Ada-RS: Adaptive Rejection Sampling for Selective Thinking
作者: Yirou Ge, Yixi Li, Alec Chiu, Shivani Shekhar, Zijie Pan, Avinash Thangali, Yun-Shiuan Chuang, Chaitanya Kulkarni, Uma Kona, Linsey Pang, Prakhar Mehrotra
分类: cs.AI, cs.LG
发布日期: 2026-02-23
💡 一句话要点
Ada-RS:自适应拒绝采样提升工具型LLM选择性推理效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 选择性推理 自适应拒绝采样 工具调用 效率优化
📋 核心要点
- 现有思维链方法在简单请求上浪费tokens,降低了LLM在成本敏感场景下的效率。
- Ada-RS通过自适应长度惩罚奖励和拒绝采样,过滤低价值的LLM补全,提升推理效率。
- 实验表明,Ada-RS显著减少了输出tokens和思考率,同时保持或提升了工具调用准确性。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地部署在对成本和延迟敏感的环境中。虽然思维链(chain-of-thought)可以提高推理能力,但它可能会在简单的请求上浪费tokens。本文研究了工具型LLM的选择性思考,并引入了自适应拒绝采样(Ada-RS),这是一种与算法无关的采样过滤框架,用于学习选择性和高效的推理。对于每个给定的上下文,Ada-RS使用自适应的长度惩罚奖励对多个采样的补全进行评分,然后应用随机拒绝采样,仅保留高奖励的候选对象(或偏好对)以进行下游优化。我们展示了Ada-RS如何插入到偏好对(例如DPO)或分组策略优化策略(例如DAPO)中。在使用LoRA的Qwen3-8B在合成的面向工具调用的电子商务基准测试中,Ada-RS通过将平均输出tokens减少高达80%,并将思考率降低高达95%,同时保持或提高工具调用准确性,从而改善了标准算法的准确性-效率边界。这些结果表明,训练信号选择是延迟敏感型部署中有效推理的强大杠杆。
🔬 方法详解
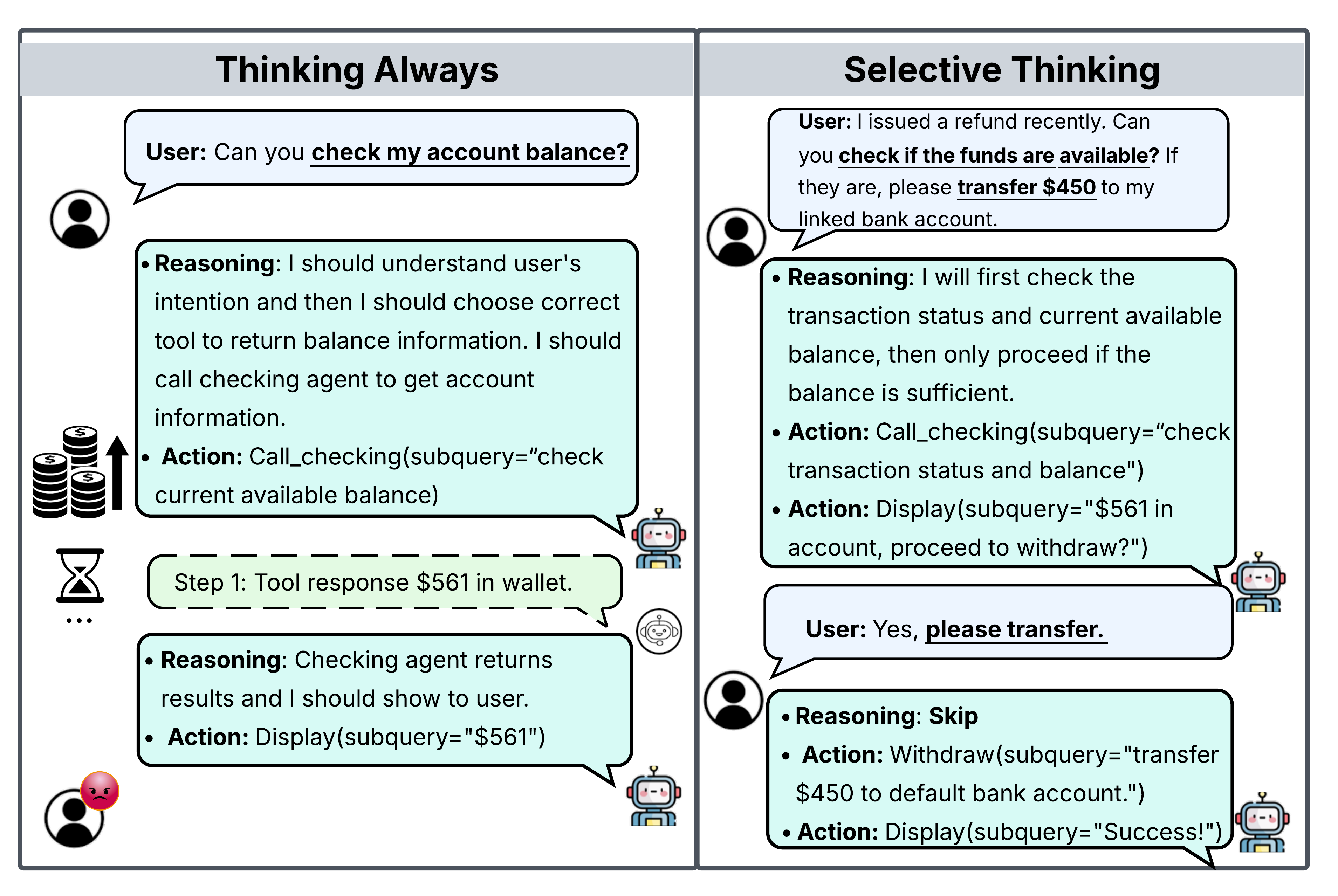
问题定义:论文旨在解决工具型大型语言模型(LLMs)在实际应用中,尤其是在成本和延迟敏感的场景下,推理效率低下的问题。现有的思维链(Chain-of-Thought, CoT)方法虽然能提升推理能力,但对于简单的任务也会产生冗余的tokens,造成不必要的计算开销和延迟。因此,如何让LLM能够根据任务的复杂程度进行选择性思考,避免在简单任务上过度推理,是本文要解决的核心问题。
核心思路:论文的核心思路是引入自适应拒绝采样(Adaptive Rejection Sampling, Ada-RS)框架,对LLM生成的多个候选补全进行过滤,只保留高质量的补全用于后续的优化。Ada-RS通过一个自适应的长度惩罚奖励函数来评估每个补全的质量,并使用随机拒绝采样方法来选择最终的输出。这种方法允许LLM根据上下文自适应地调整思考的深度,从而在保证准确性的前提下,显著降低计算成本和延迟。
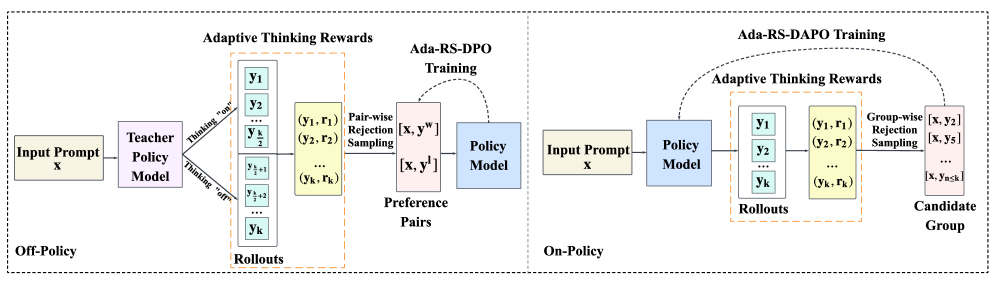
技术框架:Ada-RS框架主要包含以下几个阶段:1) 采样:对于给定的上下文,LLM生成多个候选补全。2) 奖励计算:使用自适应长度惩罚奖励函数对每个补全进行评分。该奖励函数旨在平衡准确性和效率,对过长的补全进行惩罚。3) 拒绝采样:根据每个补全的奖励值,使用随机拒绝采样方法选择最终的输出。奖励值越高的补全被保留的概率越高。4) 优化:将选择出的高质量补全用于下游的策略优化,例如直接偏好优化(Direct Preference Optimization, DPO)或分组策略优化(Grouped Policy Optimization, DAPO)。
关键创新:Ada-RS的关键创新在于其自适应的奖励函数和拒绝采样机制。传统的奖励函数通常是固定的,无法根据上下文进行调整。Ada-RS的奖励函数可以根据任务的复杂程度和LLM的性能进行自适应调整,从而更好地平衡准确性和效率。拒绝采样机制则提供了一种有效的过滤方法,可以去除低质量的补全,只保留高质量的样本用于后续的优化。
