类。此外,该框架还考虑了语言表达的语用变异性,通过语言预处理和查询转换来提高参照理解的鲁棒性。
关键设计:SIFT特征提取器的参数设置遵循标准配置。UQI指标用于计算图像之间的相似度,其计算公式基于图像的均值、方差和协方差。语言预处理包括词干提取、停用词移除等操作。查询转换操作旨在将语言表达转换为更适合与视觉特征进行匹配的形式。损失函数未知。
🖼️ 关键图片

📊 实验亮点
该框架在斯坦福重复参照游戏语料库上进行了评估,结果表明,该框架比人类对话者需要少65%的话语才能达到稳定的映射,并且可以从单个指称表达中正确识别目标对象,准确率为41.66%,而人类为20%。这些结果表明,该框架在参照理解任务中表现出色,具有与人类竞争的能力。
🎯 应用场景
该研究成果可应用于人机交互、智能助手、图像检索、机器人导航等领域。通过提高机器对自然语言指令的理解能力,可以实现更自然、更智能的人机交互体验。例如,用户可以通过语音或文本描述来控制机器人完成特定任务,或者通过语言描述来搜索图像。
📄 摘要(原文)
Establishing stable mappings between natural language expressions and visual percepts is a foundational problem for both cognitive science and artificial intelligence. Humans routinely ground linguistic reference in noisy, ambiguous perceptual contexts, yet the mechanisms supporting such cross-modal alignment remain poorly understood. In this work, we introduce a computational framework designed to model core aspects of human referential interpretation by integrating linguistic utterances with perceptual representations derived from large-scale, crowd-sourced imagery. The system approximates human perceptual categorization by combining scale-invariant feature transform (SIFT) alignment with the Universal Quality Index (UQI) to quantify similarity in a cognitively plausible feature space, while a set of linguistic preprocessing and query-transformation operations captures pragmatic variability in referring expressions. We evaluate the model on the Stanford Repeated Reference Game corpus (15,000 utterances paired with tangram stimuli), a paradigm explicitly developed to probe human-level perceptual ambiguity and coordination. Our framework achieves robust referential grounding. It requires 65\% fewer utterances than human interlocutors to reach stable mappings and can correctly identify target objects from single referring expressions 41.66\% of the time (versus 20\% for humans).These results suggest that relatively simple perceptual-linguistic alignment mechanisms can yield human-competitive behavior on a classic cognitive benchmark, and offers insights into models of grounded communication, perceptual inference, and cross-modal concept formation. Code is available at https://anonymous.4open.science/r/metasequoia-9D13/README.md .