关键设计:Ada-RS的关键设计包括:1) 自适应长度惩罚奖励函数:该函数的设计需要仔细考虑长度惩罚的力度,以避免过度惩罚有价值的长序列。具体实现中,可以使用一个可学习的参数来控制长度惩罚的强度。2) 拒绝采样策略:拒绝采样的概率分布需要根据奖励值进行调整,以保证高质量的补全能够被保留。可以使用softmax函数将奖励值转换为概率分布。3) 与现有优化算法的集成:Ada-RS可以与多种策略优化算法集成,例如DPO和DAPO。在集成时,需要将Ada-RS的输出作为优化算法的输入,并调整优化算法的参数以适应Ada-RS的特性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在合成的面向工具调用的电子商务基准测试中,使用LoRA的Qwen3-8B模型,Ada-RS可以将平均输出tokens减少高达80%,并将思考率降低高达95%,同时保持或提高工具调用准确性。与标准算法相比,Ada-RS显著改善了准确性-效率边界,证明了训练信号选择在提高LLM推理效率方面的有效性。
🎯 应用场景
Ada-RS具有广泛的应用前景,尤其是在对成本和延迟敏感的场景中,例如在线客服、智能助手、电子商务等。通过减少LLM的计算开销和延迟,Ada-RS可以提高用户体验,降低运营成本。此外,Ada-RS还可以应用于资源受限的设备上,例如移动设备和嵌入式系统,使得这些设备也能运行复杂的LLM应用。未来,Ada-RS有望成为一种通用的LLM推理加速技术,推动LLM在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) are increasingly being deployed in cost and latency-sensitive settings. While chain-of-thought improves reasoning, it can waste tokens on simple requests. We study selective thinking for tool-using LLMs and introduce Adaptive Rejection Sampling (Ada-RS), an algorithm-agnostic sample filtering framework for learning selective and efficient reasoning. For each given context, Ada-RS scores multiple sampled completions with an adaptive length-penalized reward then applies stochastic rejection sampling to retain only high-reward candidates (or preference pairs) for downstream optimization. We demonstrate how Ada-RS plugs into both preference pair (e.g. DPO) or grouped policy optimization strategies (e.g. DAPO). Using Qwen3-8B with LoRA on a synthetic tool call-oriented e-commerce benchmark, Ada-RS improves the accuracy-efficiency frontier over standard algorithms by reducing average output tokens by up to 80% and reducing thinking rate by up to 95% while maintaining or improving tool call accuracy. These results highlight that training-signal selection is a powerful lever for efficient reasoning in latency-sensitive deployments.